
作者:Mike Freeman
编译:Bot
编者按:中心极限定理是概率论中的一组重要定理,它的中心思想是无论是什么分布的数据,当我们从中抽取相互独立的随机样本,且采集的样本足够多时,样本均值的分布将收敛于正态分布。为了帮助更多学生理解这个概念,今天,UW iSchool的教师Mike Freeman制作了一些直观的可视化图像,让不少统计学教授大呼要把它们用在课堂上。
本文旨在尽可能直观地解释统计学基础理论之一——中心极限定理的核心概念。通过下文中的一系列动图,读者应该能真正理解这个定理,并从中汲取应用灵感,把它用于决策树等其他项目。
需要注意的是,这里我们不会介绍具体推理过程,所以它不涉及定理解释。
教科书上的中心极限定理
在看可视化前,我们先来回顾一下统计学课程对中心极限定理的描述。



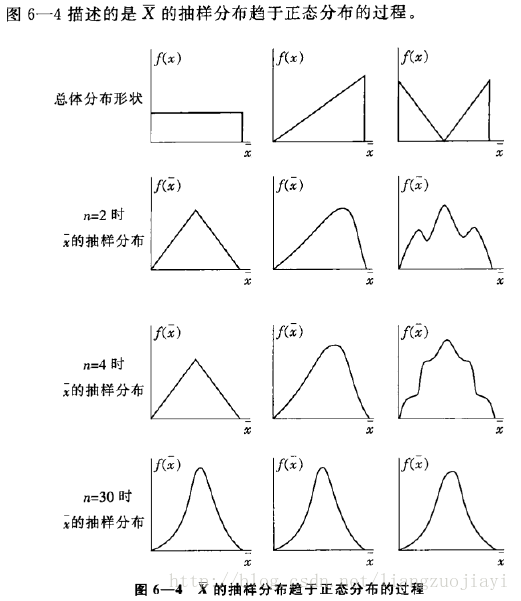
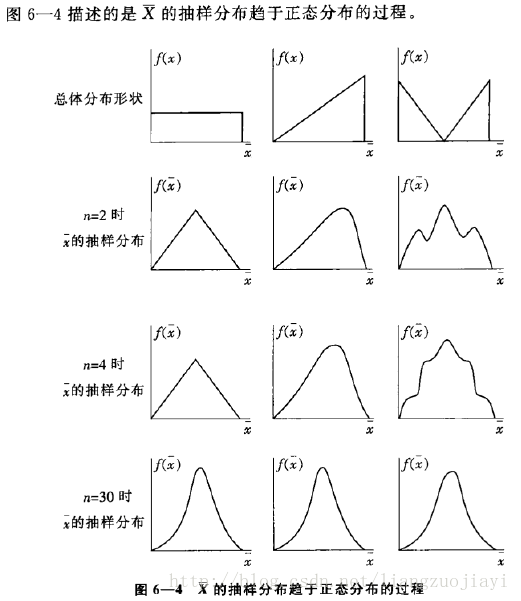
一个简单的例子
为了降低这个定理的理解门槛,首先我们来举个简单的例子。假设有一个包含100人的团体,他们在某些问题上的意见分布在0-100之间。如果以可视化的方式把他们的意见分数表示在水平轴上,我们可以得到下面这幅图:深色竖线表示所有人意见分数的平均值。


假如你是一名社会科学家,你想知道这个团体的立场特点,并用一些信息,比如上面的“平均意见得分”来描述他们。但可惜的是,由于时间、资金有限,你没法一一询问。这时候,你就可能需要对这100人进行抽样。比方说,在有限的时间、资金条件内,你可以从中随机抽取10个人作为自己的采访对象(n=10),向他们询问有关特定问题的具体想法:


如你所见,这些样本的均值可能会和整个团体的总体均值有很大差异。那么,怎么采样才能更可靠呢?
考虑多个样本
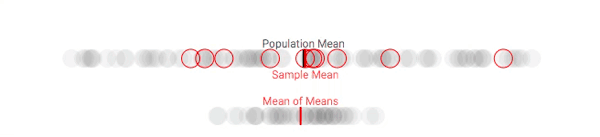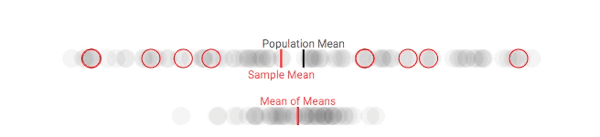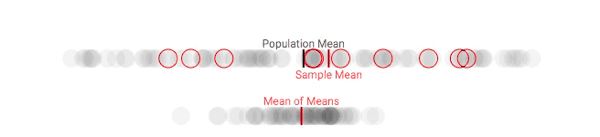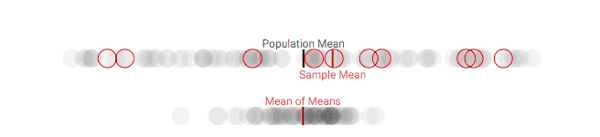
假设我们可以从团体中采集多个样本。虽然这种做法在现实中是客观存在的(尤其是在政治民意调查中),但在这里,我们会更多地将其作为一种解释工具(当你进行重复采样时,实际上会有一些意料之外的因素出现)。对于每个样本,我们在每次采样时都跟踪样本均值与整体平均值的差。
多次重复该过程,我们就能获得样本均值的分布,它通常被称为样本均值分布,或者(更简单的)抽样分布。下面是对100人的团体进行多次抽样后(每次10人),样本均值的变化情况:
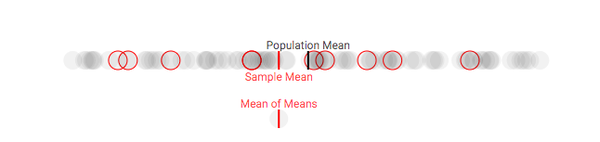
第一次采样,样本均值和总体均值有明显偏差
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/29398.html