
斜风细雨作小寒,淡烟疏柳媚晴滩。入淮清洛渐漫漫。
雪沫乳花浮午盏,蓼茸蒿笋试春盘。人间有味是清欢。
---- 苏轼
低秩矩阵恢复是稀疏向量恢复的拓展,二者具有很多可以类比的性质。首先,稀疏是相对于向量而言,稀疏性体现在待恢复向量中非零元素的数量远小于向量长度;而低秩是相对于矩阵而言,低秩体现在矩阵的秩远小于矩阵的实际尺寸。其次,稀疏向量恢复问题可以转化为基于 ℓ1范数是 ℓu 的**凸包络;而矩阵的核范数在一定条件下也是矩阵秩的**凸近似,因此,也可以利用这一性质将低秩矩阵恢复问题松弛为一个凸问题来求解。本文重点介绍低秩矩阵恢复的一些常用算法,并给出了奇异值阈值(STV)算法用于低秩矩阵恢复的仿真分析。
1. 低秩矩阵恢复问题背景
随着数据维度的增加,高维数据之间往往存在较多的相关性和冗余度,而且数据本身信息量的增长比数据维度的增长通常要慢得多。例如,视频信号的可压缩空间比单幅图像的可压缩空间大得多。一幅自然图片经过小波变换之后,只有少量的系数在数值大小上是相对显著的。如果将一幅图片当成一个像素矩阵,对其进行奇异值分解后,其前10%奇异值包含的信息量往往占了整幅图像的90%。这些实例都说明在高维数据中,往往存在不同程度的相关性,利用这些相关性可以大幅减小数据的存储空间和处理复杂度。
此外,现实生活中的大规模数据常常会有部分数据缺失、数据误差、损坏等问题,这将进一步加大数据处理和分析难度。这种现在在实际生活中很常见,例如在人脸识别中,训练集中的或是待识别的人脸图像往往含有阴影、高光、遮挡、变形等;在运动恢复结构(Structure from motion,SFM)问题中,进行特征提取和特征匹配时往往存在大的匹配误差. 这些因素的存在使得很多传统的分析和处理方式失效, 需要新的理论和实用的算法为相关的应用提供理论支撑和有力的求解工具.正确并高效地从不完整的、带有损毁的数据中 恢复和利用它们, 对现代大规模数据的分析与处理至关重要。
假定原始数据矩阵是低秩的,但是矩阵中含有很多未知的元素。从一个不完整的矩阵中恢复出一个完整的低秩阵,便是低秩矩阵填充问题。例如,著名的Netflix问题便是一个典型的低秩矩阵填充问题。Netflix是美国的一家影片租赁公司,其推荐系统(recommendation system)要从用户仅有的对少数的电影打分中为用户推荐影片,如果这种推荐越符合用户的喜好,也就越能提高该公司租赁电影的业务,为此,该公司设立了百万美元的奖金用于悬赏能够最好地提高该公司推荐系统质量的解决方法。这个问题可以用矩阵填充来进行建假设矩阵的每一行分别代表同一用户对不同电影的打分, 每一列代表不同用户对同一电影的打分,用户数量巨大, 电影数目巨大,因此这个矩阵的维度十分大。由于用户所打分的电影有限,这个矩阵中只有很小一部分的元素值已知,而且可能含有噪声或误差,那么Netflix问题就是如何从这个不完整的矩阵中推测其中未知元素的值。矩阵填充的越准确,为用户推荐的电影也就越符合用户的喜好。
2. 低秩矩阵补全
矩阵补全是推荐系统、计算机视觉、图像处理等领域经常遇到的问题,具有很高的研究价值。矩阵补全问题旨在通过真实未知矩阵 
讯享网的部分观测 来估计中未观测到的其他元素。如果不加其他约束,这样的问题是完全不可解的。但是,如果数据矩阵具有一些特殊的性质,这些特殊的性质将使得矩阵补全问题成为可能。低秩性就是这样的性质。如果事先知道矩阵 是低秩的,那么矩阵补全问题可以形式为为如下优化问题:

其中 为观测样本下标的集合,为优化变量, 为真实的未知矩阵。定义投影算子 :
KaTeX parse error: Unknown column alignment: * at position 73: …{\begin{array}{*̲{20}{c}} {
{
{…
从而(1)式可以简洁地表述为:

显然,上述问题是一个NP-hard问题,且其复杂度随矩阵维度的增城呈平方倍指数关系增长。为了求解问题(1),有学者对其进行凸松弛,转化为一个凸优化问题:

文献[2]中指出:问题(4)的解在满足强非相干性条件下,很大概率等价于问题(1)的解。在某种意义上,这是NP-难秩最小化问题的紧凸松弛。因为核范数球是谱范数为1的rank one矩阵集合的凸包。具体定理及证明参见文献[1]。
对于(4)中的优化问题,当采样点数满足 时, 能以很大概率求得精确解,其中 为矩阵 的秩,为一个正常数。
求解(4)式可以使用一些凸松弛方法,比如半定规划法,然而半定规划法通常使用内点法来求解,其求解上述问题的算法复杂度为可以通过matlab软件包CVX等来求解。

3. 奇异值阈值算法(SVT)
2009年,Cai Jian-feng 和 Candes(e上面有个四声符号)等人提出了求解核范数最小化问题的奇异值阈值算法(Singular Value Thresholding, SVT)。该算法可以类比为求解向量 ℓ0范数最小化的软阈值迭代算法。 SVT算法先将最优化问题(4)正则化,即有:
其中,。当 $\tau \to + \infty $ 时,上述最优化问题的最优解收敛到(4)式的最优解。构造最优化问题(5)的拉格朗日函数:
其中,拉格朗日乘子 。如果 为优化问题(4)的原-对偶问题的最优解,则有:

SVT算法使用交替迭代方法求解优化问题(4),其迭代格式可以简单表述如下:
其中 为奇异值阈值软阈值操作类似,不过这里的对象是矩阵。可以具体描述为:
其中(8)式中的第一步是这样来的,初始化,当 固定时:
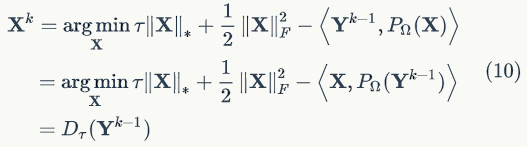
(8)式中的第(2)式,当 给定时,用梯度下降来更新 。
4. 仿真
SVT算法的matlab代码如下:
function [ X,iterations ] = SVT(M,P,T,delta,itermax,tol) %Single value thresholding algorithm,SVT % function:solve the following optimization problem % min ||X||* % s.t. P(X-M) = 0 % X: recovered matrix % M: observed matrix % T: single value threshold % delta: step size % output:X,iterations % initialization Y = zeros(size(M)); iterations = 0; if nargin < 3 T = sqrt(n1*n2); end if nargin < 4 delta = 1; end if nargin < 5 itermax = 200 ; end if nargin < 6 tol = 1e-7; end for ii = 1:itermax % singular value threshold operation [U, S, V] = svd(Y, 'econ') ; S = sign(S) .* max(abs(S) - T, 0) ; X = U*S*V' ; % update auxiliary matrix Y Y = Y + delta* P.* (M-X); Y = P.*Y ; % computer error error= norm( P.* (M-X),'fro' )/norm( P.* M,'fro' ); if error<tol break; end % update iterations iterations = ii ; end end 讯享网
讯享网数值验证代码为如下:
% Numerical verification for SVT algorithm clear clc r = 2 ; % rank(M) = 2 ; n1 = 200 ; % row length of M n2 = 300 ; % column length of M sample_rate = 0.5 ; % real % M = rand(n1,r)*rand(r,n2) ; % complex M = (rand(n1,r)+1i*rand(n1,r))*(rand(r,n2)+1i*rand(r,n2))/2 ; % construct index matrix P = zeros(n1*n2,1) ; MM = reshape(M,n1*n2,1) ; pos = sort(randperm(n1*n2,n1*n2*sample_rate))' ; P(pos) = MM(pos) ; index1 = find(P) ; P(index1) = 1 ; P = reshape(P,n1,n2) ; % set threshold & step size T = sqrt(n1*n2); delta = 2 ; [ X,iterations ] = SVT(M,P,T,delta) ; % norm(P.*(X-M),'fro') norm(P.*(X-M),'fro')/norm(P.*M,'fro') % norm(X-M,'fro') % norm(X-M,'fro')/norm(M,'fro')
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/29397.html