
我上周花了一周时间搭了个测试环境:5000篇中文技术文档,200个真实查询,5款Embedding模型挨个跑了一遍。
结果有点出乎意料,网上讨论最多的几个模型,中文的表现反而不是最好。
这里先把条件摆出来,方便你判断这些数据的参考价值。
文档数据
- 5000篇中文技术文档(AI、编程、数据科学)
- 平均长度1200字/篇
- 总计约600万字
查询数据
- 200个真实用户查询
- 覆盖4类:事实型(50个)、概念型(50个)、对比型(50个)、操作型(50个)
测试环境
- 向量数据库:Milvus 2.3
- 硬件:单张A100 80GB
- 评测指标:Recall@10、P95延迟、单次查询成本
不想看过程的可以直接抄作业。
中文RAG推荐:
- 预算紧
→ bge-large-zh-v1.5(免费,中文召回率第二)
- 要精度
→ glm-embedding(中文召回率领先,价格还行)
- 图省事
→ OpenAI text-embedding-3-large(生态成熟,中文不是最强)
别碰:m3e-large(召回率掉队)和 cohere-embed-v3(中文一般,还收钱)
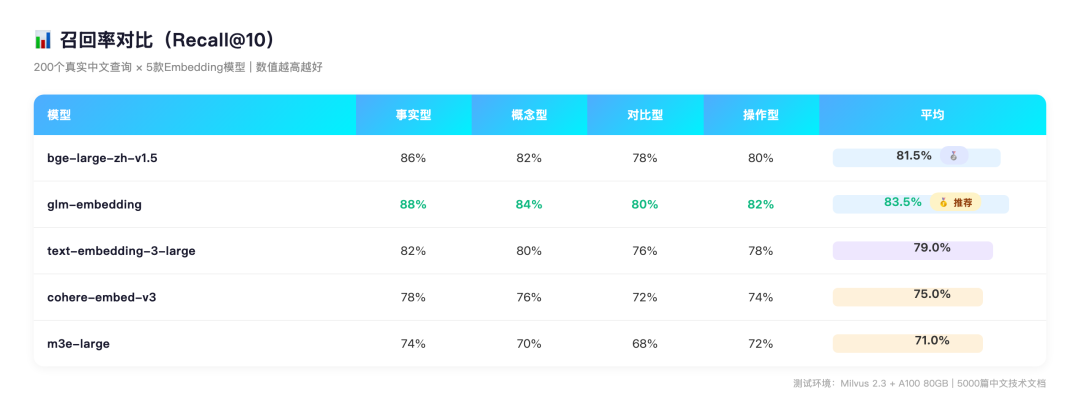
召回率(Recall@10)
RAG说白了就是“找对文档”。文档找错了,后面LLM再强也是白搭,所以召回率我放在第一位测。

说说数据反映的情况:
国产模型在中文上确实占便宜。bge-large-zh和glm-embedding平均召回率都过了80%,OpenAI和Cohere都没到。
这不是说国产模型技术上更厉害。主要是训练语料里中文占比大,对中文语义理解得更细。
“对比型”查询翻车最多。
比如用户搜“A和B有什么区别”,模型得同时理解两个概念,再在向量空间里找到同时涉及两者的文档。这类查询召回率普遍偏低,最高也就80%。
延迟(P95)
用户搜一个问题,等10秒才有回答,体验肯定很差。

开源模型延迟碾压API模型,差距3-5倍。
原因不复杂:本地部署没有网络开销。API调用要过一趟网络,光是往返延迟就吃掉了大部分。
做实时客服之类的场景,基本只能选本地部署。
m3e-large召回率虽然低,但延迟表现还不错。对精度要求不高的场景,凑合能用。
成本
成本要看你怎么用。
调用量小,API更划算;
调用量大,自建GPU更省钱。
开源模型(bge、m3e)
- 需要GPU服务器,大约2-5万/月
- 调用成本接近零(电费+运维)
- 适合日调用量100万以上
API模型(OpenAI、glm、cohere)
- 不需要自己部署
- 按token计费
- 适合日调用量100万以下
成本交叉点估算:
拿bge-large-zh-v1.5和glm-embedding估算:
- 日50万次:API约25元/天,GPU约167元/天 → API便宜
- 日200万次:API约100元/天,GPU约167元/天 → API还是便宜
- 日500万次:API约250元/天,GPU约167元/天 → 自建才划算
交叉点大概在日调用量300-400万次。如果你的业务低于这个数,就直接调API,别折腾自建啦。
坑一:参数用默认值
模型都有默认参数,但它们不一定适合你的场景
bge-large-zh-v1.5的关键参数:
encode_kwargs[‘normalize_embeddings’]:设为True,效果提升3-5%- 查询前缀:加上“为这个句子生成表示以用于检索相关文章”,召回率提升2%
glm-embedding的关键参数:
- 维度选择:1024维度够用,不需要追求更高
- 批量大小:64效果最好,太大反而降低吞吐量
坑二:分块策略太粗暴
Embedding模型有输入长度上限,超了就得切。怎么切,直接影响召回率。
实测数据:
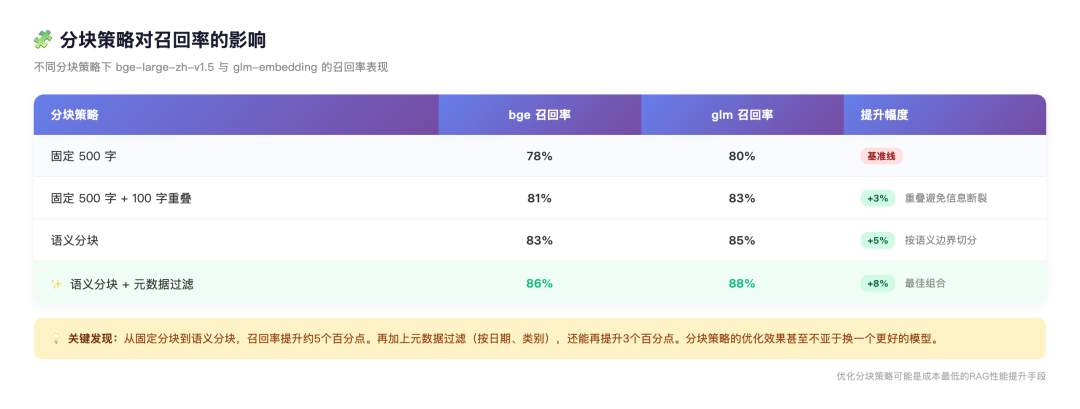
语义分块比固定分块高了5个百分点。再加上元数据过滤(按日期、类别筛),还能再提3个点。
坑三:Query不改写
用户搜的词通常很短,比如“怎么用RAG”。直接拿这个去检索,效果很差。
三个改写技巧:
- 用LLM把短查询扩成完整问题:“怎么用RAG” → “怎么用RAG技术搭建企业知识库问答系统”
- 生成几个相似查询,分别检索后合并结果
- 提取关键词当元数据过滤条件
我测下来,Query改写能提5-8个百分点的召回率。
根据上面数据,画了个决策图:
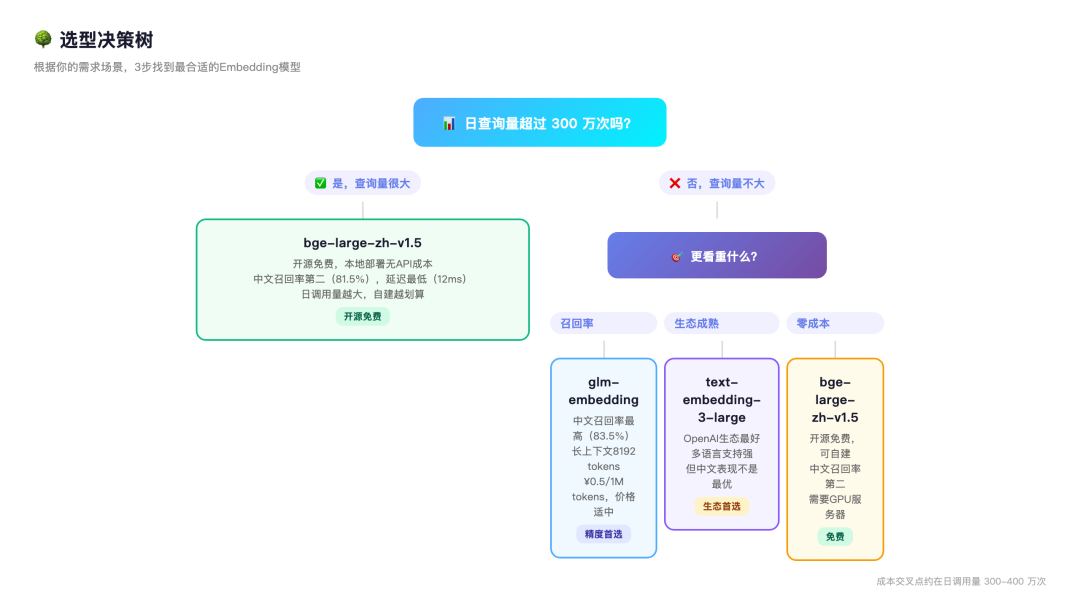
日调用量超过300万?
- 是 → 自建GPU → bge-large-zh-v1.5
- 否 → 继续往下看
你更在意哪个?
- 召回率 → glm-embedding
- 省事 → OpenAI text-embedding-3-large
- 不花钱 → bge-large-zh-v1.5(自建)
有没有特殊需求?
- 要多语言 → OpenAI或Cohere
- 文档很长 → glm-embedding(支持8192 tokens)
- 数据不能出内网 → bge-large-zh-v1.5
做完这次测试,最大的感受是:很多人搞RAG,精力都花在LLM选型上了。
检索环节召回率不够,LLM再强也没用。
输入是垃圾,输出也只会是垃圾。
Embedding选对、分块做好、Query改写加上,这三个动作就能把准确率从60%拉到85%以上。
先把检索这关过了,咱们再操心LLM的事。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
扫码免费领取全部内容

要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

👇👇扫码免费领取全部内容👇👇

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/261761.html