
文章深入探讨了Agent Harness在AI落地中的关键作用,指出当前许多Agent应用存在长程任务失忆、遗留代码迷路、生成交付断链、确定性和安全性翻车等问题。文章剖析了Anthropic、OpenAI、LangChain三大巨头的Harness实践,如Anthropic的脚手架和独立评估器解决长任务问题,OpenAI的自动驾驶系统实现百万行代码自主开发,以及LangChain通过优化Harness使编码能力大幅提升。文章强调Harness工程是AI工程化的必经之路,通过上下文工程、执行闭环、架构约束等组件,将不可控的AI转化为可长期运行、可治理的系统,预示着Harness将成为AI落地的下一个风口。
AI圈又炸了一个新概念——Agent Harness。

不是什么玄乎的黑科技,却让无数AI工程师直呼“终于找到了救星”;不是能让大模型变聪明的“魔法”,却能让那些“桀骜不驯”的AI,从“只会聊天的玩具”变成“能落地干活的工具”。
很多人还在跟风聊Agent,却没意识到一个致命问题:
你以为的Agent,是“输入指令就能自动完成任务”;但现实中的Agent,是“写一半就摆烂、改十遍还出错、出问题找不到原因”的“半成品”。
而Harness,就是那个能“驯服”AI的“马具”——它不提升马的速度,却能让马沿着轨道稳稳跑,不跑偏、不脱缰。
今天我们就彻底拆解:为什么现在所有人都开始在意Harness?Anthropic、OpenAI、LangChain三大巨头的实践,到底藏着怎样的落地密码?(全文干货,建议收藏)
现在谁都能说一句“我在用Agent”,但真正能把Agent用在生产里的,少之又少。
不信你自测:你用的Agent,是不是只敢用来做这些事?——整理行业资讯、写个简单函数、做个个人待办清单。
一旦涉及“生产级”任务,比如复杂项目开发、遗留代码迭代、企业级软件交付,Agent就会瞬间“露馅”,问题百出:
长程任务必“失忆”:一个需要上百个步骤、跨多个系统的任务,Agent写着写着就忘了前面的逻辑,就像工程师轮班不交接,最后交付的全是“半成品”;
遗留代码必“迷路”:面对上万个源代码文件、复杂的依赖关系,AI只会瞎写代码,每一行都可能触发隐藏bug,反而给人类添乱;
从生成到交付必“断链”:写代码只是第一步,环境搭建、依赖安装、测试覆盖、CI/CD部署,哪一步断了,Agent就成了“需要人类擦屁股”的累赘;
确定性和安全性必“翻车”:企业级场景里,AI的“幻觉”会导致逻辑漏洞,随意泄露敏感信息更是致命,可你根本管不住它。
更让人崩溃的是:
相同的任务,今天能跑通,明天就报错;明明指令很明确,它却偏要“跑偏”;出了问题,你根本追溯不到原因——到底是模型不行,还是指令错了?
很多人第一反应是:“我需要更厉害的模型!”
但真相是:强大的基础模型,只能把任务完成度从30分提到60分;而企业需要的,是90分以上的稳定交付。
这就是Harness突然爆火的核心原因——它不解决“模型不够聪明”的问题,只解决“模型不够听话、不够稳定”的问题。
就像给发动机配上变速箱、底盘和外壳:发动机本身没变强,但这辆车能平稳、受控地跑起来,能真正上路干活。
而Agent Harness,就是给大模型配的“变速箱+底盘+外壳”,把不可控的AI,变成可长期运行、可治理、可落地的系统。
其实Harness不是新东西,在软件工程领域,早就有“Test Harness”(测试 harness)——用一套模拟基础设施,把被测组件包起来,在可控环境里驱动它、观察它、校验它。
而Agent Harness,就是把这个逻辑,平移到了AI Agent上。
大模型就像一个“不可预测的被测件”,时而聪明、时而拉胯,想要让它稳定落地,就必须给它套一个“控制外壳”——这个外壳,就是Harness;而构建这个外壳的工作,就是Harness Engineering。
LangChain有一个很精辟的总结,帮你快速理解:
Agent = Model(智能核心) + Harness(系统外壳)
简单说:只要不是模型本身,剩下的所有用来控制、约束、辅助AI的部分,都是Harness。
现在,Anthropic、OpenAI、LangChain三大巨头,已经交出了自己的Harness实践答卷——它们的做法,不仅揭示了Harness的核心逻辑,更给所有AI落地者提供了可直接借鉴的模板。
接下来,我们逐个拆解,看看这些大厂是如何用Harness“驯服”AI的。
Anthropic的Harness实践,核心瞄准了AI Coding最棘手的问题——长程任务(Long-running tasks)。
比如一个需要持续数天、拆分上百个子任务的编程项目,AI很容易出现两个问题:一是上下文割裂,写着写着忘了前面的逻辑;二是“自我感觉良好”,写得再烂也觉得没问题,不迭代、不修正。
针对这两个痛点,Anthropic设计了一套“脚手架+指挥官”式的Harness,核心就两件事:
- 任务拆分+增量交接,杜绝“换班失忆”
Anthropic没有让AI“一口吃个胖子”,而是把长程任务拆分成多个独立的功能列表,采用“增量式开发”,并强制要求做好“任务交接”。
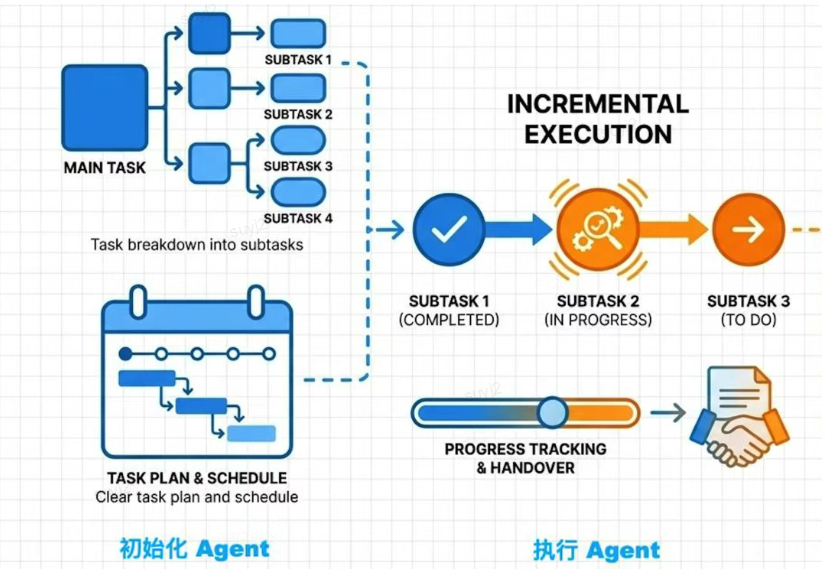
他们设置了两个角色:
初始化Agent:负责搭环境、定计划、做进度表,相当于“项目负责人”;
执行Agent:一次只专注一个子任务,完成后更新进度、写任务摘要、提交Git日志,相当于“执行工程师”。
这样一来,每个子任务完成后,都会留下清晰的“痕迹”——下一个子任务启动时,AI能快速衔接之前的工作,既不会失忆,也能节约Token空间。
- 独立评估器,让AI“跳出当局者迷”
为了解决AI“自我感觉良好”的问题,Anthropic引入了一个“独立评估Agent”——不干活,只“挑刺”。
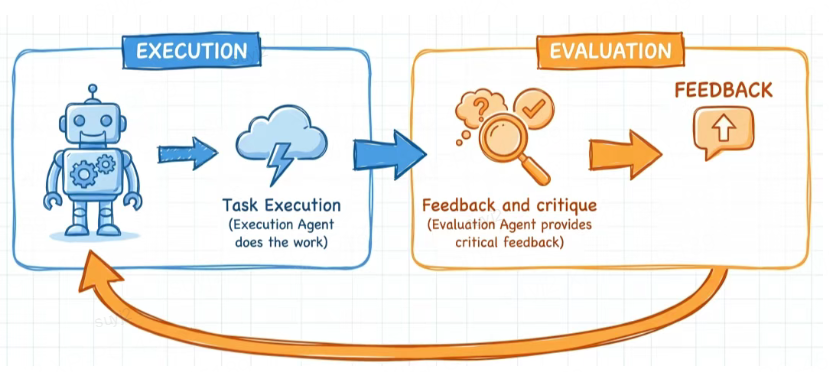
执行Agent写完代码后,评估Agent会按照预设的标准,逐一检查:逻辑对不对?有没有覆盖需求?有没有bug?
如果没通过,评估Agent会给出具体的修改意见,让执行Agent重新迭代;直到通过评估,才算完成一个子任务。
这套“执行+评估”的闭环,正是Harness的核心价值——用外部约束,纠正AI的“自我认知偏差”,让长程任务的成功率翻倍。
小结:Anthropic的Harness,就像给长程任务搭了一套“脚手架”,又配了一个“指挥官”,让AI在预设的轨道上,一步一步稳稳推进,不跑偏、不脱节。
如果说Anthropic解决的是“长任务不迷路”,那OpenAI的Harness实践,就是“让AI实现真正的自主开发”——他们用一套严谨的Harness约束,让Codex在5个月内,从零开始写出了一个百万行代码的企业应用。
更惊人的是:全程没有一行人工代码,所有代码、文档、CI/CD配置,全由AI自主完成;人类的角色,从“写代码”变成了“定规则、搭环境、控方向”——这正是Harness Engineering的终极体现。
OpenAI的Harness,核心是4个关键设计,堪称AI自主开发的“自动驾驶系统”:
- 上下文工程:用“动态地图”代替“厚文档”
早期,OpenAI也试过给Agent塞一个1000页的规则文档,结果发现:模型注意力涣散,根本记不住重点,反而容易出错。
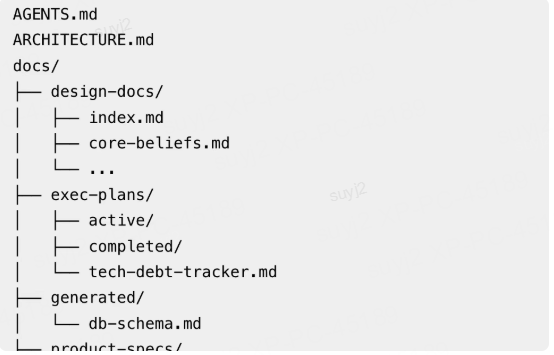
后来他们改成了“Agent-first的层次化知识库”:
把规则文档精简到100行,只做“上下文地图”,指向更深层的架构和设计文档;
专门设置一个“知识库检修Agent”,定期扫描文档,发现过时或与代码不符的内容,自动提交PR修正——确保AI拿到的“地图”永远是最新的。
- 执行闭环:让AI能“自我驱动、自我修复”
OpenAI给Codex搭建了一个“沙箱环境”:在这里,AI不仅能写代码,还能自主启动应用、操作浏览器、查看日志、复现bug、验证修复效果。
一个任务可以持续运行数小时,AI能在无人干预的情况下,完成“定位问题→修复bug→提交代码”的全流程——这就是Harness赋予AI的“自主能力”。
- 架构约束:用“刚性外壳”防止AI“乱写字”
百万行代码的体量,最怕的就是“架构漂移”——AI写着写着,就偏离了预设的架构,导致整个系统混乱。
OpenAI的解法,不是人工Review,而是“刚性约束”:
固定系统分层架构,严格限制代码的依赖方向;
自定义静态检查工具(Linter),禁止非法依赖;
强制执行数据校验、日志规范、命名规则——让系统自己“监督”AI,不让它“乱写字”。
- 垃圾回收:让代码库“自我净化”
AI写代码,很容易复制早期的“烂代码模式”,时间久了,整个代码库会越来越臃肿、越来越乱。
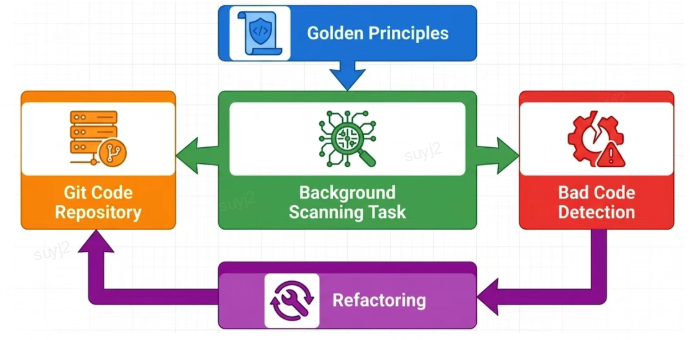
OpenAI引入了“代码垃圾回收”机制:定义一系列“黄金原则”(比如优先使用标准库),后台Agent定期扫描代码库,识别不好的代码模式,自动发起重构——让代码库持续“自我净化”,保持高质量。
小结:OpenAI的实践,道出了一个核心真相——想要让AI拥有极高的自主权,就必须给它极强的自由度约束。这套Harness,就是AI自主开发的“自动驾驶系统”,让模型在规则内,尽情发挥能力。
如果说Anthropic和OpenAI是“模型厂商玩Harness”,那LangChain的实践,对广大Agent开发者来说,更有借鉴意义——因为他们没有底层模型优势,却用Harness,实现了“模型不变,能力翻倍”。
LangChain的DeepAgents,在底层模型(GPT-5.2-Codex)完全不变的情况下,仅仅优化Harness工程,就在Terminal Bench 2.0测试集上,从Top 30直冲Top 5——这就是Harness的力量。
他们的核心思路是:不指望模型自己变聪明,而是用Harness,包容、检测并纠正模型的缺陷。具体有4个关键做法:
- Trace追踪:让AI“知错能改”
LangChain把“错误分析”做成了AI的一项技能:通过LangSmith记录AI的运行轨迹(Trace),自动诊断AI是在推理、工具调用还是超时上出了问题,生成具体的改进建议。
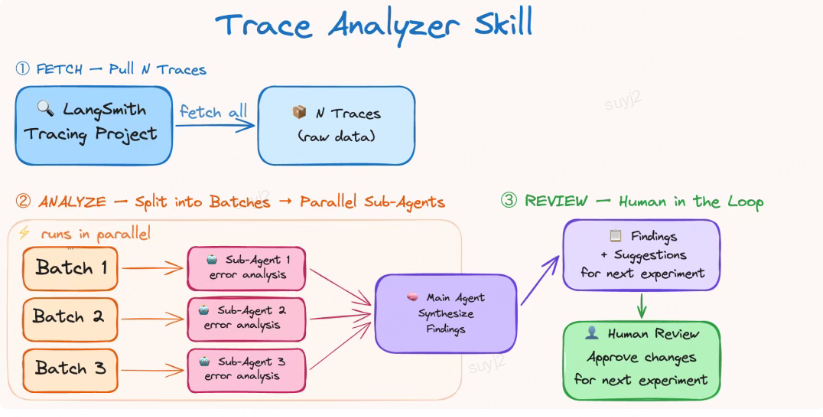
人类工程师只需根据建议,调整中间件或提示词,就能避免盲目试错——让AI的每一次失败,都能变成进步的机会。
- 强制闭环:打破AI的“懒惰”
很多Coding Agent的通病是:写完代码,看一眼就觉得“搞定了”,根本不做测试、不检查边缘情况。
LangChain用“强制拦截”解决这个问题:在系统提示中,强制要求AI完成“规划→构建→验证→修复”的闭环;在Agent企图结束任务时,设置“退出钩子”——必须回答“写测试了吗?覆盖边缘情况了吗?”,只有跑通测试,才能结束任务。
- 强制“退后一步”:打破思考死循环
AI很容易陷入“死循环”:反复修改同一个文件,改了10遍还是报错,却不知道换个思路。
LangChain的解法很简单:当中间件检测到AI反复修改同一个文件达到阈值(比如10次),就强制注入提示:“你已经卡了很久了,请退一步,重新考虑整体方案。”——帮AI跳出局部思维,避免内耗。
- 算力“三明治”分配:在时间限制内拿高分
很多任务有严格的超时限制,如果全程用最高推理算力,很容易超时;如果全程用普通算力,又会影响质量。
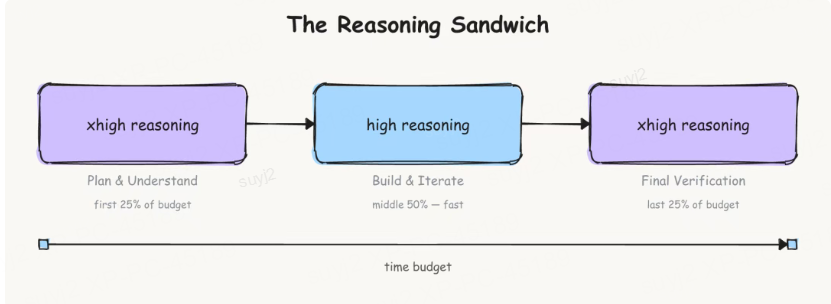
LangChain的策略是“三明治分配”:规划阶段和验证阶段用最高算力,中间执行阶段用常规算力——既保证质量,又避免超时,大幅提升长任务成功率。
小结:LangChain的实践证明,Harness不是“锦上添花”,而是“雪中送炭”——对于没有底层模型优势的开发者和企业来说,优化Harness,就是最低成本、最高效的AI落地路径。
看完三大巨头的实践,我们不难发现:Agent Harness的核心,从来不是“炫技”,而是用系统工程,兜底模型能力的不足。
没有放之四海而皆准的Harness——Coding Agent需要“测试驱动”的闭环,大型行业软件需要“私有知识注入”,敏感业务需要“安全边界管控”。但无论场景如何变化,Harness都离不开几个核心组件:
上下文工程、执行闭环、架构约束、评估反馈、追踪诊断、算力调度、安全管控——这7大组件,就是搭建Harness的“积木”,按需组装,就能适配你的业务场景。
而这,也正是AI工程化的下一个风口:
当所有人都在追逐“更强大的模型”时,真正能落地的人,都在专注于“让模型更听话”;当Agent还是“散装组件”时,能把它变成“标准化系统”的Harness,才是真正的核心竞争力。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/261749.html