
如果说 GPT-5.4 是前沿能力的集大成者,那么3月18日发布的 GPT-5.4 mini 和 GPT-5.4 nano,则是 OpenAI 为Agent 时代量身打造的极致效能工具。这对“小钢炮”组合不仅在速度上实现了飞跃,更针对高频、自动化的 Agent 协作场景进行了深度优化,正式开启了“子代理(Subagent)”协同作业的新篇章。
速度与性能的双重飞跃:
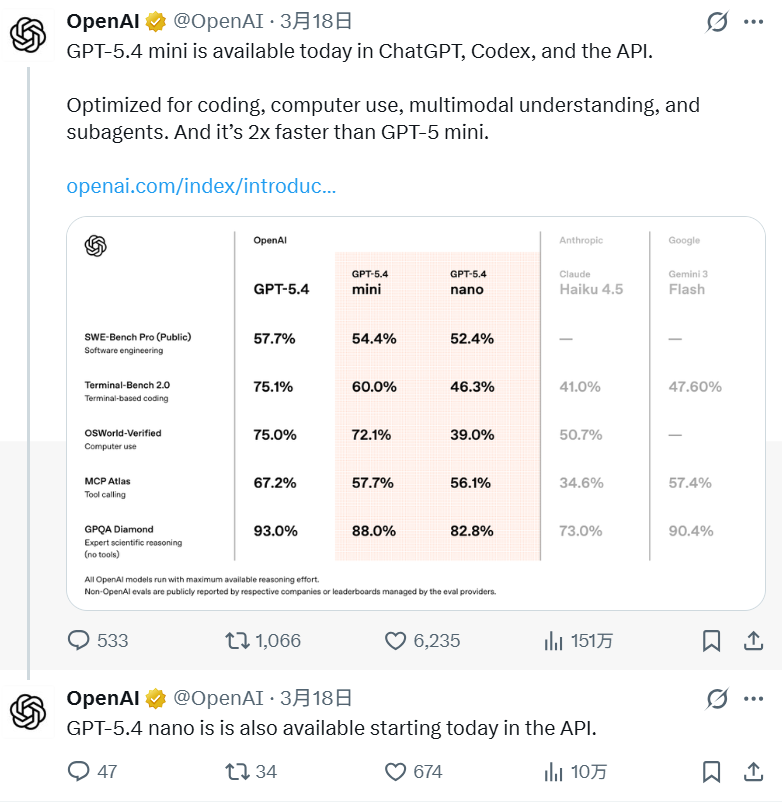
极致响应: 相比前代 GPT-5 mini,推理速度提升了 2 倍以上,极大地降低了高并发 API 调用下的延迟。
能力逼近旗舰: 尽管体积更小,但在 SWE-Bench Pro(编程)、OSWorld-Verified(电脑操作)等核心评测中,这两款模型的能力表现正在快速逼近全尺寸的 GPT-5.4,足以处理大多数生产环境下的复杂任务。
Agent 协作专精: 它们不再试图独立解决一切问题,而是被设计为“任务拆解的专家”——擅长处理 Agent 系统委派的特定子任务,例如代码库检索、多模态逻辑比对、复杂工具链调用等。
长上下文能力: 全系支持 400K Token 上下文窗口,使得小型模型也能处理长文档检索、大型代码库分析等需要长时记忆的任务。
生产力优化: 原生支持文本与图像输入、深度工具调用(Function Calling)以及精准的 Web 搜索,在低延迟场景下保持了极高的任务完成准确度,是构建复杂 Agent 系统的理想基石。
GPT-5.4 mini/nano 的发布,大幅降低了开发者构建 AI 应用的成本与耗时:你再也不必为了一个小任务而强行调用昂贵的大模型了。对于开发者而言,它们是构建大规模 Agent 系统的“骨架”:mini 和 nano 可以作为高效的“打工人”,在后台快速执行代码搜索、数据分类、流程自动化等高频子任务,而将昂贵的旗舰模型留给最终的推理决策。
GPT-5.4 mini/nano 系列究竟能在多大程度上替代全尺寸模型?它们在 Agent 链条中的真实生产力边界在哪里?302.AI将深入对比这对“小钢炮”与旗舰级模型在实际编程与自动化任务中的表现差异。
本评测侧重模型对逻辑,数学,编程,多模态,人类直觉等问题的测试,非专业前沿领域的权威测试。旨在观察对比模型的进化趋势,提供选型参考。
本次测评使用302.AI收录的题库进行独立测试。模型分别就逻辑与数学(共10题),人类直觉(共7题),多模态(共20题)以及编程模拟(共12题)进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
题库地址:https://docs.google.com/spreadsheets/d/1sBxs60yWsxc9I5Va8Rjc1_le1Omg2hOXbwqOzpImZio/edit?gid=0#gid=0
💡记分规则:
按满分10分记分,设定对应扣分标准,最终取每轮得分的平均值。
编程案例分数评级:
⭐⭐⭐⭐⭐ S 级(封神): 行业标杆,重新定义标准。
⭐⭐⭐⭐ A 级(卓越): 生产力合格,无明显短板。
⭐⭐⭐ B 级(优秀): 表现中规中矩,存在短板。
⭐⭐及以下 C级(不合格): 不可用,存在明显问题。
GPT-5.4 mini 的多模态识别能力较 nano 来说更精准,整体的细粒度感知和空间识别都更强,输出的推理过程更简洁直接,倾向呈现关键步骤。
GPT-5.4 mini 识别正确

GPT-5.4 nano识别错误

🔍 测评要点:满分需菜单列表+营养解释+可持续性;状况提取错误扣4分,无风险扣1分。多角度分析:边界如素食偏好转vegan计划,扩展到运动结合;借鉴健康AI app如营养追踪;用户意图测试模型的关怀处理,在养生中辅助模糊习惯;信息扩展:这多角度论述直觉的自我调节,如卡路里模糊估算体现代谢本能,与模糊健康数据工具类似机器学习预测,详尽讨论心理因素如动机衰减。
GPT-5.4 mini 输出的方案正确提取了关键需求,结构完整,除菜单规划之外还有营养解释、可持续性和风险分析,非常专业化。

GPT-5.4 nano 虽然也输出了完整食谱及风险分析,但最大疏漏在于对“偶尔疲劳”状态提取不足,定制食谱未提及“偶尔疲劳”的应对方式,只在“调整依据”部分被动提到了“疲劳”问题。

GPT-5.4 mini 生成的核心图形是准确的(自行车、鹈鹕结构),但动态效果明显翻车,车轮旋转方式错误,鹈鹕的腿部也没有与踏板相连。

GPT-5.4 nano 生成的自行车结构出现严重偏差,整体相对粗糙。

GPT-5.4 mini 的输出实现了核心需求,卡片错落排列,悬停有放大效果,视觉现代化;缺陷在于视差效果主要作用于背景和下方卡片,与卡片本身的联动不够明显,层次感稍弱。
GPT-5.4 nano 的输出实现了基本交互功能,但卡片空间层次与立体排列缺失,视差效果单一,深度感较弱。

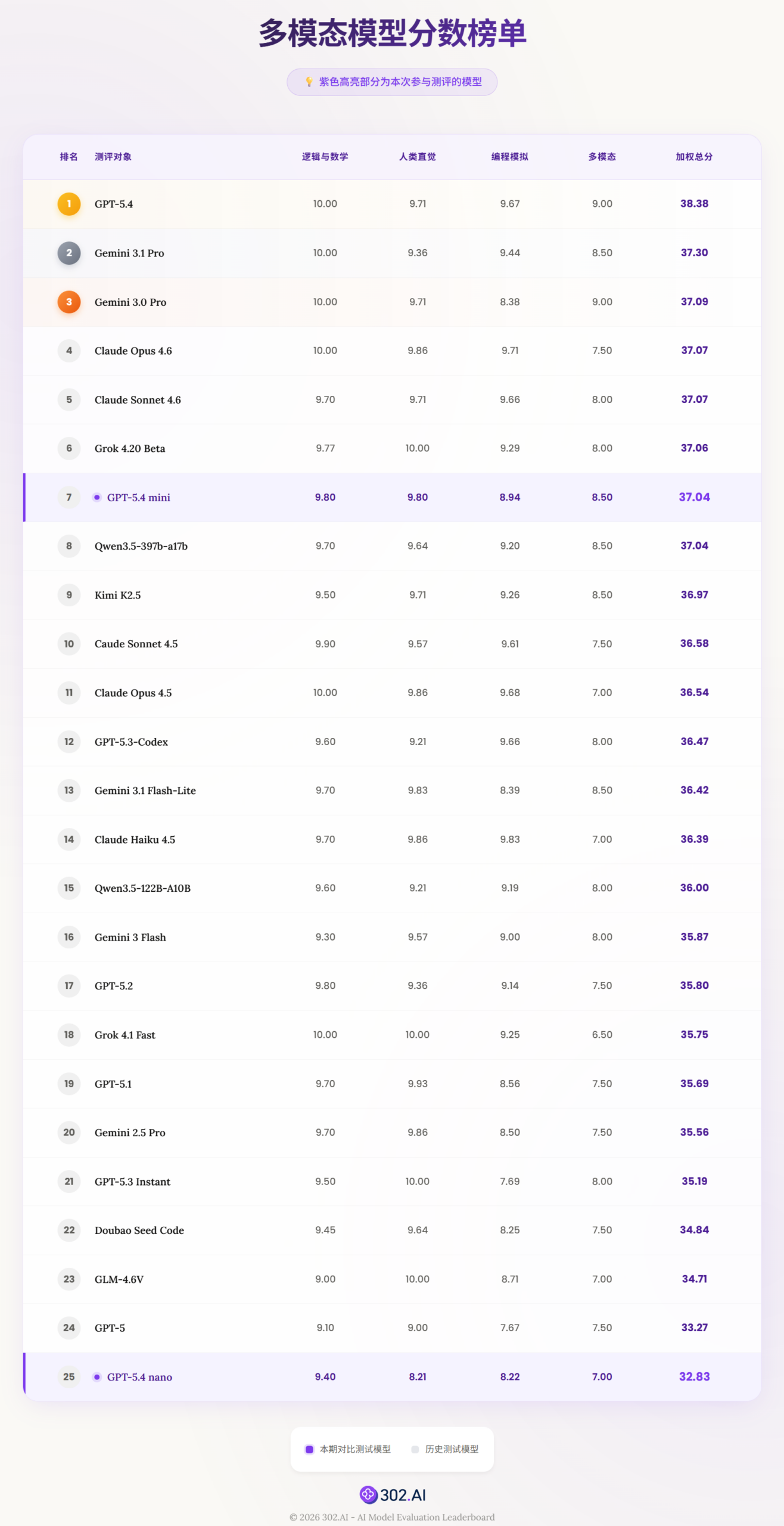
单从 benchmark 表现来看,GPT-5.4 mini 的能力曲线,已经在多个核心维度上逼近旗舰模型的上限——无论是逻辑推理还是多模态理解,其单点能力与 GPT-5.4 的差距正在迅速收敛。然而,在工程交付质量上,仍存在可感知的差距。
从官方 benchmark 来看(SWE-Bench Pro 54.4% vs 57.7%,OSWorld 72.1% vs 75.0%),GPT-5.4 mini 的性能已进入第一梯队,甚至在逻辑、人类直觉等维度上与旗舰模型的差异已缩至最小,这很容易产生一种直觉——mini 基本已经等价 GPT-5.4。
但只要把测试从 benchmark 拉回到具体案例,这个关系就会有所松动。
在 SVG 生成、前端 3D 卡片这些更偏工程化的案例中,mini 的表现其实很典型:它能准确理解需求,把核心结构搭建出来,而一旦进入细节层面,就会出现各种轻微但真实存在的问题——比如动效逻辑匮乏、组件联动性差、空间层次表达不充分。这些问题单看并不致命,但叠加在一起,很大程度削弱了其交付水平。
这种差距,本质上并不是能力缺失,而更像是稳定性的差距。mini 的角色近似一个执行效率极高的开发者——主干做得很好,但默认不会替你把所有角落都打磨得严丝合缝。
一句话概括:
Nano 和 Mini 之间并不是强和弱的关系,而是明显的能力分层。
从实测案例来看,这种分层其实特别清晰:一旦问题涉及到多模态空间推理、模糊意图理解,或者需要在多个约束之间做权衡,nano 就很容易在关键节点上出现偏差——不是完全能力不足,而是抓不住重点,或者在最关键的一步跑偏。
这点在官方数据里也有直接体现,比如 OSWorld 上 mini 和 nano 的差距几乎是断崖式的。这说明当任务变成“理解+推理+决策”的组合时,nano 很难维持稳定的表现。
但换个角度看,nano 在简单任务上的效率和成本优势又是显而易见的。分类、提取、排序、模板化生成,这类规则明确、路径单一的任务,nano 完成得足够快。
所以与其把它理解为 mini 的降级版,不如把它看成:
当 mini 和旗舰之间存在交付质量差距,而 nano 和 mini 之间又存在能力断层时,一个很自然的结论就出现了:这三类模型,本就不应该被当作同一层级的替代选项。在官方描述里,称之为“subagent 架构”。
因此更现实的做法是:
GPT-5.4 mini 并不能完全等同于旗舰模型,但它已经改变了旗舰模型的使用方式;而 nano 则进一步把成本效率推到了一个可以参与系统设计的维度。这也是这次发布真正有意思的地方:
模型之间的差距,正在从谁更强,变成谁更适合做哪一部分。
步骤指引:对话框内选择模型菜单

输入gpt 5.4 系列即可获取相应版本调用
步骤指引 :应用超市→聊天机器人→立即体验
选择模型:OpenAI模型→gpt-5.4 系列模型→确认
步骤指引:API超市→语言大模型→OpenAI→gpt-5.4 系列模型


点击【Playground】在线调用 API
想即刻体验 GPT-5.4 mini/nano 系列模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/248771.html