
前言 :
在上一篇博客中,我们见证了机器学习的神奇:几行代码,一条直线,就能预测房价。但现实往往比教程残酷得多。如果你直接拿真实的业务数据去跑那个
model.fit(),大概率会得到一个糟糕透顶的结果,甚至直接报错。业界流传着一句至理名言:"数据和特征决定了模型的上限,而算法只是在逼近这个上限。"
这意味着,无论你用多先进的深度学习模型,如果输入的数据是垃圾,输出的一定也是垃圾(Garbage In, Garbage Out)。本篇作为"机器学习实战四部曲"的第二篇,我们将深入机器学习的"后厨",揭秘那些占据数据科学家 80% 时间的核心工作:数据预处理 与特征工程。这里没有高大上的神经网络,只有清洗、转换和提炼的"脏活累活",但这正是让模型从"人工智障"变"人工智能"的关键一步。
文章目录
想象一下,你要训练一个模型来预测用户是否会购买某款产品。你拿到的原始数据表可能是这样的:
一眼望去,全是坑:
- 缺失值:U002 的年龄是空的,U004 的标签未知。
- 异常值:U003 的年龄是 150 岁?收入是负数?这显然是录入错误。
- 格式不统一 :日期格式有的用
-,有的用/,有的用英文单词;性别有的写"男",有的写"M",有的写"女性"。 - 非数值型数据:机器学习模型(如线性回归、 SVM)本质上是在做矩阵运算,它们看不懂"男/女"或"2023-01-01",只认识数字。
如果不处理这些直接扔给模型,后果不堪设想。因此,我们需要一套标准化的"清洗流水线"。
1. 处理缺失值 (Missing Values)
数据缺失是常态。处理方法主要有两种策略:
- 删除法:如果缺失比例极高(比如某列 80% 都是空),或者该样本其他关键信息也缺失,直接丢弃该行或该列。
- 填充法 (Imputation):保留数据,用合理的值填补空缺。
- 数值型 :通常用均值 (Mean)或中位数(Median)。中位数对异常值不敏感,更稳健。
- 类别型 :通常用众数(Mode,出现最多的值)或填充为"未知"。
GPT plus 代充 只需 145import pandas as pd
import numpy as np from sklearn.impute import SimpleImputer
构造一个有缺失值的简单数据集
data = {‘age’: [25, 30, np.nan, 45, 20],
'income': [5000, 6000, 5500, np.nan, 4800]}
df = pd.DataFrame(data)
print("原始数据:") print(df)
策略:用中位数填充 age,用均值填充 income
imputer_age = SimpleImputer(strategy=‘median’) imputer_income = SimpleImputer(strategy=‘mean’)
df[‘age’] = imputer_age.fit_transform(df[[‘age’]]) df[‘income’] = imputer_income.fit_transform(df[[‘income’]])
print(" 填充后的数据:") print(df)
输出中,age 的 NaN 会被替换为剩余年龄的中位数 (25, 20, 30, 45 -> 排序 20,25,30,45 -> 中位数 27.5)
GPT plus 代充 只需 145
2. 处理异常值 (Outliers)
像那个"150 岁"的数据,会严重拉偏模型的拟合线。
- 检测方法 :常用 3σ原则 (超过均值 3 个标准差)或 箱线图(IQR,四分位距)。
- 处理手段 :
- 直接删除该样本。
- 将其修正为边界值(例如,把 150 岁强行改为最大合理值 90 岁)。
- 取对数转换,压缩极端值的范围。
计算机只认识数字。对于"性别"、"城市"、"颜色"这类类别特征(Categorical Features),我们必须把它们转化为数字。
1. 标签编码 (Label Encoding)
简单粗暴地给每个类别分配一个整数 ID。
- 男 -> 0, 女 -> 1
- 北京 -> 0, 上海 -> 1, 广州 -> 2
- 缺点:引入了错误的"大小关系"。模型可能会误以为 广州(2) > 北京(0),或者 上海是北京的 1 倍大。这在逻辑上是不通的。
- 适用场景:有序类别(如:低->0, 中->1, 高->2)。
2. 独热编码 (One-Hot Encoding) —— 推荐
将每个类别展开成一个新的二进制列(0 或 1)。
- 原数据:[北京,上海,广州]
- 转换后:
- 是北京?[1, 0, 0]
- 是上海?[0, 1, 0]
- 是广州?[0, 0, 1]
这样就没有大小之分了,每个城市都是平等的维度。
GPT plus 代充 只需 145from sklearn.preprocessing import OneHotEncoder
假设这是城市列
cities = np.array([[‘北京’], [‘上海’], [‘广州’], [‘北京’], [‘上海’]])
encoder = OneHotEncoder(sparse_output=False) # sparse_output=False 表示返回密集数组 result = encoder.fit_transform(cities)
print("独热编码结果:") print(encoder.get_feature_names_out([‘city’])) print(result)
输出将是三列,分别代表 is_北京,is_上海,is_广州
这是一个新手最容易忽略,但影响巨大的步骤。
假设我们要预测房价,有两个特征:
- 面积:50 ~ 200 (平米)
- 价格:3,000,000 ~ 10,000,000 (元)
如果你画个图,会发现"价格"轴的刻度跨度是"面积"的几万倍。在使用基于距离 的算法(如 KNN、K-Means)或基于梯度下降的算法(如线性回归、神经网络)时,数值大的特征会主导整个计算过程,导致模型完全忽略数值小的特征。
解决方案:
- 归一化 (Min-Max Scaling):把数据压缩到 [0, 1] 区间。

- 标准化 (Standardization / Z-Score):把数据变成均值为 0,标准差为 1 的分布。
这是最常用的方法,因为它对异常值不那么敏感,且符合很多算法的假设。
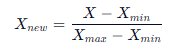
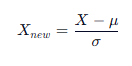
GPT plus 代充 只需 145
from sklearn.preprocessing import StandardScaler
构造两个量级差异巨大的特征
X = np.array([[100, ],
GPT plus 代充 只需 145 [120, ], [80, ]])
scaler = StandardScaler() X_scaled = scaler.fit_transform(X)
print("原始数据第一列均值:", X[:, 0].mean()) print("标准化后第一列均值:", X_scaled[:, 0].mean()) # 应该非常接近 0 print("标准化后的数据: ", X_scaled)
经过这一步,面积和价格就在同一个数量级上"公平竞争"了,模型的收敛速度会快得多,效果也会更好。
清洗和编码只是基础,真正的特征工程 (Feature Engineering) 是利用领域知识创造新特征的过程。这是区分普通工程师和顶级专家的分水岭。
案例:从"注册时间"挖掘价值
原始数据只有一个 2023-01-15 14:30:00。
直接把这个字符串转成数字(时间戳)意义不大。但如果我们拆解它:
- 特征 A :是周末吗?(0/1) -> 周末用户购买意愿可能更高
- 特征 B :是白天还是晚上?(0/1) -> 深夜用户可能更冲动
- 特征 C :距离现在过去了多少天? -> 新用户 vs 老用户
GPT plus 代充 只需 145
# 简单的特征构造示例
df[‘register_date’] = pd.to_datetime([‘2023-01-15’, ‘2023-02-20’, ‘2023-03-10’]) df[‘is_weekend’] = df[‘register_date’].dt.dayofweek.apply(lambda x: 1 if x >= 5 else 0) df[‘user_tenure_days’] = (pd.Timestamp.now() - df[‘register_date’]).dt.days
print(df[[‘register_date’, ‘is_weekend’, ‘user_tenure_days’]])
GPT plus 代充 只需 145 你看,原本无用的时间戳,变成了两个极具业务含义的特征。模型利用这些特征,能更精准地捕捉用户行为模式。
在处理完数据准备训练前,必须理解两个核心概念,它们贯穿机器学习始终:
- 欠拟合 (Underfitting):
- 表现:模型太简单,连训练数据都学不会。就像学生没好好读书,考试不及格。
- 原因:特征太少、模型复杂度不够。
- 对策:增加特征、换更复杂的模型。
- 过拟合 (Overfitting):
- 表现:模型在训练集上表现完美(准确率 99%),但在测试集上一塌糊涂。就像学生死记硬背了课本答案,题目稍微一变就不会了。
- 原因:模型太复杂,把数据里的"噪声"也当成了规律学进去了。
- 对策 :
- 更多数据:让模型见多识广。
- 减少特征:去掉无关干扰。
- 正则化 (Regularization):在损失函数中加惩罚项,限制模型参数不要太大(后续篇章详解)。
- 交叉验证:更科学地评估模型。
至此,我们已经拥有了干净、规范、富含信息量的数据集。万事俱备,只欠东风。
在第三篇博客中,我们将正式进入算法的深水区:
- 训练集与测试集:为什么要切分数据?如何科学地划分?
- 核心算法详解:深入剖析逻辑回归、决策树、随机森林等经典算法的内部原理(不再只是调用库)。
- 评估指标:准确率(Accuracy)真的可靠吗?什么是精确率(Precision)、召回率(Recall)和 F1 分数?ROC 曲线又是什么?
- 超参数调优:如何利用网格搜索(Grid Search)找到模型的**配置?
数据已经准备好,接下来,让我们看看算法是如何在这些数据上"施展魔法",以及我们如何客观地评判这个魔法的好坏。敬请期待!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/244828.html