
1.明确需求
下载 《知轩藏书》网站的所有小说
2.需求分析
2.1 分析该网站结构

2.2 分析网站逻辑和架构
该网站虽然给小说分了很多种类,但是每本小说的预览页是统一编排的,这给我们爬虫工程师带来了很大 便利。 讯享网
2.3 找规律
讯享网 随便找一本小说找到它的下载URL http://www.zxcs.me/download.php?id=12019 这里可以看出该网站的下载链接为<b>http://www.zxcs.me/download.php?id={ID}</b>

3.设计逻辑以及流程
3.1 设计整个爬取逻辑
这里根据上面的http://www.zxcs.me/download.php?id={ID} 结构进行爬取,大概看了下该网站的最大ID不超过2w, 3.2 获取下载link
讯享网这里通过Chrome调试,很容易得到下载链接 
3.3 可持续化、可重复性、可筛选性设计
为了能记录所有小说的数据,这里我用的Mysql数据库进行存储。 在实际爬取小说时发现,单线程可能导致爬取阻塞,我用bat脚本定时刷新下载程序。 3.4 数据设计
讯享网根据网站结构,我这里设计的的数据表包含id,storyName,status_code,downloadUrl,size,type,isDownload 其中id是主键,这里的id对应的上面的http://www.zxcs.me/download.php?id={ID} ID值。
4.代码实现(为了防止爬虫带来的法律问题,暂不提供完整代码)
4.1 数据表 - 创建表之后,先写入id = 1-2w 2w条记录
DROP TABLE IF EXISTS `jjxs`; CREATE TABLE `jjxs` ( `id` int(5) NOT NULL, `storyName` varchar(50) DEFAULT NULL, `status_code` int(5) DEFAULT NULL, `downloadUrl` varchar(1024) DEFAULT NULL, `size` float(10,2) DEFAULT NULL, `type` varchar(1) DEFAULT NULL, `isDownload` varchar(1) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 4.2 爬取小说信息 - 更新小说的 storyName,status_code,downloadUrl,size,type 信息
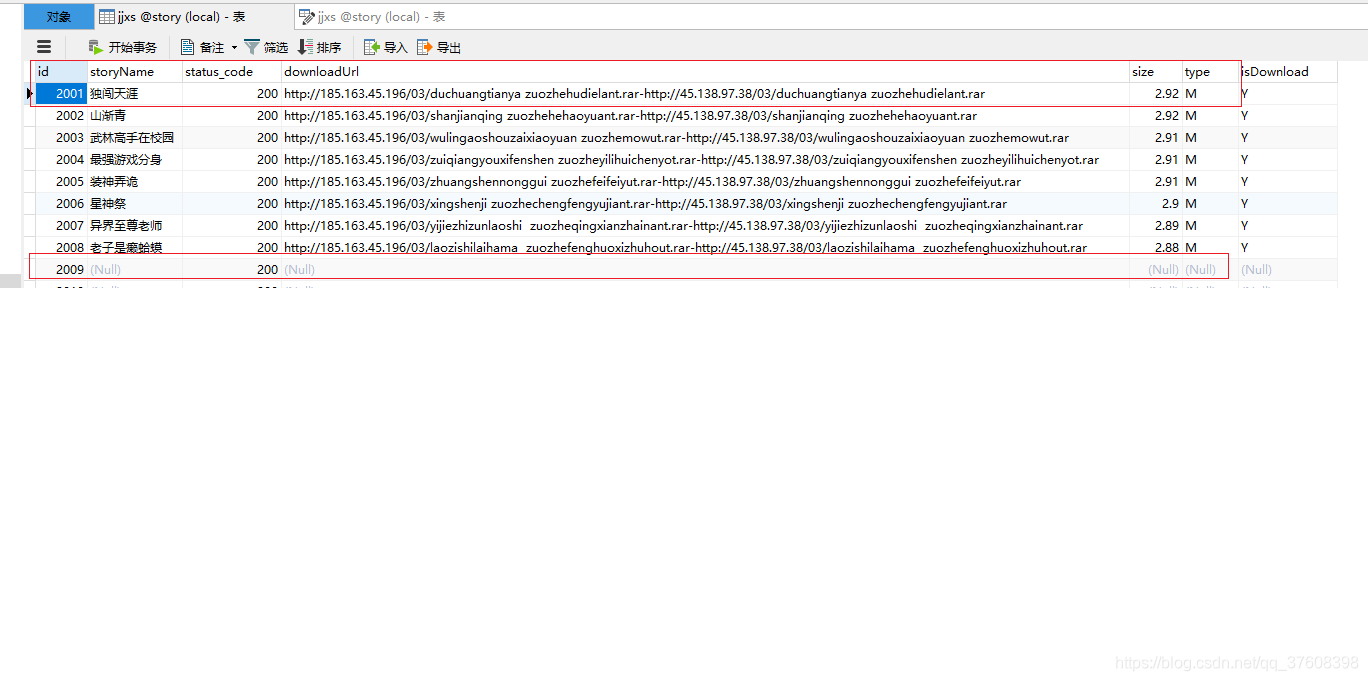
讯享网 sql = "SELECT * FROM jjxs WHERE status_code is NULL ORDER BY id"
retSet = exeSql(mysqlSetting_local,sql)
retList = [[x[0],"http://www.zxcs.me/download.php?id="+str(x[0])] for x in retSet]
for index,url in enumerate(retList,start=retList[0][0]):
print(url[1])
response = requests.get(url = url[1])
if response.status_code == 200:
txt = response.text
start = txt.find("小说大小")
if start > -1:
m = re.search("[0-9|.]+\s{0,3}M?",txt[start:start + 20])
if m :
size = m[0]
else:
print('\t\t',url)
sql = "UPDATE jjxs SET status_code={status} WHERE id={id}".format(status=response.status_code,id=url[0])
print(sql)
retSet = insert(mysqlSetting_local,sql)
continue
else:
print('\t',url)
sql = "UPDATE jjxs SET status_code={status} WHERE id={id}".format(status=response.status_code,id=url[0])
print(sql)
retSet = insert(mysqlSetting_local,sql)
continue
html = bf(txt,'html.parser')
storyInfo = html.select_one('h2').text
if storyInfo:
if storyInfo.find("《") > -1 and storyInfo.find("》") > -1:
storyName = storyInfo[storyInfo.find("《")+1 : storyInfo.find("》")]
aTagList = [x['href'] for x in html.select('span.downfile a')]
print('\t\t',url[0],storyName,size)
size = size.replace(" ","")
if size.find("M") > -1:
size = size.replace("M","")
sql = "UPDATE jjxs SET status_code={status},storyName='{storyName}',downloadUrl='{downloadUrl}',size={size},type='M' WHERE id={id}".format(status=response.status_code,storyName=storyName,downloadUrl='-'.join(aTagList).replace('\'','*'),size=size,id=url[0])
else:
sql = "UPDATE jjxs SET status_code={status},storyName='{storyName}',downloadUrl='{downloadUrl}',size={size} WHERE id={id}".format(status=response.status_code,storyName=storyName,downloadUrl='-'.join(aTagList),size=size,id=url[0])
print(sql)
retSet = insert(mysqlSetting_local,sql)
else:
print("\t\tStory information not formate.")
sql = "UPDATE jjxs SET status_code={status} WHERE id={id}".format(status=response.status_code,id=url[0])
print(sql)
retSet = insert(mysqlSetting_local,sql)
else:
print("\tNot find story information.")
sql = "UPDATE jjxs SET status_code={status} WHERE id={id}".format(status=response.status_code,id=url[0])
print(sql)
retSet = insert(mysqlSetting_local,sql)
else:
print("Index : " + str(index) + ", Return Code:" + str(response.status_code) + ", fail Url: " + url)
sql = "UPDATE jjxs SET status={status} WHERE id={id}".format(status=response.status_code,id=index)
retSet = exeSql(mysqlSetting_local,sql)
4.3 根据数据库筛选出小说大小大于2M的小说进行下载,下载完成更新数据表isDownload字段为Y。
这里都是简单的sql,很好懂
sqltotal = "select * from jjxs where status_code = 200 and storyName is not NULL and type = 'M' and size > 2.00 ORDER BY size asc" retSettotal = exeSql(mysqlSetting_local,sqltotal) totalCount = len(retSettotal) sqlCompleted = "select * from jjxs where status_code = 200 and storyName is not NULL and type = 'M' and size > 2.00 and isDownload in ('Y','N') ORDER BY size asc" retCompleted = exeSql(mysqlSetting_local,sqlCompleted) totalCompletedCount = len(retCompleted) print('Completed : {:.2f} %'.format(totalCompletedCount/totalCount * 100* 1.00)) sql = "select * from jjxs where status_code = 200 and storyName is not NULL and type = 'M' and size > 2.00 and isDownload is NULL ORDER BY size asc" retSet = exeSql(mysqlSetting_local,sql) retList = [[x[0],x[1],x[3]] for x in retSet] for x in retList: print("Download story: {id},{storyName}".format(id=x[0],storyName=x[1])) urlList = x[2].split('-') for urlItem in urlList: if downloadTxt([x[0],x[1],urlItem]): totalCompletedCount=totalCompletedCount+1 print('Completed : {:.2f} %'.format(totalCompletedCount/totalCount * 100* 1.00)) saveFile('completed.txt',str('{:.2f} %'.format(totalCompletedCount/totalCount * 100* 1.00)),'w') break 4.4 bat 脚本 - 防止下载程序挂了,这里是定时一个小时刷新一次
讯享网@echo off :a start python.exe download.py echo [%date:~,10% %time:~,-3% ] start python.exe downloadDesc.py echo [%date:~,10% %time:~,-3% ] ping 127.0.0.1 -n 3600 0>nul 1>nul taskkill /im python.exe /f goto a
4.5 bat 脚本 - 下载完成RAR文件后,需要用到该脚本自动解压
@echo off del *.txt FOR /F %%i IN ('DIR *.rar /B') DO ( unrar e -y %%i ) 5.测试及结果展示
5.1 下载完成的小说


5.2 总共下载小说的总大小

5.3 实际解压缩后的所有txt大小

6.总结
这次的实战中遇到了下载大文件进程挂起问题,在多方查找资料可以通过requeset.get方法的stream = True参数
解决,这个是之前没有碰到过的,另外这个网站没有设置反扒策略,所以这里没有用到Cookie等参数。本文是一篇
非常基础的爬虫实战教程,当然里面还有很多不足之处,后面再改进吧。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/57037.html