
Day2讲到得PR图用于判定和比较学习器的性能,但单纯的通过概念性的比较和质性研究是无法很好的判断出通用方面某两个学习器的性能优劣的。因此人们设计了一些综合考虑查准率、查全率的性能度量。
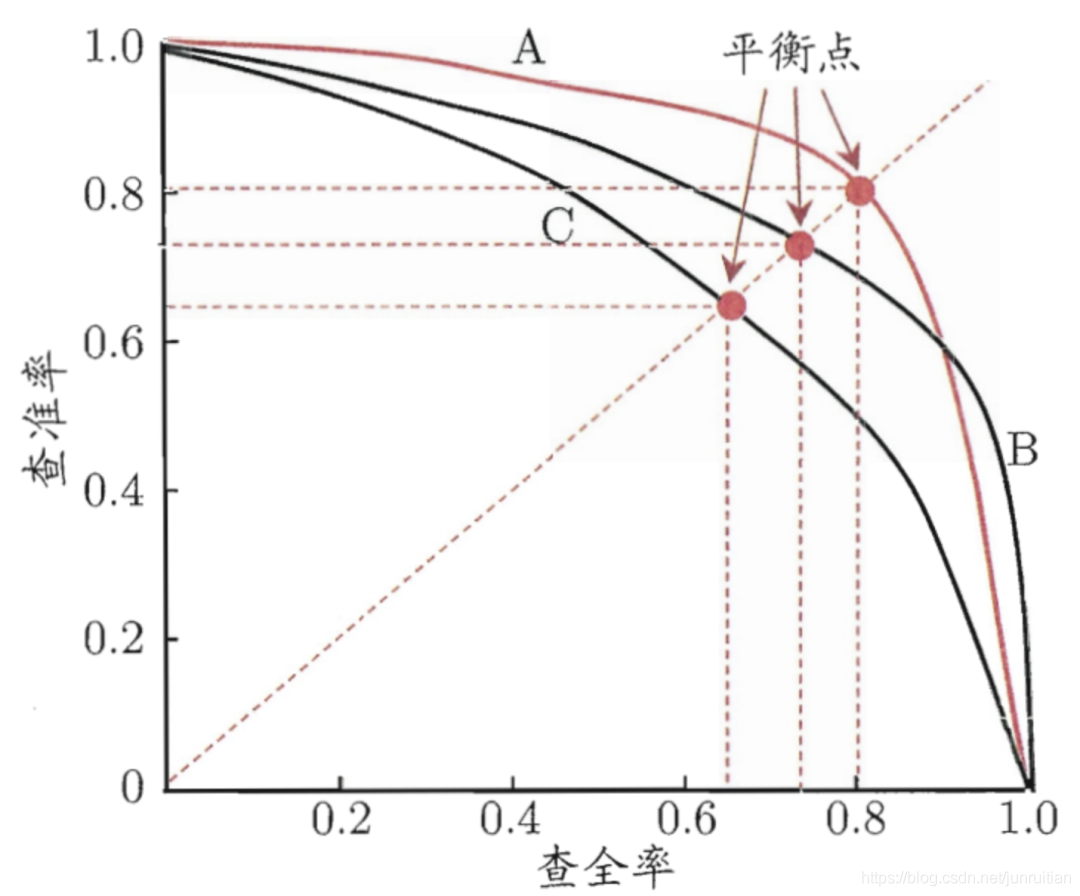
“平衡点”(Break-Even Point,简称BEP)就是这样一个度量 。它是“查准率=查全率”时的取值,例如途中学习器C的BEP是0.64,而基于BEP的比较,可认为学习器A优于B。这是一种度量方式。
但BEP还是过于简化了些,在真正筛选学习器性能时,目的明确的情况下很少要求查准率和查全率双高的情况(因为不太可能),因此在筛选时,更常用的是F1度量。N为样本总数。

!!!在一些应用中。例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时,查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时显然查全率更为重要。因此,我们需要推导出F1度量的更一般形式——F,能让我们用一个式子来表达出对查准率/查全率的不同偏好。它定义为
其中>0.度量了查全率对查准率的相对重要性,=1时退化为标准的F1;>1时查全率有更大影响,反之则查准率有更大影响。
当我们希望在n个二分类混淆矩阵上综合考察查准率和查全率时。一种最直接的做法是在各个混淆矩阵上分别计算出查全率和查准率,最后在计算出这n个查准率/查全率的平均值,并以此计算出对应的宏查准率,宏查全率,以及相应的宏F1.

还可以将各混淆矩阵的对应元素进行平均,即计算TP,FP,TN,FN的平均值,再利用这些均值计算出微查准率和微查全率,以及微F1。
最后续上F1和F的推导。
F1是基于查准率和查全率的调和平均定义的:
F则是加权调和平均:
(这里其实不太懂为什么加权之后1/R的系数要乘以一个,如果哪位大佬有知道的话麻烦告诉我一下谢谢QAQ)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/65669.html