

讯享网
针对Java开发者的图谱,一样很强。

【深度学习】眼底图像之视盘和黄斑分割的探索
文章目录 1 Optic Disc 数据集 1.1 ORIGA-650 1.2 Messidor 1.3 RIM-ONE 1.4 DRION-DB 2 Multiscale sequential convolutional neural networks for simultaneous detection of fovea and optic disc 3 黄斑分割 4 Post-Process Methods 5 Patched Based Attention Unet Model 讯享网
1 Optic Disc 数据集
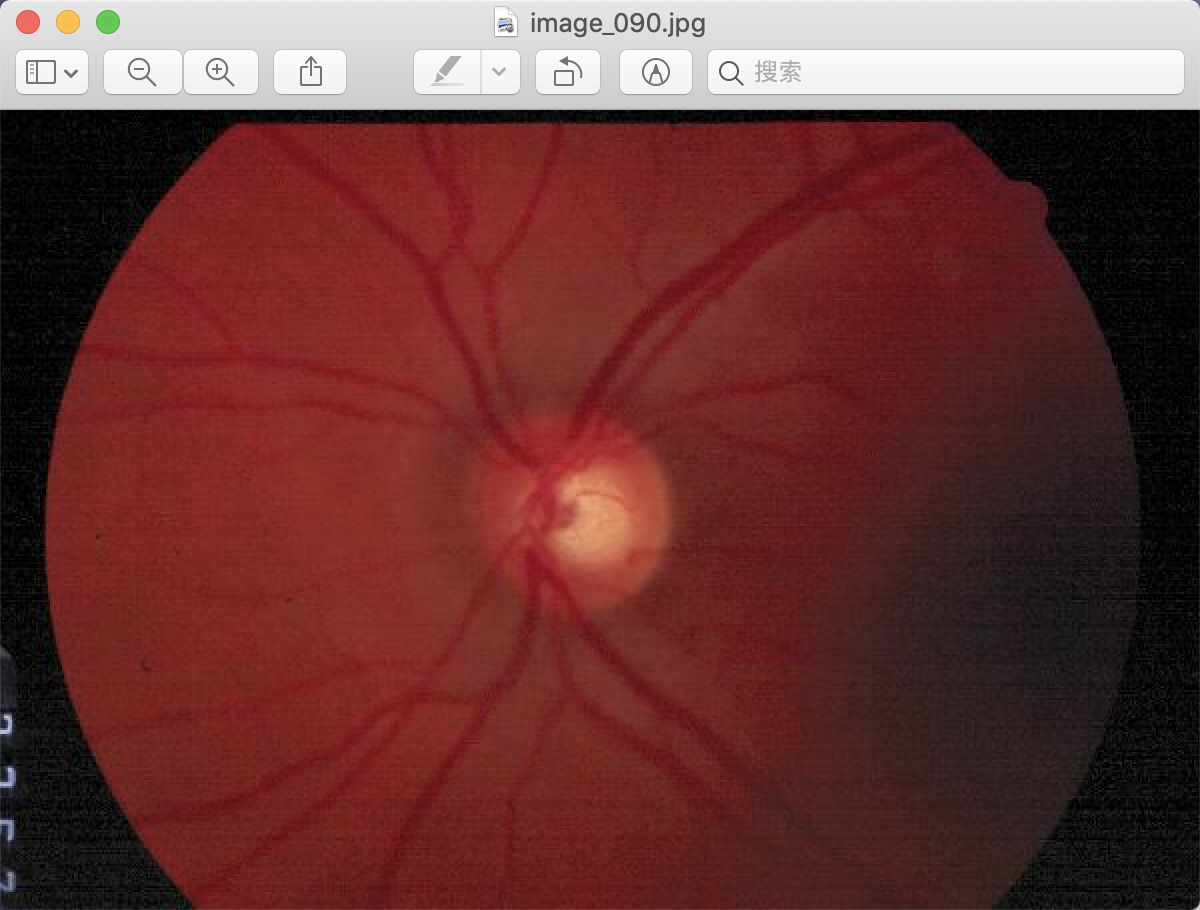
视盘(optic disc):全称视神经盘,有时候也被成为视神经乳头(optic nerve head)。在普通的彩色眼底相机中,一般最亮的区域就是视盘的位置。
1.1 ORIGA-650
这批数据集归属于新加坡国家眼科中心,主要包含650张彩色眼底图像,每张图像都有视盘和视杯的分割标注,同时还有是否患有青光眼的诊断标注。拥有这批数据的IMED团队,也是目前国内最大的眼科医疗图像组。 ORIGA-650分为两个子集 set A for training 和 set B for testing 每个子集包含了325张图像。
1.2 Messidor
Messidor数据集原本是用来做糖尿病视网膜(diabetic retinopathy, DR)病变检测的,只有糖网的分级标注。后来国外的一个课题组又重新手工标定了视盘的边界,因此目前大家也同样在Messidor数据上做视盘的定位和分割。
The performance of our model on Messidor-dataset:

1.3 RIM-ONE
RIM-ONE一共发布了三个子数据集(RIM-ONE-R1,R2,R3),他们的数量分别是169,455和159张。
1.4 DRION-DB
DRION-DB 做的人特别少,但是这批数据集也有111张图像。大家也可以做一下,就当作一种data augmentation了吧。

PS:ISBI2019也有一个challenge,是关于AMD的分类,其中一个sub-task也是optic disc segmentation,


2 Multiscale sequential convolutional neural networks for simultaneous detection of fovea and optic disc
讯享网Deep Learning的方法做视盘和黄斑中心凹的检测 基于的数据库MESSIDOR和Kaggle 图片预处理时,为了避免颜色引入的额外复杂度,都先预处理成灰度图像,然后再做图像增强

分别是灰度图和数据增强后的图像。
网络结构中,先回归出两个矩形区域,分别是视盘和黄斑的矩形区域,然后分别回归出中心。

网络采用比较简单的形式,降采样的程度也不深,只做了两层降采样,这也是可以理解的,毕竟在眼底图像中,黄斑和视盘的范围还是很大的。当然文章感觉也不是那么严禁,要想把4和5对上还挺难的。不过毕竟是提供一种思路,可以自己尝试下

3 黄斑分割


ROSE:视网膜OCTA血管分割数据集

(A) 眼底彩照,绿框为黄斑区域;(B-D)不同深度的OCTA图像。
4 Post-Process Methods
When directly use unet model, we often get some error predictions. So I use a post-process algorithm: predicted area can't be to small. minimum bounding rectangle's height/width or width/height should be in 0.45~2.5 lefted area is the final output. The problem of this algorithm is that the parameters not self-adjusting, so you have to change them if input image is larger or smaller than before. 5 Patched Based Attention Unet Model
讯享网I use a modified Attention Unet which input of model is 128x128pix image patches. When sampling the patches, I focus the algorithm get samples around optic disc. The patches is like that:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/122120.html