
上次介绍了音频编 / 解码器的基本原理。相信已经对编 / 解码器有了一个整体的了解。其实编 / 解码器中的算法链路还是比较复杂的,自己从头开始设计和调试一个编 / 解码器的研发成本也是非常巨大的。所以我们一般会选择已有的编 / 解码器来使用。
而音频编 / 解码器经过几十年的发展,其实已经有很多成熟的解决方案可以选择。而且不同的场景对实时音频也有不同的要求。比如,音乐场景要求有比较高的采样率;合唱场景则需要比较低的延迟等。那具体根据什么标准来选择编解码器呢?今天就来介绍一下。
先来看看编 / 解码器选择时需要重点看哪些指标,然后从几个应用场景的角度看看如何挑选编 / 解码器以及如何选择合适的码率来达到我们想要的效果。
音频编 / 解码中常见的指标
音频编 / 解码器需要关注的指标主要包括码率、音质、计算复杂度和延迟这 4 个大项。

讯享网
码率与音质音频编 / 解码最直观的目的就是节省传输带宽。所以第一个要关注的指标就是码率。现在比较常用的编 / 解码器,比如 OPUS、EVS 等,都是支持不同码率传输的。而不同的码率一般会对应要关注的第二项指标音质。之前介绍过音频质量评估,音质可以用主观评测试验,也可以用 PESQ、POLQA 等客观评测方法来对主观听感进行打分。当然也可以从一些直接的音频指标,比如采样率、采样位深、通道数等来大致衡量音频质量的好坏。
计算复杂度
除了码率和音质,我们下一个要关心的是编 / 解码器的计算复杂度。音频的编码和解码都需要一定的算力支持。你可以回想一下我们之前讲的编 / 解码器的原理,其实大部分常用的编 / 解码器解码的计算力会比编码端的计算力要小很多。一般,我们在多人实时音频互动的时候,其实一个设备需要做自己这一路的编码和多路的解码。所以在看某个音频编 / 解码是否可用的时候,我们至少需要看看我们的设备是否可以支持实时一路编码和实时多路解码。

测试方法也比较简单,就是看看在你需要同时互动的最大数量的情况下,终端播放出来的声音是否会出现卡顿或者无声的情况。
这里从经验上来说,目前移动端的硬件设备,比如说笔记本电脑或者手机,常见的编 / 解码的计算复杂度一般都是可以支持的。但有一些定制化的 IOT 设备或者后台还有其它应用,在同时运行的时候,我们可能需要关注或者测试一下编 / 解码器是否支持你的应用场景。
延迟
在实时音频互动中还有一个需要注意的指标就是延迟。延迟主要包括两个部分:
一个是编 / 解码器算法引入的延迟,比如,编码时依赖未来帧的信息对当前帧进行编码;
另一个是网络发送时组包的延迟,比如,把 4 帧作为一个包来发送,那么延迟就会增加 4 帧的时长。而其实我们在音频互动中一般会比较关心一个音频“端到端”的延迟是多少。这里说的端到端,就是从你说的话被麦克风采集传到对端的设备,并从扬声器里播放出来的延迟。这个端到端的延迟包括了设备采集播放的延迟、音频处理算法引入的延迟、编 / 解码引入的延迟和网络传输的延迟。
这里分享一些经验:
一般来说“端到端”的延迟如果超过 200ms,人就可以开始感受到音频通话和面对面说话之间的差异。
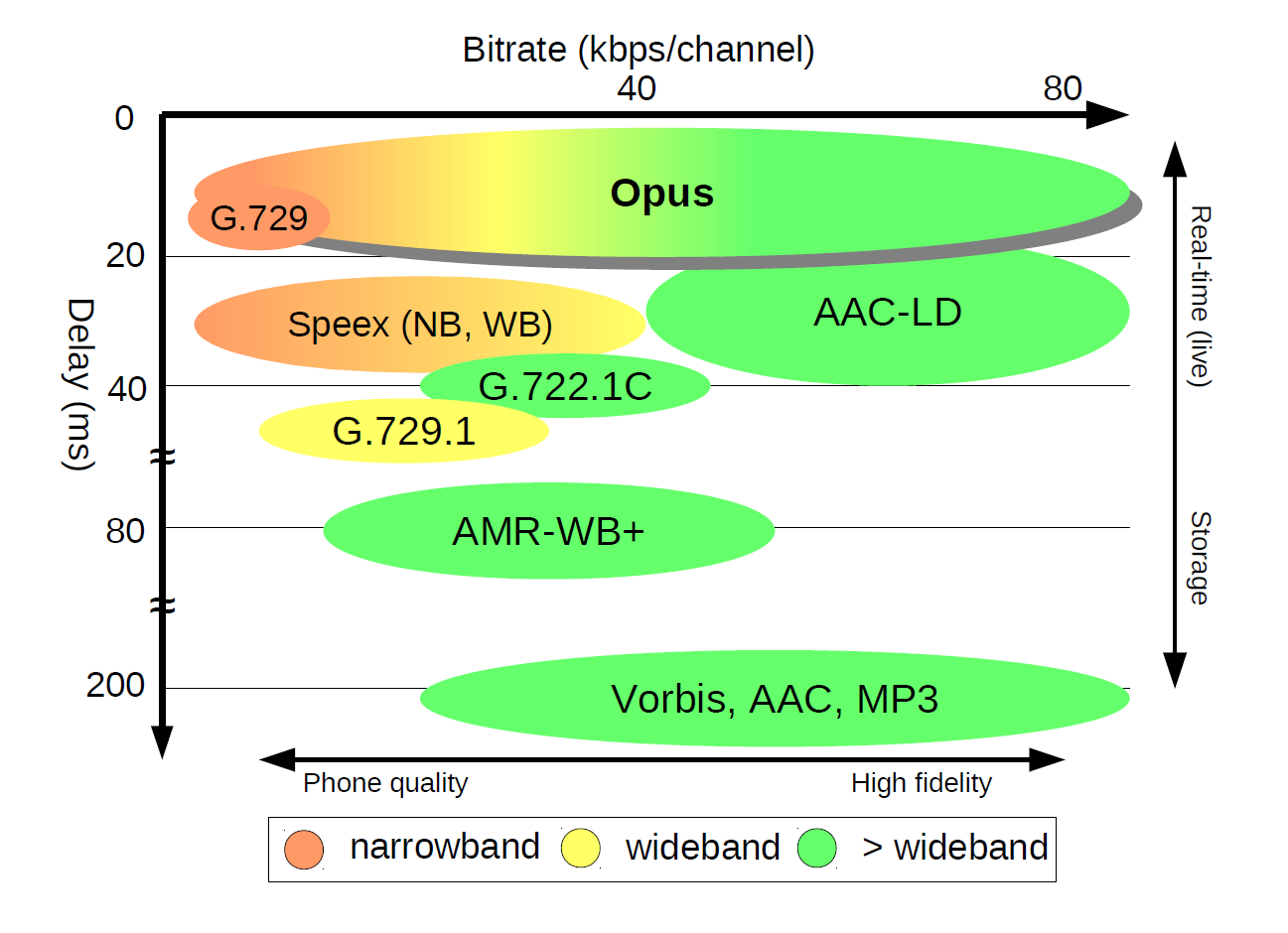
而如果延迟超过 400ms,那么你可以明显感受到,对面的反映有一种慢半拍的感觉。也就是你说了一句话,对面需要反映一会儿才会给你回应。所以在音质、码率等指标都合适的情况下,如果是需要音频互动的场景,一般会选择延迟比较低的编 / 解码器。可以通过图 2 来看一下不同编 / 解码器的性能差别。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/68391.html