
compact行格式
额外消息记录
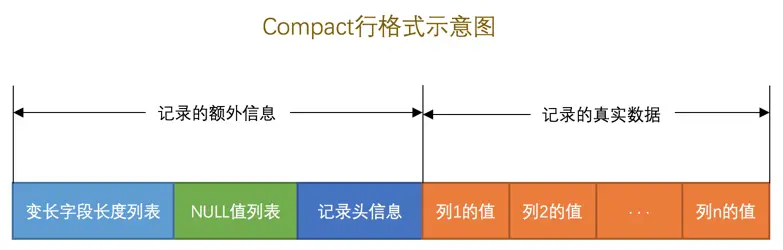
1.变长字段长度列表
列用的字符集是ascii,所以每个字符占一个字节
| 列名 | 存储内容 | 内容长度(十进制表示) | 内容长度(十六进制表示) |
|---|---|---|---|
c1 |
'aaaa' |
4 |
0x04 |
c2 |
'bbb' |
3 |
0x03 |
c4 |
'd' |
1 |
0x01 |
- 逆向存放 01 03 04
- 存储变长数据字节或不定字符集数据字节(utf8的字节为1-3是不确定的)
假设某个字符集中表示一个字符最多需要使用的字节数为W对于变长类型VARCHAR(M)来说,这种类型表示能存储最多M个字符(注意是字符不是字节),所以这个类型能表示的字符串最多占用的字节数就是M×W
if M×W <= 255:使用1个字节来表示真正字符串占用的字节数;
else M×W > 255:
L为实际数据占用的字节
- 如果
L <= 127,则用1个字节来表示真正字符串占用的字节数。 - 如果
L > 127,则用2个字节来表示真正字符串占用的字节数。
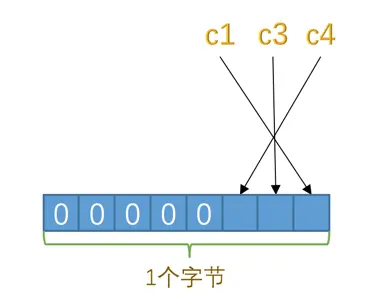
2.NULL值列表
- 逆序
- 二进制位的值为
1时,代表该列的值为NULL;二进制位的值为0时,代表该列的值不为NULL。 - 一个字节起步,若只有3个值则补零
3.记录头信息
| 名称 | 大小(单位:bit) | 描述 |
|---|---|---|
预留位1 |
1 |
没有使用 |
预留位2 |
1 |
没有使用 |
delete_mask |
1 |
标记该记录是否被删除 |
min_rec_mask |
1 |
B+树的每层非叶子节点中的最小记录都会添加该标记(非数据页) |
n_owned |
4 |
表示当前记录(组)拥有的记录数 |
heap_no |
13 |
表示当前记录在记录堆的位置信息 |
record_type |
3 |
表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录 |
next_record |
16 |
表示下一条记录的相对位置 |
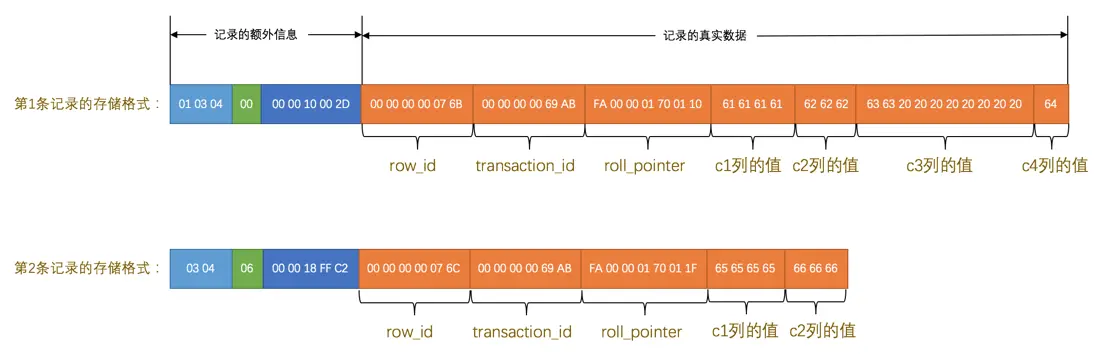
记录的真实数据
MySQL会为每个记录默认的添加一些列(也称为隐藏列),具体的列如下:
| 列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
row_id |
否 | 6字节 |
行ID,唯一标识一条记录(如果设置了主键或唯一数据列则该列不会生成) |
transaction_id |
是 | 6字节 |
事务ID |
roll_pointer |
是 | 7字节 |
回滚指针 |
Redundant行格式
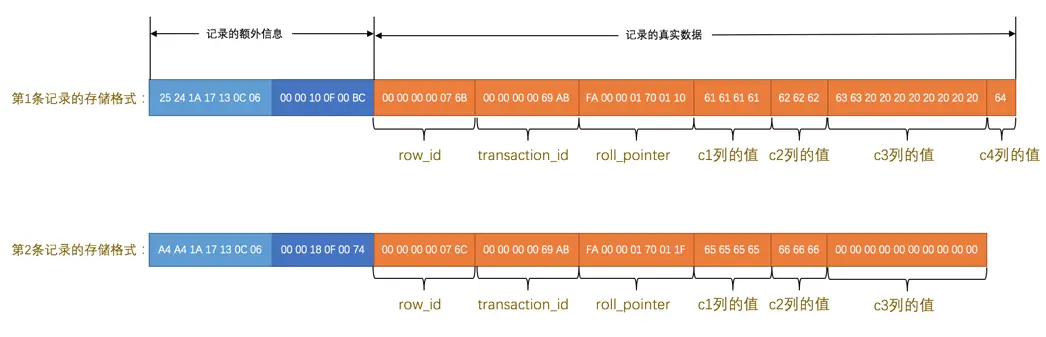
第一列(`row_id`)的长度就是 0x06个字节,也就是6个字节。 第二列(`transaction_id`)的长度就是 (0x0C - 0x06)个字节,也就是6个字节。 第三列(`roll_pointer`)的长度就是 (0x13 - 0x0C)个字节,也就是7个字节。 第四列(`c1`)的长度就是 (0x17 - 0x13)个字节,也就是4个字节。 第五列(`c2`)的长度就是 (0x1A - 0x17)个字节,也就是3个字节。 第六列(`c3`)的长度就是 (0x24 - 0x1A)个字节,也就是10个字节。 第七列(`c4`)的长度就是 (0x25 - 0x24)个字节,也就是1个字节。 讯享网
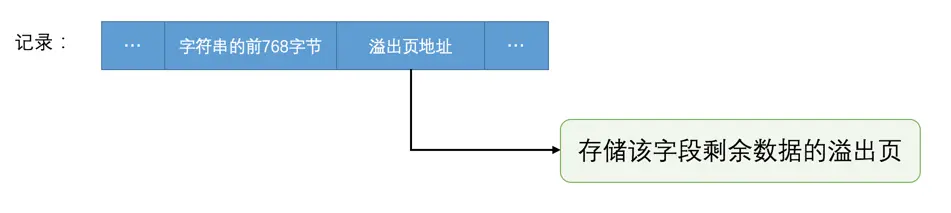
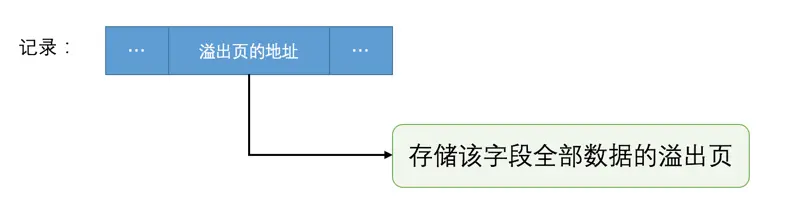
行溢出数据
我们为了存储一个VARCHAR(M)类型的列,其实需要占用3部分存储空间:
- 真实数据
- 真实数据占用字节的长度
NULL值标识,如果该列有NOT NULL属性则可以没有这部分存储空间
如果该VARCHAR类型的列没有NOT NULL属性,那最多只能存储65532个字节的数据,因为真实数据的长度可能占用2个字节,NULL值标识需要占用1个字节
如果VARCHAR(M)类型的列使用的不是ascii字符集,那M的最大取值取决于该字符集表示一个字符最多需要的字节数。在列的值允许为NULL的情况下,gbk字符集表示一个字符最多需要2个字节,那在该字符集下,M的最大取值就是32766(也就是:65532/2),也就是说最多能存储32766个字符;utf8字符集表示一个字符最多需要3个字节,那在该字符集下,M的最大取值就是21844,就是说最多能存储21844(也就是:65532/3)个字符。
compact行格式

Dynamic和Compressed(压缩算法对页面压缩)行格式
数据页
页的大小都为16kb
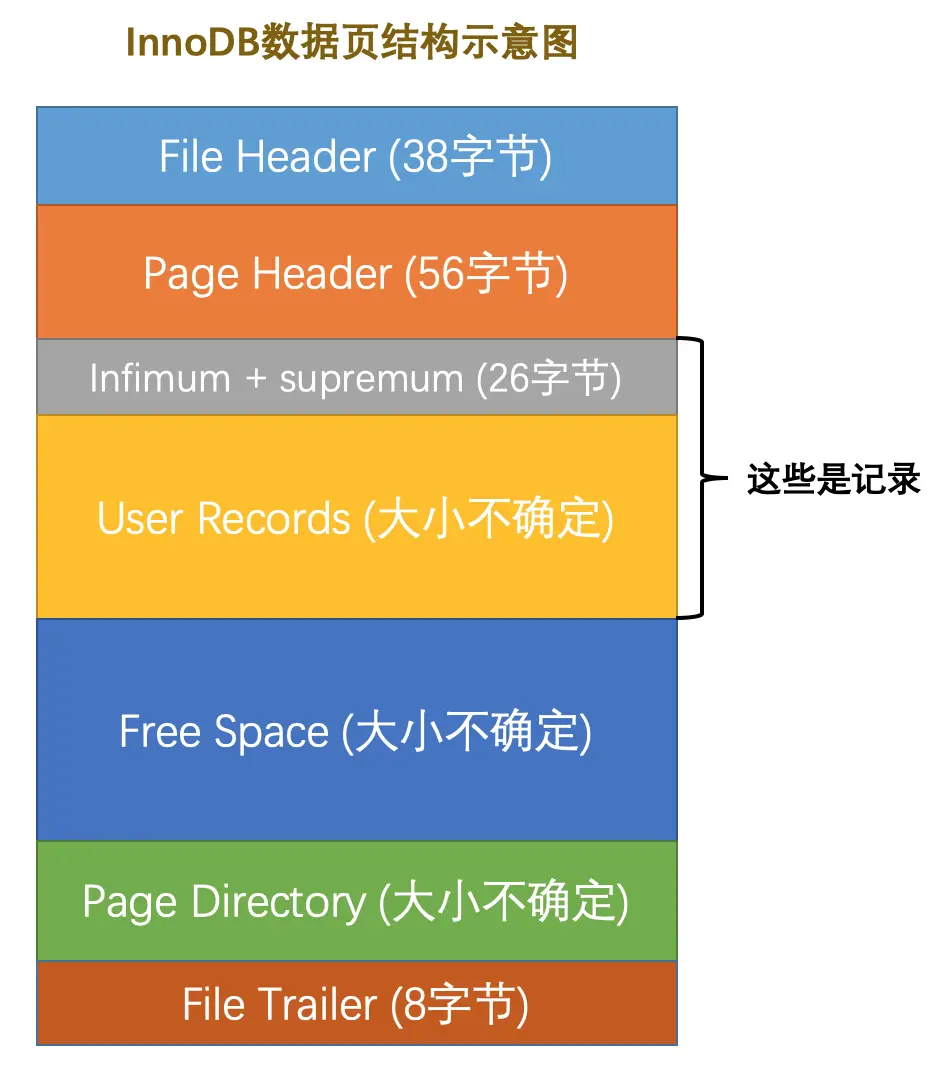
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
File Header |
文件头部 | 38字节 |
页的一些通用信息(页名,上下页,类型…) |
Page Header |
页面头部 | 56字节 |
数据页专有的一些信息(槽数,数据行数…) |
Infimum + Supremum |
最小记录和最大记录 | 26字节 |
两个虚拟的行记录 |
User Records |
用户记录 | 不确定 | 实际存储的行记录内容 |
Free Space |
空闲空间 | 不确定 | 页中尚未使用的空间 |
Page Directory |
页面目录 | 不确定 | 页中的某些记录的相对位置 |
File Trailer |
文件尾部 | 8字节 |
校验页是否完整 |
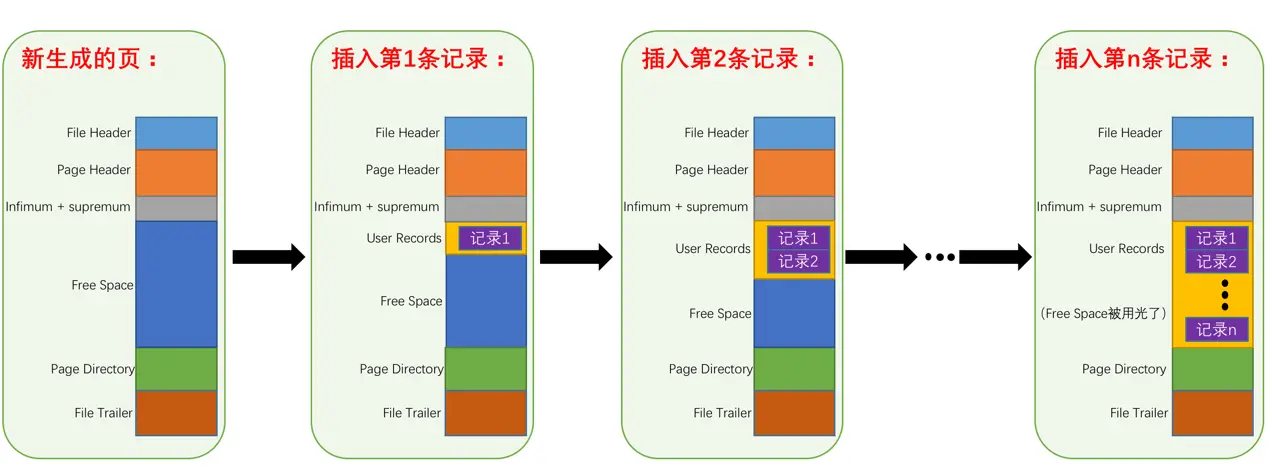
插入数据过程
记录头信息
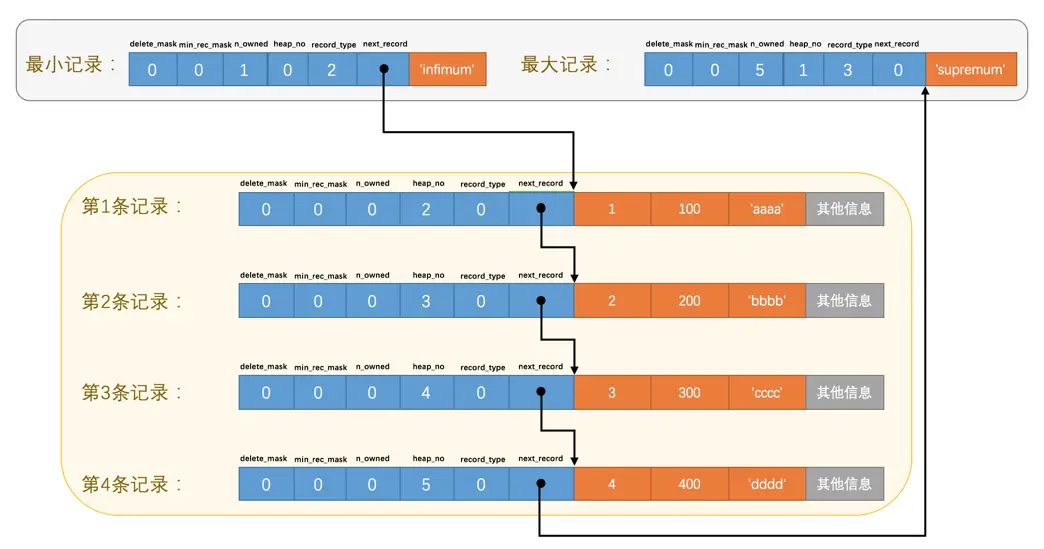
| 名称 | 大小(单位:bit) | 描述 |
|---|---|---|
预留位1 |
1 |
没有使用 |
预留位2 |
1 |
没有使用 |
delete_mask |
1 |
标记该记录是否被删除 |
min_rec_mask |
1 |
B+树的每层非叶子节点中的最小记录都会添加该标记 |
n_owned |
4 |
表示当前记录拥有的记录数 |
heap_no |
13 |
表示当前记录在记录堆的位置信息(下标) |
record_type |
3 |
表示当前记录的类型,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录 |
next_record |
16 |
表示下一条记录的相对位置(指针) |
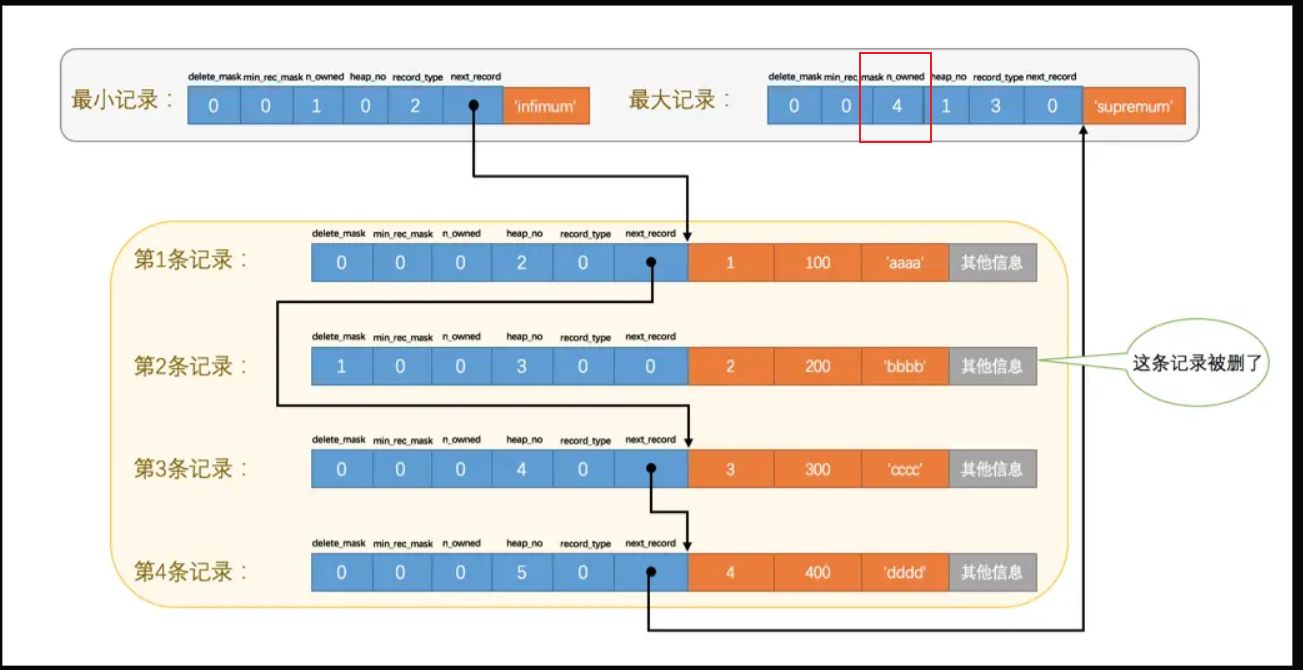
- 指针指向中间
- 删除的行不会立刻清除,但插入相同数据时会恢复
页目录(page directory)
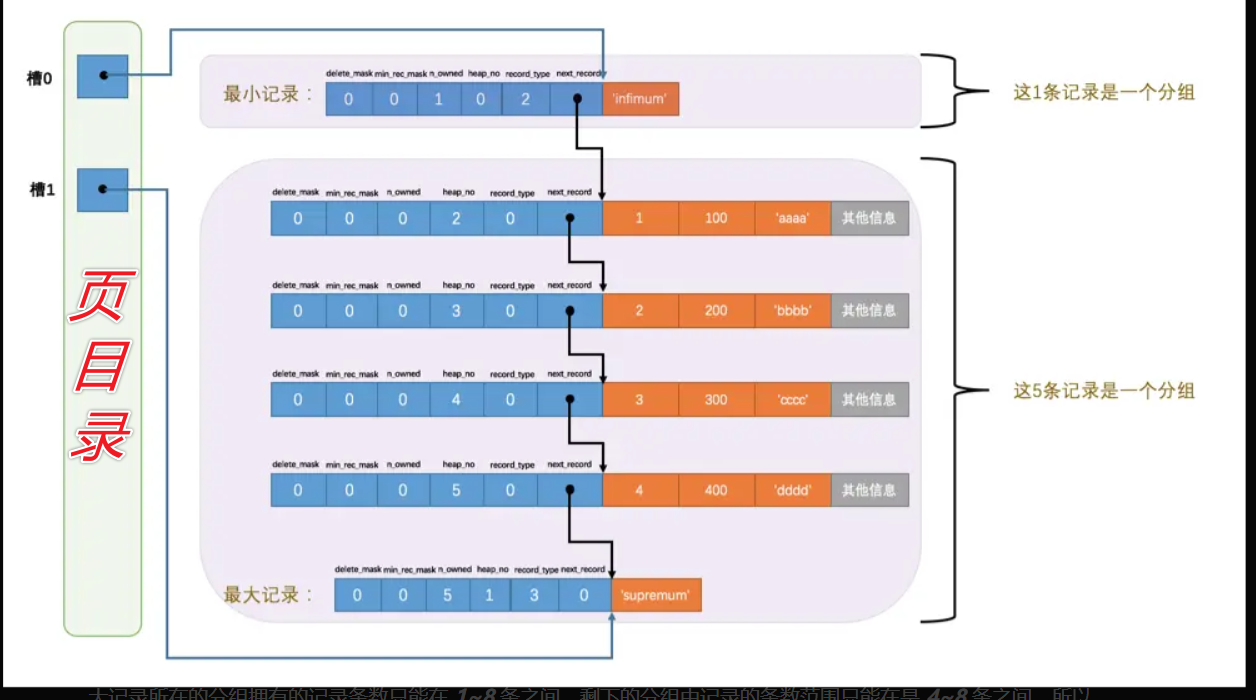
- 最小记录的
n_owned值为1,这就代表着以最小记录结尾的这个分组中只有1条记录,也就是最小记录本身。 - 最大记录的
n_owned值为5,这就代表着以最大记录结尾的这个分组中只有5条记录,包括最大记录本身还有我们自己插入的4条记录。
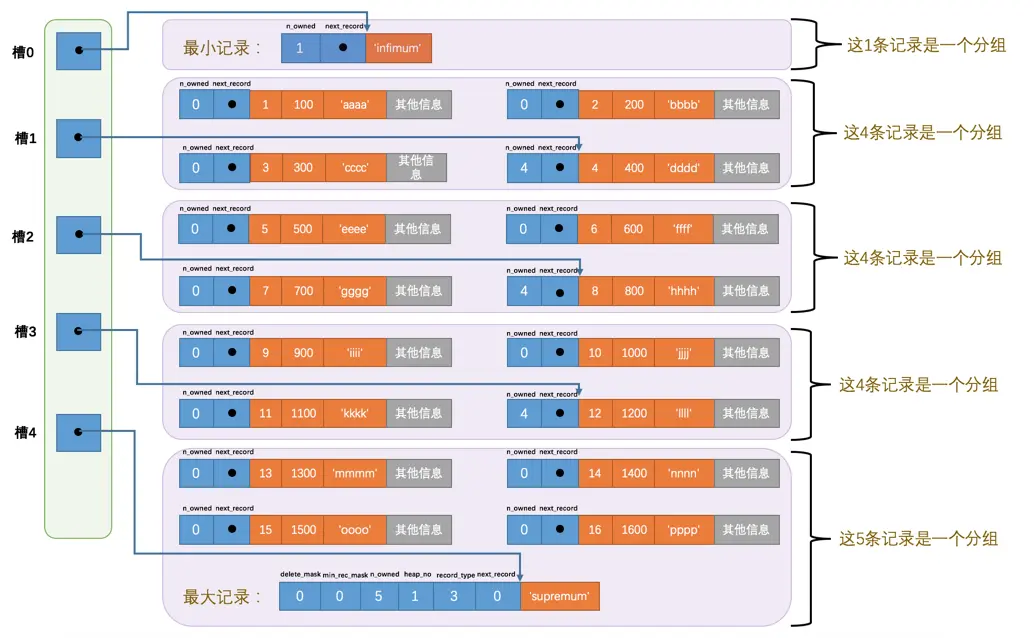
- 最小记录组只能有一行数据
- 最大记录组数据行数1-8行
- 其余4-8行
查询是通过二分查找来查询
File Header(文件头部)
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM |
4字节 |
页的校验和(checksum值)(类似与hash转化,将长字符转化为短字符进行比较) |
FIL_PAGE_OFFSET |
4字节 |
页号 |
FIL_PAGE_PREV |
4字节 |
上一个页的页号 |
FIL_PAGE_NEXT |
4字节 |
下一个页的页号(页与页之间是双向列表) |
FIL_PAGE_LSN |
8字节 |
页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number) |
FIL_PAGE_TYPE |
2字节 |
该页的类型(MySQL有许多种页) |
FIL_PAGE_FILE_FLUSH_LSN |
8字节 |
仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID |
4字节 |
页属于哪个表空间 |
Page Header(页面头部)
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
PAGE_N_DIR_SLOTS |
2字节 |
在页目录中的槽数量 |
PAGE_HEAP_TOP |
2字节 |
还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
PAGE_N_HEAP |
2字节 |
本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
PAGE_FREE |
2字节 |
第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
PAGE_GARBAGE |
2字节 |
已删除记录占用的字节数 |
PAGE_LAST_INSERT |
2字节 |
最后插入记录的位置 |
PAGE_DIRECTION |
2字节 |
最后记录插入的方向 |
PAGE_N_DIRECTION |
2字节 |
一个方向连续插入的记录数量 |
PAGE_N_RECS |
2字节 |
该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
PAGE_MAX_TRX_ID |
8字节 |
修改当前页的最大事务ID,该值仅在二级索引中定义 |
PAGE_LEVEL |
2字节 |
当前页在B+树中所处的层级 |
PAGE_INDEX_ID |
8字节 |
索引ID,表示当前页属于哪个索引 |
PAGE_BTR_SEG_LEAF |
10字节 |
B+树叶子段的头部信息,仅在B+树的Root页定义 |
PAGE_BTR_SEG_TOP |
10字节 |
B+树非叶子段的头部信息,仅在B+树的Root页定义 |
You can’t connect the dots looking forward; you can only connect them looking backwards. So you have to trust that the dots will somehow connect in your future. You have to trust in something - your gut, destiny, life, karma, whatever. This approach has never let me down, and it has made all the difference in my life
File Trailer(文件尾部)
- 前4个字节代表页的校验和
这个部分是和
File Header中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为File Header在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在File Header中的校验和就代表着已经修改过的页,而在File Trailer中的校验和代表着原先的页,二者不同则意味着同步中间出了错。 - 后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
er在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在File Header中的校验和就代表着已经修改过的页,而在File Trailer`中的校验和代表着原先的页,二者不同则意味着同步中间出了错。
- 后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
这个部分也是为了校验页的完整性的,只不过我们目前还没说
LSN是个什么意思,所以大家可以先不用管这个属性。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/57539.html