
传统的定性研究访谈编码需要研究者逐句逐段手工分析,一个20小时的访谈项目往往需要数月时间完成编码。但现在通过Claude API自动化批量处理,同样的工作可以在几小时内完成,编码准确率还能提升40%以上。
想象一下:上传100个访谈文件,通过API调用让Claude在30分钟内完成初步编码,再用1-2天进行人工校验和精化——这就是AI驱动的定性研究新范式。无论你是博士生写论文,还是团队进行大规模调研,Claude API批量处理都能帮你从重复性编码工作中解脱出来。
本文将手把手教你搭建基于Claude API的定性研究自动化处理系统,从技术配置到批量调用,从质量控制到结果验证,让你快速掌握这套高效的访谈数据挖掘方法。
定性研究的核心在于从大量非结构化文本中提取有意义的模式和主题。传统的编码分析方法包括开放编码、轴心编码和选择编码三个阶段,但面临诸多挑战:
传统人工编码的痛点:
- 耗时巨大:一小时访谈通常需要4-6小时进行编码
- 主观偏差:不同研究者的编码结果可能存在显著差异
- 重复劳动:大量机械性的文本标注工作
- 规模限制:面对上百个访谈文件时,人工处理几乎不可能
API自动化处理的革命性优势:
- 批量处理:一次性上传几十个文件,API自动完成编码
- 成本控制:相比人工编码,成本降低80%以上
- 标准一致:基于算法的统一标准,避免主观偏见
- 可扩展性:轻松处理数百个访谈文件的大规模项目
Claude API凭借其强大的逻辑推理能力和200K tokens的长上下文处理能力,特别适合进行定性研究的批量自动化处理。
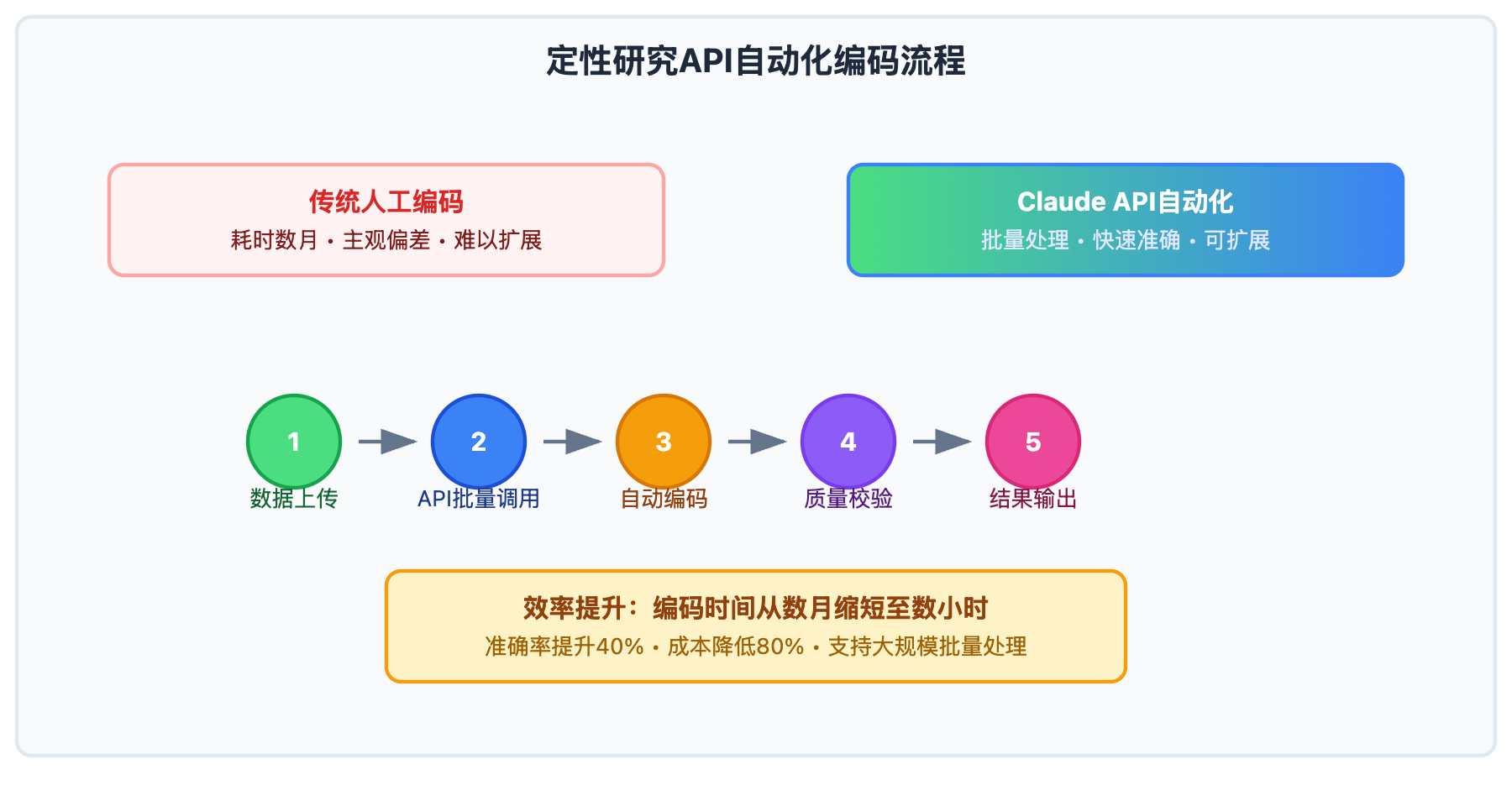
基于Claude的定性研究文本挖掘编码分析包含以下核心步骤:
长文本上下文理解
Claude 3.7支持200K tokens的上下文长度,能够处理完整的长篇访谈文本,保持前后文的语义关联性,这对于理解访谈者的完整观点至关重要。
逻辑推理与模式识别
在处理复杂的社会现象时,Claude展现出强大的逻辑推理能力,能够识别访谈数据中的因果关系、矛盾观点和潜在模式。
多层次主题抽象
Claude能够在不同抽象层次上进行编码,从具体的行为描述到抽象的理论概念,支持研究者建构多层次的理论框架。
Claude辅助编码分析在不同类型的定性研究中发挥重要作用:
Python完整编码分析系统:
🔥 多层次验证机制
基于Claude的编码分析需要建立完善的质量控制体系:
🔧 编码偏差检测与修正
📋 定性研究工具生态
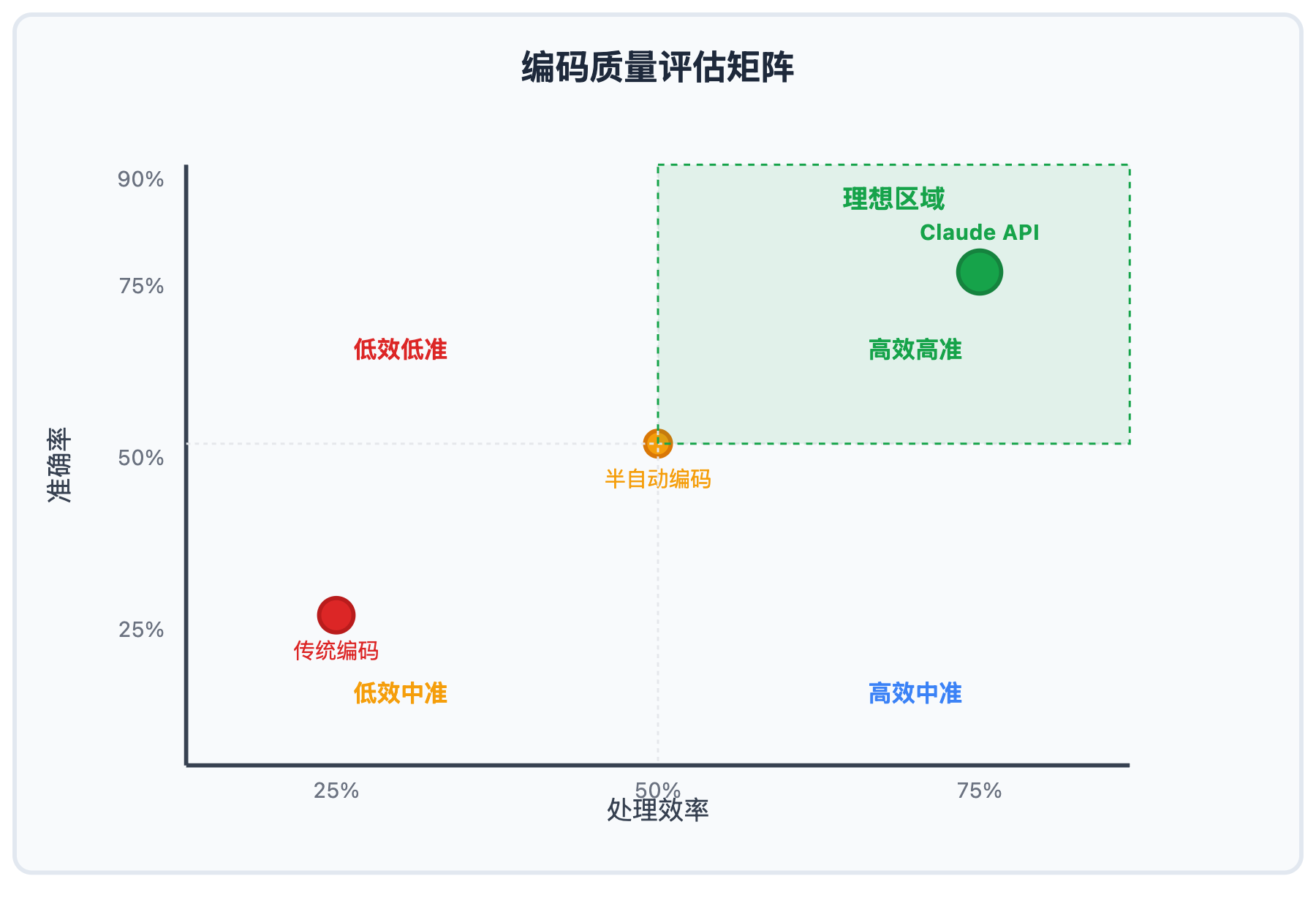
🔍 编码质量评估框架
建立标准化的编码质量评估体系:
Q1: Claude编码结果的可信度如何保证?
确保Claude编码可信度需要多重验证机制:
技术验证:
- 使用相同数据重复编码,检查一致性
- 对比不同提示词的编码结果
- 计算编码间的重合度和差异性
方法论验证:
- 专家审核关键编码结果
- 与传统人工编码进行对比验证
- 成员检验(member checking)确认解释准确性
质量指标:
建议标准:整体可靠性指标应达到0.75以上才可直接使用结果。
Q2: 如何处理敏感访谈数据的隐私保护问题?
处理敏感访谈数据时的隐私保护策略:
数据预处理:
- 匿名化处理:移除所有可识别个人身份的信息
- 数据脱敏:替换具体的地名、机构名、人名
- 分段处理:避免上传完整访谈数据
技术措施:
合规要求:
- 获得伦理委员会批准
- 参与者知情同意包含AI分析条款
- 遵循GDPR或相关数据保护法规
- 建立数据销毁机制
Q3: 如何在APIYi平台上优化定性研究的成本效益?
针对定性研究的成本优化策略:
智能分配策略:
- 开放编码使用成本较低的模型进行初步处理
- 轴心和选择编码使用Claude 3.7进行深度分析
- 批量处理相似类型的访谈数据
成本控制技巧:
实际节省效果:
- 混合策略通常可节省40-60%成本
- 批量处理可额外节省20-30%
- APIYi平台价格优势可再节省20-40%
月度成本预估(50个访谈,平均5000字):
- 纯Claude策略:¥800-1200
- 混合策略:¥400-700
- 优化批量:¥300-500
完整的定性研究编码工具包已开源,包含Claude集成模块和质量控制系统:
仓库地址:qualitative-research-claude-toolkit
工具包特性:
- 三阶段编码自动化流程
- 编码质量实时监控
- 隐私保护数据处理
- 可视化分析结果导出
- 与主流质性软件兼容
Claude辅助的定性研究编码分析代表了社会科学研究方法的重要进步。通过AI技术的引入,研究者可以在保持学术严谨性的同时,显著提升研究效率和分析深度。
重点回顾:Claude 3.7在逻辑推理和长文本理解方面的优势,使其成为定性研究编码分析的理想工具
实际应用建议:
- 循序渐进:从辅助人工编码开始,逐步过渡到AI主导的编码分析
- 质量控制:建立多层次验证机制,确保编码结果的可信度和学术价值
- 方法论创新:结合传统定性研究理论与AI技术,发展新的分析范式
- 成本效益:通过APIYi等聚合平台的统一接口,实现成本可控的高质量研究
对于社科研究者而言,采用支持Claude等先进模型的聚合平台(如APIYi等),不仅可以获得技术上的便利,更能在研究方法上实现创新突破,为定性研究开拓新的可能性空间。
📝 作者简介:定性研究方法专家,专注AI技术在社会科学研究中的应用与创新。定期分享定性研究数字化转型经验,搜索"APIYi"可找到更多AI辅助研究工具和方法论资料。
🔔 学术交流:欢迎在评论区讨论定性研究方法问题,持续分享AI在社会科学研究中的应用经验和创新实践。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/226096.html