
Claude Skills是Anthropic为Claude大语言模型推出的一种模块化能力扩展系统(技能包),旨在教Claude如何执行特定、重复性的工作流程。它将特定的指令、脚本和资源封装在独立文件夹中,让 Claude 能够在需要时按需调用,从而实现自动化、标准化处理任务,节省大量上下文 Token。是基于文件系统的可重用资源,为 Claude 提供特定领域的专业知识:工作流程、上下文和**实践,可将通用代理转变为专家。与提示词(针对一次性任务的对话级指令)不同,技能按需加载,无需在多个对话中重复提供相同的指导。它将特定任务相关的指令、脚本、模板和资源等内容,封装成一个文件夹,称为一个Skill。
工作原理(三层加载机制)
触发逻辑:Claude 扫描 available_skills 列表,比对用户请求与每个 Skill 的 description,匹配则自动加载对应 SKILL.md
目前内置的公开Skills
3.1 解决 Claude 的"通才局限"
Claude 默认是通才,对很多专业任务(如生成 .docx、创建 .pptx、操作 Excel)只有模糊知识。Skill 把经过反复打磨的**实践固化成文字,让 Claude 每次都能按专家级流程操作。
3.2 避免重复"发明轮子"
没有 Skill 时,Claude 每次都可能选择不同的库、不同的方法,导致结果不稳定。Skill 规定了"应该用哪个库、怎么做、踩过哪些坑",输出质量大幅提升且一致。
3.3 封装复杂流程
复杂任务往往需要多个步骤(解压 → 编辑 XML → 重新打包)。Skill 把这些步骤全部写清楚,Claude 不需要"自己摸索",直接按图索骥。
3.4 渐进式加载,不浪费上下文
Skill 采用三层加载机制:
•第一层:元数据(name + description),始终在上下文中,约100字
•第二层:SKILL.md 正文,触发时加载,建议500行以内
•第三层:附属资源文件,按需加载,没有上限
这意味着:Skills 只在需要时消耗上下文,平时几乎"零开销"。
3.5 可分享、可迭代
Skill打包成.skill文件后可以安装到Claude,团队成员之间可以共享,也可以持续改进。
标准目录结构
GPT plus 代充 只需 145my-skill/ ← Skill 根目录(文件夹名即 Skill 名)
├── SKILL.md ← 必须,核心指令文件 ├── LICENSE.txt ← 可选,许可证 ├── scripts/ ← 可选,可执行的脚本(Python/Bash等) │ └── process.py ├── references/ ← 可选,参考文档(大型文档放这里按需加载) │ ├── guide-a.md │ └── guide-b.md └── assets/ ← 可选,模板、字体、图片等静态资源
└── template.xlsx
目录组织原则:
scripts/:放可执行代码,用于确定性、重复性任务
references/:放按需加载的参考文档(超过 300 行建议加目录)
assets/:放输出时会用到的静态文件(模板、图标、字体等)
SKILL.md格式
SKILL.md 由两部分组成:YAML 前置元数据 + Markdown 正文指令。
GPT plus 代充 只需 145
---
name: skill-name ← Skill 唯一标识符 description: 触发条件和功能描述。 ← 触发机制的核心!要写得"积极" 当用户提到…时使用本 Skill。 ← 越具体越好
license: LICENSE.txt ← 可选
Skill 标题
简介
说明这个 Skill 是干什么的。
工作流程
步骤 1:… 步骤 2:…
参考资料
- 详细指南请查看 references/guide.md
GPT plus 代充 只需 145
Step 1:确定 Skill 的目标
回答这三个问题:
•这个Skill要让Claude做什么?
•什么情况下应该触发(用户会说什么词/短语)?
•期望输出是什么格式?
Step 2:创建目录和 SKILL.md
GPT plus 代充 只需 145mkdir my-skill
touch my-skill/SKILL.md
Step 3:编写 SKILL.md
按以下模板填写:
GPT plus 代充 只需 145
name: my-skill
description: 描述本技能的功能和触发条件。当用户想要…时使用本 Skill,
包括…、…等场景。即使用户没有明确说出技能名,只要涉及…也应触发。
My Skill 标题
概述
简短描述。
前置要求
- 需要的库:xxx
- 需要的工具:xxx
工作流程
第一步:分析输入
…
第二步:执行处理
…
第三步:输出结果
…
常见问题和注意事项
- 注意点 1
- 注意点 2
参考资料
详细文档见 references/detail.md
GPT plus 代充 只需 145 Step 4:添加脚本和资源(可选)
如果任务需要运行代码:
GPT plus 代充 只需 145mkdir my-skill/scripts
在 scripts/ 下添加 Python/Shell 脚本
Step 5:测试与迭代
手动测试:用几个典型的用户请求,验证 Claude 是否:
✅ 正确触发(看到 Skill 并读取)
✅ 按 Skill 指引执行
✅ 输出符合预期
Step 6:打包发布
GPT plus 代充 只需 145# 使用 skill-creator 技能中的打包脚本 python -m scripts.package_skill my-skill/ # 生成 my-skill.skill 文件,可以安装和分享
前置准备
基于closeAi中转站,搭建skills,platform.closeai-asia.com/dashboard
开始之前,确保已经拥有:
1.一个CloseAI 账户。
2.一个 CloseAI API Key。您可以在您的账户仪表板中找到它。
3.已安装Node.js 和 npm。
macOS/Linux 用户配置指南
第一步:安装 Claude Code
运行claude官方安装命令,需要开启梯子
GPT plus 代充 只需 145curl -fsSL https://claude.ai/install.sh | bash
备选方案,如果因为网络不通等问题,也可以使用 npm (Node Package Manager) 在您的系统上全局安装 Claude Code。打开您的终端并运行以下命令:
npm install -g @anthropic-ai/claude-code
安装完成后,您就可以在终端的任何位置使用claude命令了。
第二步:配置 CloseAI 接入
通过~/.claude/settings.json配置环境变量,这种方式最稳定可靠,无需配置系统环境变量,避免各种环境变量冲突问题。
- 创建配置目录
GPT plus 代充 只需 145
mkdir -p ~/.claude
- 编辑 settings.json
GPT plus 代充 只需 145
在您喜欢的文本编辑器中打开~/.claude/settings.json文件,添加以下内容:
GPT plus 代充 只需 145{
"env": {
"ANTHROPIC_API_KEY": "sk-xxxxxxxxxxxxxxxx", "ANTHROPIC_BASE_URL": "https://api.openai-proxy.org/anthropic", "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" }
}
GPT plus 代充 只需 145
配置说明:
•ANTHROPIC_API_KEY设为您的 CloseAI API Key(请务必替换 sk-xxxxxxxxxxxxxxxx)
•ANTHROPIC_BASE_URL设为 CloseAI 的 API 地址
•CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS设为1可禁用过新的实验性 Beta 功能,避免因使用尚不稳定的测试特性而导致的意外报错
•重要 :配置文件中,不要添加 apiKeyHelper字段,否则会导致配置冲突
这种配置方式会覆盖系统环境变量,确保 100% 正常工作,无需额外配置系统环境变量。
第三步:免登录配置
Claude Code 首次启动时会需要你登录Claude官方账号,你如果挂了VPN,会弹出登录,如果没挂VPN会直接报错:Failed to connect to api.anthropic.com。
为了跳过登录,我们需要在 ~/.claude.json 中,加入设置"hasCompletedOnboarding": true。如果不跳过登录,则会在第一次使用 claude 时,触发登录。
第四步:开始使用
现在,您可以在终端中启动 Claude Code 了:
GPT plus 代充 只需 145claude
启动后Claude会问你是否使用自定key,选择yes。
实现code review的skills
创建code review的skill目录
GPT plus 代充 只需 145mkdir -p ~/.claude/skills/code-review
创建SKILL.md文件
GPT plus 代充 只需 145touch ~/.claude/skills/code-review/SKILL.md
编辑SKILL.md文件
GPT plus 代充 只需 145---
name: code-review
description: 当用户要求代码审查、code review、看代码问题时使用;对指定文件或目录做风格、潜在 bug 与可读性检查
代码审查助手
何时使用
- 用户说「帮我 review 这段代码」「代码审查」「看看有没有问题」时
执行步骤
- 确认要审查的文件或代码范围。
- 依次检查:命名规范、潜在 bug、边界情况、可读性、简单性能问题。
- 用列表给出问题与修改建议,并标注严重程度(高/中/低)。
输出格式
- 先简要总结,再按文件/位置列出具体问题和建议。
效果
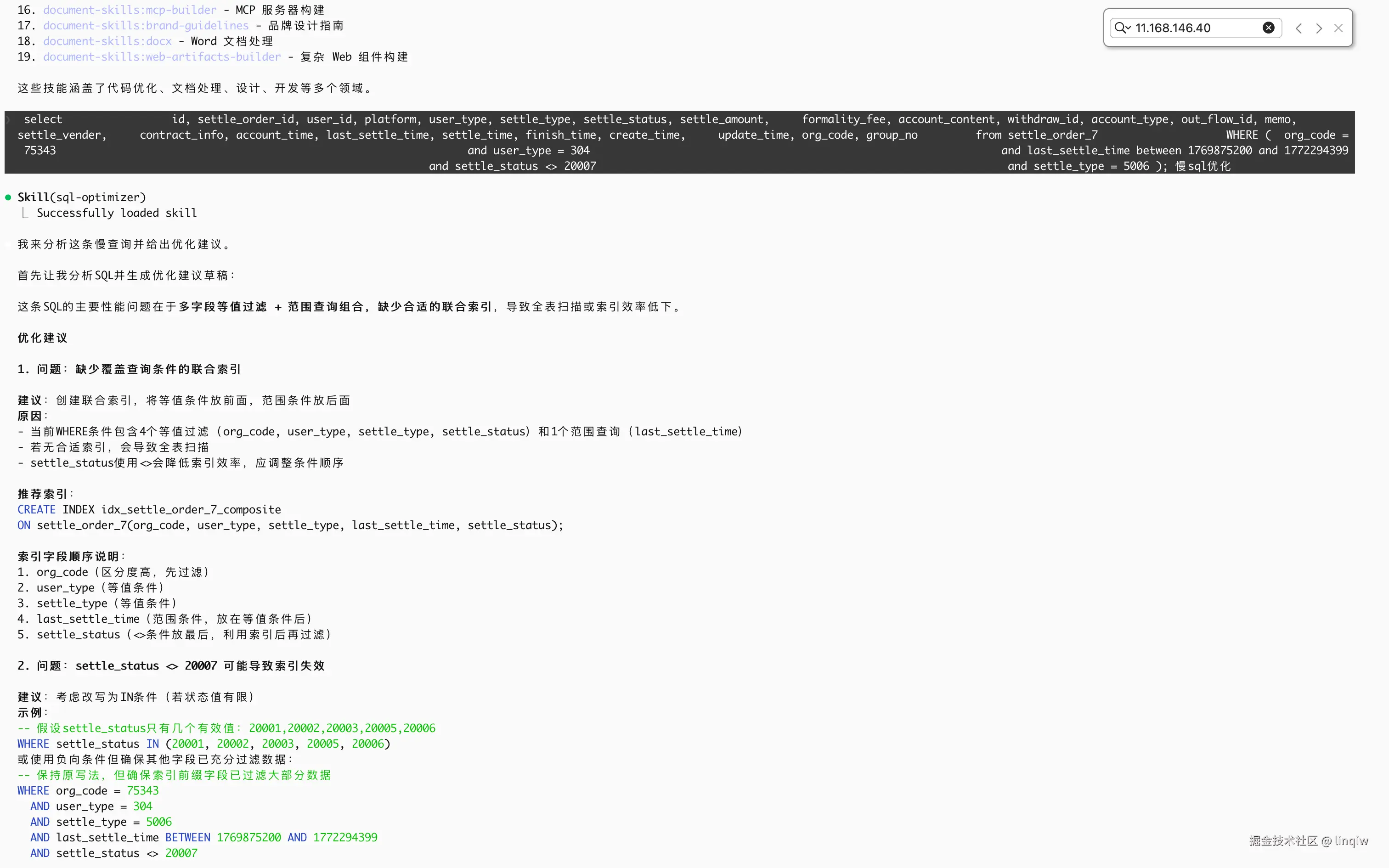
实现sql优化器的skills
创建sql优化器的skill目录
GPT plus 代充 只需 145
mkdir -p ~/.claude/skills/sql-optimizer
创建sql优化器skll目录里的脚本目录
GPT plus 代充 只需 145
mkdir -p ~/.claude/skills/sql-optimizer/scripts
创建SKILL.md文件
GPT plus 代充 只需 145
touch ~/.claude/skills/sql-optimizer/SKILL.md
编辑SKILL.md文件
GPT plus 代充 只需 145
---
name: sql-optimizer description: 当用户提供 SQL 或询问 SQL 优化、慢查询、索引、explain 时使用;给出优化建议与索引建议,并用 Python 脚本对回复做结构化与代码块优化
dependencies: python>=3.8
SQL 优化助手
何时使用
- 用户粘贴 SQL 或提到「优化」「慢」「explain」「索引」「查询性能」时
- 用户询问如何改写 SQL、加索引、分析执行计划时
执行步骤
- 理解上下文 :确认 SQL 的用途、涉及表与业务场景;必要时询问表结构或数据量。
- 分析 :从索引、WHERE 条件、JOIN、子查询、函数/类型转换、分页方式等方面分析。
- 产出草稿 :先一句话总结问题,再分条写出「问题 → 建议 → 示例(若适用)」。
- 用 Python 脚本优化回复 (必须执行):
- 将上一步的完整回复文本保存为临时文件,或通过管道传入脚本。
- 在技能目录下执行(技能目录为
~/.claude/skills/sql-optimizer 或当前项目 .claude/skills/sql-optimizer): GPT plus 代充 只需 145 python3 scripts/optimize_response.py
将草稿内容通过 stdin 传入,例如: echo "此处为草稿全文" | python3 scripts/optimize_response.py
或先写入文件再传路径: GPT plus 代充 只需 145 python3 scripts/optimize_response.py /path/to/draft.txt
- 脚本会:把未包裹的 SQL 统一成
sql ... 代码块,并补全「 优化建议」等章节。
- 输出 :将脚本的 stdout 作为最终回复呈现给用户,不要再手动改脚本输出内容。
输出格式(脚本会在此基础上做后处理)
- 开头:一句话总结主要问题。
- 中间:分条列出「问题 → 建议 → 示例(若适用)」;所有 SQL 示例保持为
sql ... 形式。
- 结尾:可补充索引建议、EXPLAIN 使用建议或后续可做的验证。
使用 Python 脚本的注意点
- 脚本路径:相对于本技能根目录的
scripts/optimize_response.py;若从项目根执行,则使用 .claude/skills/sql-optimizer/scripts/optimize_response.py。
- 必须把 完整草稿 (整段优化分析)传给脚本,不要只传其中一句。
- 最终给用户看的,以脚本 stdout 为准;若脚本报错,可退回为未优化版草稿并说明「本次未做响应后处理」。
示例流程
- 用户:
/sql-optimizer 并粘贴一条 SELECT。
- 你分析后写出草稿(总结 + 若干条建议 + SQL 示例)。
- 执行:
echo "
<草稿全文>
" | python3 .claude/skills/sql-optimizer/scripts/optimize_response.py
(或从技能目录执行 python3 scripts/optimize_response.py 并 stdin 传入草稿)。
- 把脚本输出作为最终回复发给用户。
创建optimize_response.py脚本文件
GPT plus 代充 只需 145
touch ~/.claude/skills/sql-optimizer/scripts/optimize_response.py
编辑optimize_response.py脚本文件
GPT plus 代充 只需 145
#!/usr/bin/env python3
""" SQL 优化建议响应后处理:读取 Claude 的优化分析草稿,输出结构化 Markdown。
- 将未包裹的 SQL 统一为
sql ... 代码块
- 确保有「总结」「优化建议」等章节结构
- 斜体:将 [i]…[/i] 转为 *…*;对「注意:」「例如:」等后的短句自动加斜体
- 红高亮:将 [r]…[/r] 转为红色 HTML;对「建议:」后的短句及「 优化建议」标题加红 """ import re import sys from pathlib import Path
def read_input() -> str:
GPT plus 代充 只需 145if len(sys.argv) > 1: p = Path(sys.argv[1]) if p.exists(): return p.read_text(encoding="utf-8") return sys.stdin.read()
def wrap_bare_sql(text: str) -> str:
"""把单独成段的 SQL(SELECT/INSERT/UPDATE 等开头)包成 sql ... """ lines = text.split("
")
GPT plus 代充 只需 145out = [] i = 0 while i < len(lines): line = lines[i] stripped = line.strip() if stripped.startswith(""): out.append(line) i += 1 continue if re.match(r"^(SELECT|INSERT|UPDATE|DELETE|CREATE|ALTER|EXPLAIN|WITH)s", stripped, re.I): out.append("sql") out.append(line) i += 1 while i < len(lines) and not lines[i].strip().startswith(""): out.append(lines[i]) i += 1 out.append("") if i < len(lines): out.append(lines[i]) i += 1 continue out.append(line) i += 1 return "
".join(out)
def ensure_sections(text: str) -> str:
"""若没有「 优化建议」,在第一个列表前插入""" if " 优化建议" in text or " 建议" in text: return text lines = text.split("
")
GPT plus 代充 只需 145for i, line in enumerate(lines): if re.match(r"^(d+.|[•-*])s", line.strip()): lines.insert(i, "") lines.insert(i + 1, " 优化建议") lines.insert(i + 2, "") return "
".join(lines)
return text
def apply_italic(text: str) -> str:
GPT plus 代充 只需 145""" 增加斜体能力(Markdown 使用 *...*): 1. 将显式标记 [i]...[/i] 转为 *...* 2. 对「注意:」「例如:」等后的第一个短句加斜体(「建议:」留给红高亮) """ text = re.sub(r"[i](.*?)[/i]", r"*1*", text, flags=re.DOTALL) for prefix in ("注意", "例如", "说明", "提示"): pattern = rf"({prefix}[::])([^
*`]+?)([。; ]|$)"
def _repl(m): content = m.group(2).strip() if not content or len(content) > 80: return m.group(0) end = m.group(3) return f"{m.group(1)}*{content}*{end}" text = re.sub(pattern, _repl, text) return text
RED_SPAN = ‘’
def apply_red_highlight(text: str) -> str:
GPT plus 代充 只需 145""" 对优化建议加红高亮: 1. [r]...[/r] -> 红色 span 2. 「建议:」后的短句 -> 红色 3. 「 优化建议」标题 -> 红色 """ text = re.sub(r"[r](.*?)[/r]", RED_SPAN + r"1", text, flags=re.DOTALL) pattern = r"(建议[::])([^
*`<]+?)([。; ]|$)"
def _repl(m): content = m.group(2).strip() if not content or len(content) > 100: return m.group(0) end = m.group(3) return f"{m.group(1)}{RED_SPAN}{content}{end}" text = re.sub(pattern, _repl, text) text = re.sub(r"(s*)(优化建议|建议)(s*)$", r"1" + RED_SPAN + r"23", text, flags=re.MULTILINE) return text
def main() -> None:
GPT plus 代充 只需 145raw = read_input() if not raw.strip(): print("(未收到输入)", file=sys.stderr) sys.exit(1) out = wrap_bare_sql(raw) out = ensure_sections(out) out = apply_italic(out) out = apply_red_highlight(out) print(out.strip())
if name == "main":
main()
效果 
除了自己编写,还可以利用2025年末发布的Agent Skills开放标准:
•官方市场:访问github.com/anthropics/...仓库下载预设的技能(如:pdf生成器、SQL 调优工具)。
•Skill Creator:你可以对 Claude 说:"帮我把我刚才教你的关于 Docker 的配置逻辑总结成一个 Skill",它会自动在相应目录为你生成文件。
我们可以将本仓库注册为 Claude Code 的插件市场,只需在 Claude Code 中执行以下命令:
GPT plus 代充 只需 145
/plugin marketplace add anthropics/skills
然后就可以使用/plugin查看:
装指定技能集的步骤:
•浏览并安装插件(Browse and install plugins)
•选择 anthropic-agent-skills 插件源
•选择 document-skills(文档技能) 或 example-skills(示例技能)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/244841.html