
做AI开发的朋友,应该都经历过这个阶段:为了调出理想的结果,反复打磨提示词,在"请用专业口吻"和"请说人话"之间来回折腾。
但风向变了。当大家还在卷提示工程(Prompt Engineering)时,一个更底层的概念已经冒出来了——上下文工程(Context Engineering)。
说白了,我们不再只问"怎么说能让AI听懂",而是开始想:给AI一个什么样的信息环境,它才能干出高质量的活?
特别是现在Agent越来越多,任务越来越复杂,指望AI能自主搞定一件事,上下文工程的重要性就愈发明显了。
你可能遇到过这种情况:让AI帮你重构一个代码库,最开始它答得挺好,但做到第三步就开始犯傻——不是忘了之前的修改,就是把完全不相关的东西混在一起。
这不全是模型变笨了,而是上下文出了问题。
Agent的特殊性:多轮推理的上下文累积
对于单轮问答应用,上下文管理相对简单。但Agent不是单轮的——一个任务往往要经过数十轮甚至上百轮推理循环。
Anthropic的Claude Code在处理复杂任务时,平均会进行50次工具调用。Manus团队的数据也显示,典型任务平均要调用50次工具。这意味着什么?
每一轮都会产生三类信息:
- 工具调用参数:模型决定调用什么工具、传什么参数
- 工具返回结果:代码片段、错误日志、文件内容、网络请求结果
- 中间推理:模型的思考过程、决策依据
这些信息会不断累积在上下文中。50轮下来,上下文可能膨胀到数万token——而这还只是一个普通任务的量级。
上下文窗口的挑战
你可能会说:现在的模型上下文窗口不是已经达到百万token了吗?
窗口大不等于问题解决。虽然前沿模型的上下文窗口越来越大,但随着上下文变长,模型性能会明显下降。这不是因为容量不足,而是因为噪声太多导致关键信息被淹没,注意力被稀释。
这就是Agent开发的核心矛盾:上下文窗口有限,但运行中产生的信息不断膨胀。
有研究专门测试了这个现象,叫"needle in a haystack" benchmark——在一大堆无关信息里找关键细节。结果发现,随着token数量增加,模型的召回准确率会持续下降。研究人员把这种现象称为上下文衰减(context rot)。
大模型看起来很强大,但它其实有个注意力预算——就像人的工作记忆一样,能同时处理的信息量是有限的。每一个新token都在消耗这个预算。
这说明啥?
不做上下文工程,一个普通的多步骤任务就能把模型搞崩。哪怕窗口有一百万token也白搭,上下文衰减是架构层面的硬伤,不是扩大窗口就能解决的。
先搞清楚一个常见误区:上下文工程不是提示词工程的替代品,而是它的自然演进。
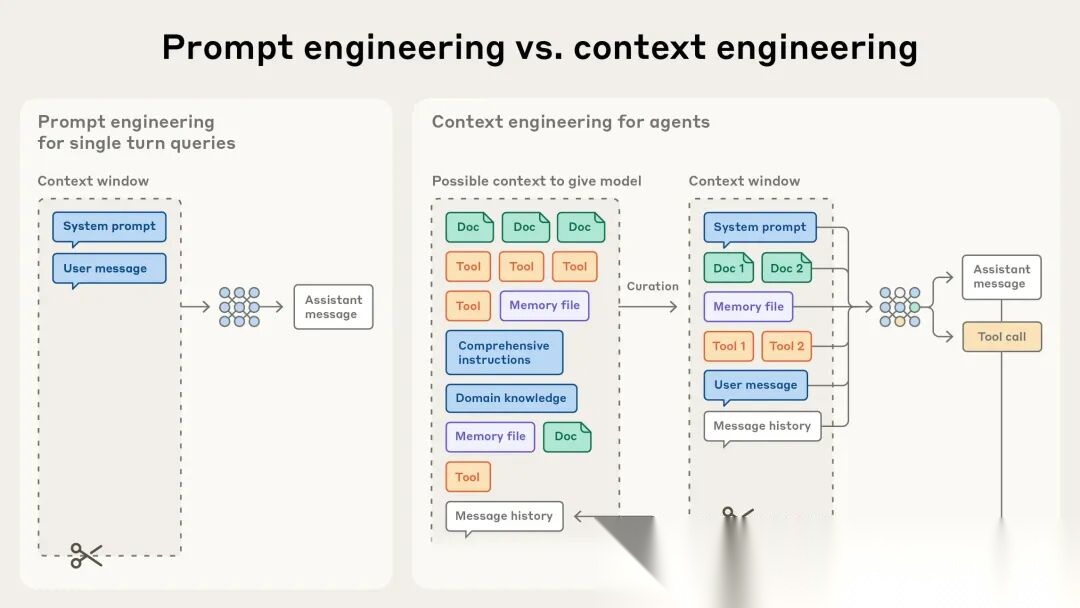
这张图很清晰地说明了两者的关系:提示词工程是上下文工程的一个子集。
关注点的转变
提示词工程(Prompt Engineering)关注的是"如何措辞"——怎么组织语言、怎么写指令、怎么用few-shot示例、怎么设计chain-of-thought。它的核心问题是:“用什么词能让模型听懂?”
上下文工程(Context Engineering)关注的是"给什么信息"——系统指令、工具定义、MCP配置、外部数据、消息历史、动态加载策略……它的核心问题是:“什么样的信息环境最能让模型产生期望的行为?”
上下文工程包含了一个以前被忽视的关键问题:信息的选择和动态管理。
工作模式的本质差异
这两者的区别,不只是范围大小的问题,更是工作模式的根本不同:
提示词工程是"写好一个prompt,完事儿"。上下文工程是"每做一次推理,都要决定往上下文里放什么"。
一个是静态的措辞优化,一个是动态的信息策展(curation)。
为什么这个区别很重要?
在早期的LLM应用开发中,大多数用例都是一次性的:情感分析、文本摘要、代码生成。这时候提示词工程确实够用了。
但当你构建Agent时,情况完全不同。Agent在循环中运行,每一轮都会产生新的数据,这些信息"可能"与下一轮推理相关。你需要不断决定:哪些保留、哪些丢弃、哪些需要动态加载。
这就像经营一家图书馆:提示词工程关心的是怎么写借书规则(措辞优化),而上下文工程关心的是图书馆里放什么书、怎么分类、怎么根据读者需求动态推荐(信息管理)。
Agent越复杂,后者的权重就越高。
定义:管理大模型的工作记忆
上下文工程,简单说就是管理大模型工作记忆的系统方法。
要理解这一点,先要搞清楚大模型的信息来源。模型在推理时能用的信息只有两个:
- 参数知识:训练阶段学到的,推理时无法改变
- 上下文窗口:当前输入的内容,这是我们唯一能控制的
上下文工程本质上是在构建大模型的工作记忆——它决定了模型能"看到"什么、基于什么做决策。
你可以把上下文想象成一块黑板:
- 黑板上写的是各种信息(指令、数据、历史记录)
- 黑板空间有限(上下文窗口限制)
- 写得太满,重点就被淹没了(注意力稀释)
所以上下文工程的核心问题不是"怎么写这句话",而是“哪些信息值得放进去”。
核心原则:最小高信噪比集合
Anthropic给过一个精炼的定义:上下文工程的目标是找到最小的高信噪比token集合,以最大化达成期望结果的可能性。
拆解一下:
- 最小:不是越多越好,而是够用就行
- 高信噪比:信息密度高,噪声少
- token集合:以token为单位衡量,因为模型的注意力预算就是按token计算的
一个具体例子
假设你要让AI重构一个复杂代码库:
错误做法:把几百个文件的代码片段全塞进去。结果?模型被淹没在细节里,抓不住重点。
正确做法:只放三个关键信息:
- 当前遇到的核心问题是什么
- 重构的目标是什么
- 有什么约束条件(不能破坏的接口、依赖关系等)
模型反而能给出更清晰、更有针对性的方案。
这就是上下文工程的基本哲学:少即是多。
理论说了一堆,来看怎么落地。我结合Anthropic的文章和业界的做法,总结了四大技术方向。
一、基础层:上下文组件设计
在谈高级技术之前,先确保基础组件设计合理。
这张图展示了上下文的典型层次结构。从下到上,信息从稳定到动态、从通用到具体。理解这个结构,有助于我们更好地组织和管理上下文。
1. 系统提示(System Prompt)
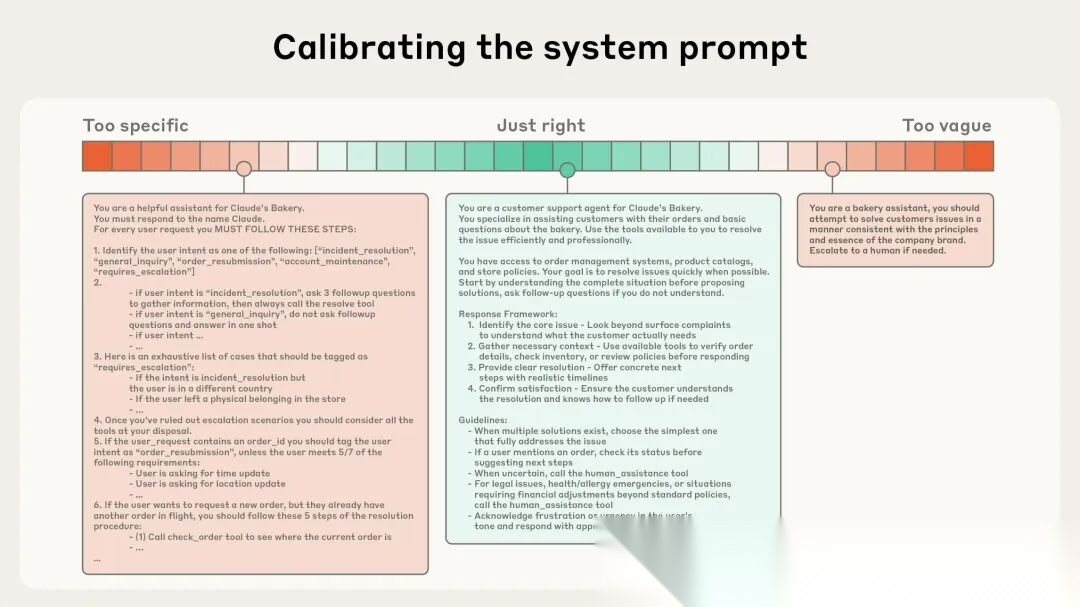
写系统提示就像调收音机,要找到那个"刚刚好"的频点:
- 调太低(过于具体):硬编码一堆if-else逻辑,提示词又臭又长。稍微变个场景就失效,维护起来想死。
- 调太高(过于笼统):说什么"请专业地完成任务",模型听完一脸懵——到底啥叫"专业"?
- 刚刚好:给清楚目标和约束,但别把每一步都规定死。让模型有发挥空间,又能按你期望的方向走
实践建议:
- 用XML标签或Markdown标题组织不同部分(
Tool guidance等) - 从最小提示开始测试,根据失败模式逐步添加指令和示例
- 最小不等于最短,要提供足够的前置信息确保行为正确
2. 工具设计(Tools)
工具是Agent与环境的契约,设计原则:
- 功能聚焦:每个工具职责清晰,功能重叠最小化
- 自包含:像设计好的代码函数一样,健壮、明确
- 参数描述:输入参数要描述性、无歧义,发挥模型的固有优势
常见陷阱:工具集臃肿,覆盖太多功能或导致选择困难。如果人类工程师都无法判断该用哪个工具,AI也不行。
3. 示例选择(Examples)
少样本示例(few-shot)仍然是强烈建议的**实践,但要注意:
- 不要:塞入一长串边缘情况,试图覆盖所有规则
- 要:策划多样化、典型的示例,有效展示预期行为
- 对LLM来说,示例就是"价值千言"的照片
二、运行时层:动态上下文检索
核心思想:不要预加载所有数据,而是让Agent按需获取。
JIT Context(即时加载)
与其预先把所有相关数据塞进上下文,不如让Agent维护轻量级标识符(文件路径、存储的查询、网络链接等),在运行时通过工具动态加载。
案例:Claude Code处理大型代码库时,不预加载所有文件,而是提供grep、glob、read等工具。模型需要哪个文件,就现场搜索、现场读取。这还规避了索引过时的问题。
渐进式披露(Progressive Disclosure)
让Agent通过探索逐步发现相关上下文:
- 文件大小暗示复杂度
- 命名约定暗示用途
- 时间戳可以代表相关性
Agent层层构建理解,只在工作记忆中保留必要部分。
混合策略
最有效的Agent往往采用混合策略:
- 预检索一些数据保证速度(如CLAUDE.md文件)
- 同时保留自主探索能力(如glob、grep工具)
"正确"的自主程度取决于任务特性。
三、长程任务层:突破上下文窗口限制
对于跨越数分钟到数小时的任务(如大型代码库迁移、综合研究项目),需要专门技术绕过上下文限制。
1. 压缩(Compaction)
当对话接近上下文窗口限制时,总结内容并用摘要重启新窗口。
实现方式:
- 将消息历史传给模型,让其总结最关键的细节
- 保留:架构决策、未解决的bug、实现细节
- 丢弃:冗余的工具输出、已处理的消息
案例:Claude Code自动压缩历史对话,保留摘要+最近访问的5个文件,用户完全感知不到上下文已"重启"。
调优建议:
- 先最大化召回率(确保捕获所有相关信息)
- 再迭代提高精确率(消除多余内容)
- 最安全的轻量级压缩:清除历史深处的工具调用结果
2. 结构化笔记(Structured Note-Taking)
Agent定期将笔记写入并持久化到上下文窗口之外,需要时再拉回。
案例:Claude玩宝可梦时,在数千步游戏中保持精确计数——走了多少步、宝可梦升了几级、解锁了哪些成就、战斗策略笔记。上下文重置后读取笔记就能继续数小时的训练序列。
本质:以最小开销提供持久记忆,相当于给AI接了一个无限大的外存。
3. 子Agent架构(Sub-agent Architectures)
主Agent协调高级计划,子Agent用干净的上下文窗口处理专注任务。
工作流程:
- 子Agent深入技术工作,可能使用数万个token探索
- 只返回压缩、精炼的摘要(通常1000-2000 token)
- 详细搜索上下文保留在子Agent内部,不污染主上下文
案例:Manus采用Planner + Knowledge Manager + Executor架构,实现关注点分离。
三种技术的选择:
- 压缩:需要大量来回交互的任务,保持对话流程
- 笔记:有明确里程碑的迭代开发
- 子Agent:复杂研究和分析,并行探索能带来收益
四、优化层:成本控制与性能
Prompt Caching(提示缓存)
把稳定的系统指令和工具定义放在前缀位置,启用缓存复用KV表示。
效果:Anthropic数据显示,启用缓存后可降低90%的输入成本。
做法:
- 稳定部分(系统提示、工具定义)放在最前面
- 变化部分(用户消息、历史记录)追加在后面
总结:如何选择(一般来说是综合使用)
记住一个原则:怎么简单怎么来,管用就行。模型能力越来越强,需要的花活会越来越少。但不管技术怎么变,把上下文当成稀缺资源来看待,这个核心思想不会过时。
上下文工程代表着构建 LLM 应用的方式正在发生根本性转变。模型能力越强,挑战越不是"怎么写prompt",而是"怎么安排信息进模型的注意力预算"。不管是压缩长任务上下文、设计省token的工具,还是让Agent即时探索环境,核心原则都一样:找到最小的高信息密度集合,最大化达成目标的概率。
这些技术会随模型进化而演变。更聪明的模型需要更少的人工预设,Agent能跑得更自主。但不管模型多强,把上下文当稀缺资源对待,始终是构建可靠Agent的核心。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/244838.html