
今天在hive里查数据的时候发现一个有趣的问题:
先上sql:
SELECT DISTINCT a.mobile, concat_ws('#','8',cast(22222 AS string )) AS extend, 10 AS batchNo, 0 AS sendNo, SUBSTR( IF ( d.wechat_name IS NULL, d.learn_number, d.wechat_name ), 1, 5 ) AS wechatName FROM ods_kcl_mobile_addition_data_1h_all a LEFT JOIN ods_kcl_customer_1h_all d ON a.mobile = d.mobile WHERE NOT EXISTS ( SELECT 1 FROM ods_kcl_customer_1h_all b JOIN ods_kcl_live_entry_record_1h_all c ON b.id = c.customer_id WHERE a.mobile = b.mobile ) AND a.mobile IS NOT NULL AND d.wechat_name IS NOT NULL limit 100;讯享网
结果:
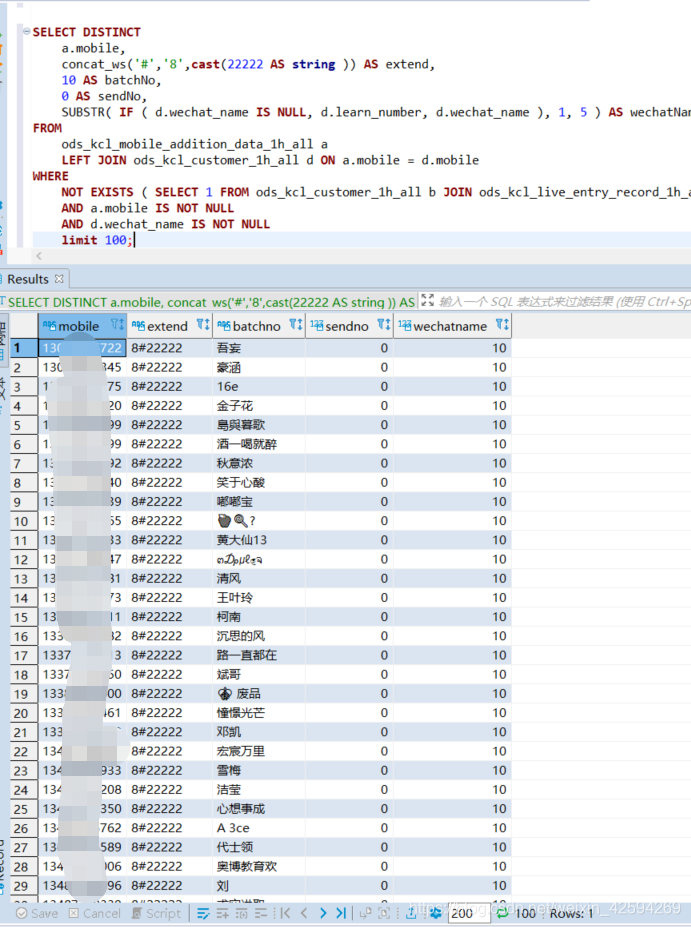
问题:我在sql中batchno给的是默认值10,wechatname应该是字符数据,但是结果显示我的batchno的结果是wechatname,而wechatname这一列的值变成了10。
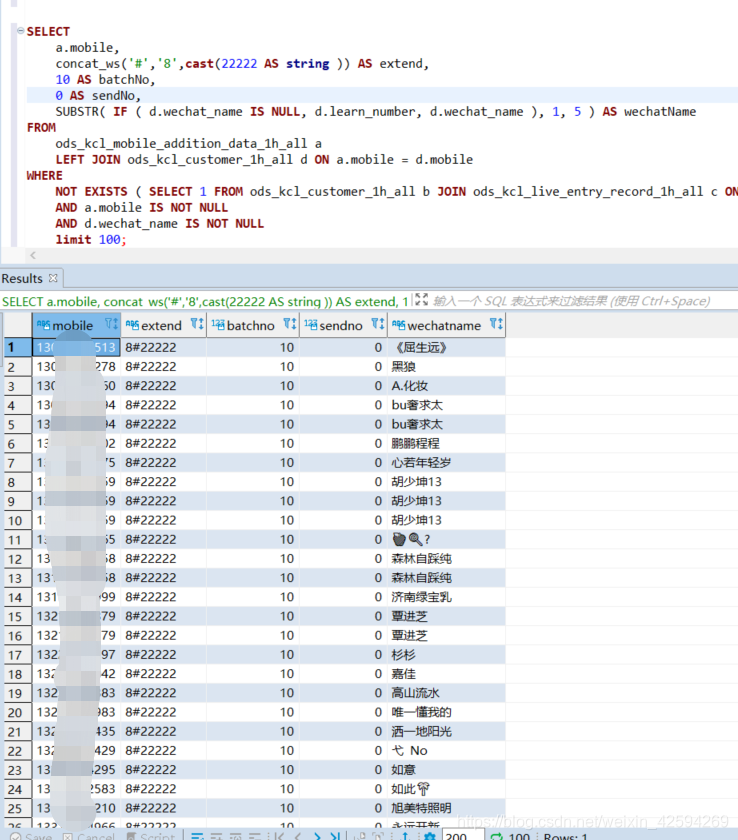
1.如果把distinct去掉之后,在查询就对了
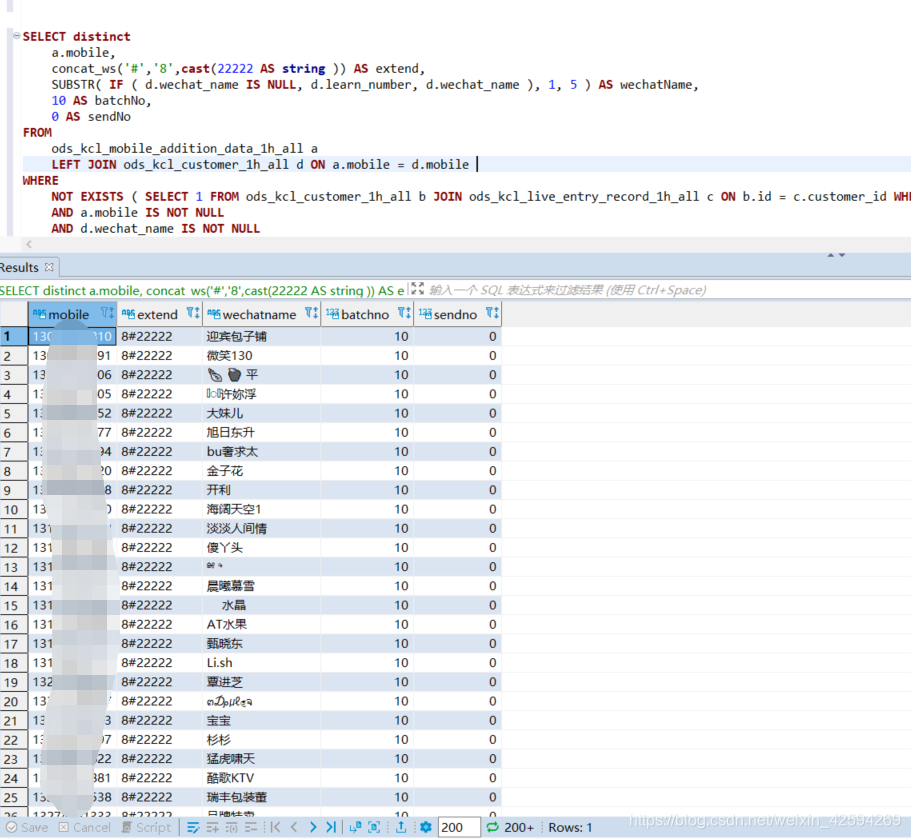
2.如果把wechatname放前面,常量的几列放后面也可以实现

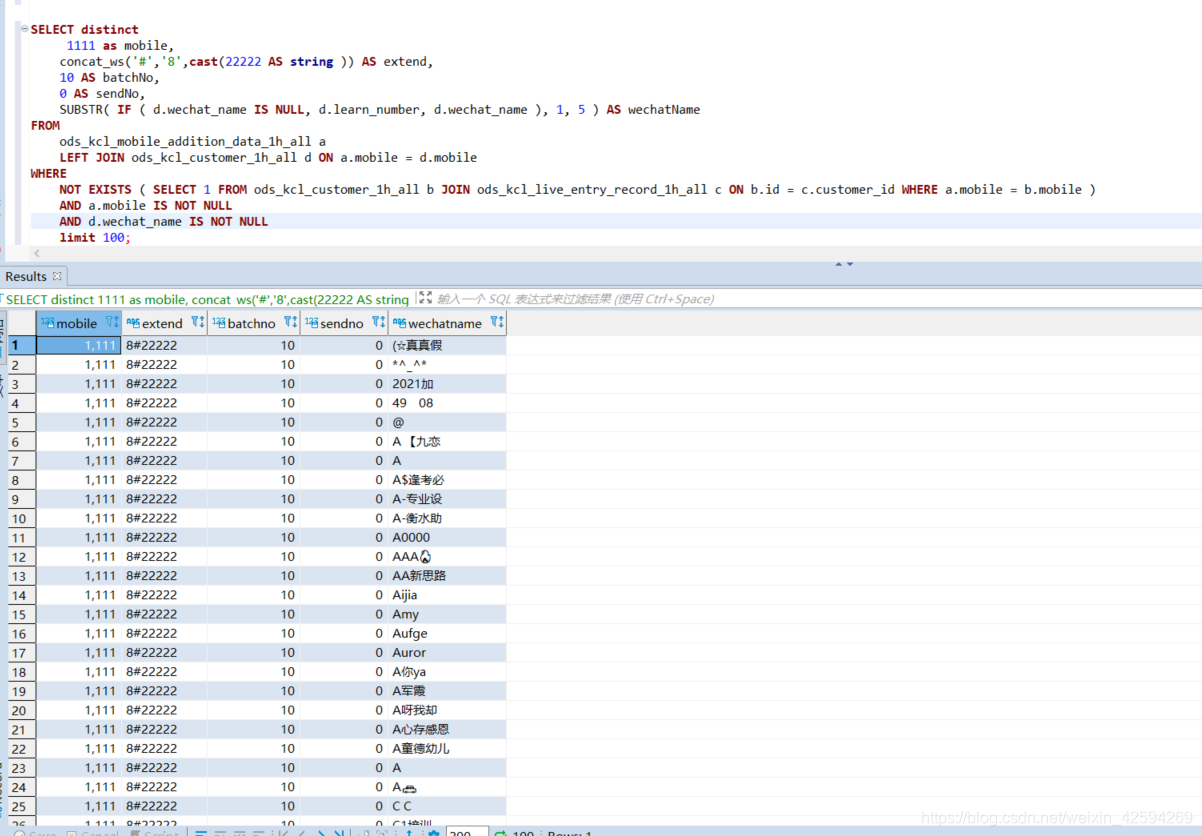
3.如果把前面的mobile设置为常量也可以实现:
针对这个现象查了一下资料也没有发现有合理的解释。大胆的猜测一下:
因为我们在数据库查询时,如果不用distinct那就是我们的列是一列一列出数据的,所以不会有乱码的存在。
如果用了distinct,我们会对结果进行去重,在运行select语句时,会执行需要进行查询才会得出结果的数据,如:mobile,wechatname,常量会放在后面生成,这样在执行distinct的时候会先去重mobile,wechatname,再去重常量,就会造成错列的现象。
当然不知道这个到底对不对,以后处理数据时还是要注意的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/47422.html