
本次目标
使用逻辑回归分类器,实现一个线性二分类器。
问题的分析
data.csv文件形式如下,共80个点,0和1两类。
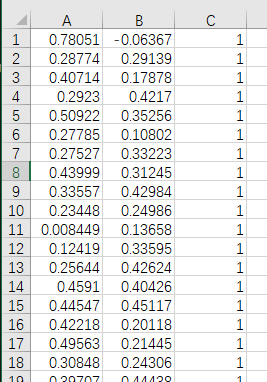
import matplotlib.pyplot as plt import numpy as np import pandas as pd data = pd.read_csv('data.csv', header=None) X = np.array(data[[0,1]]) y = np.array(data[2]) plot_points(X,y) plt.show()讯享网
结果:

技术介绍1:逻辑回归
查阅了很多资料,目前难以从头到尾的讲清楚逻辑回归的所有内容和前因后果,大概是知道了,但疑问很多,第二轮时再来看这个问题。
- 机器学习算法之逻辑回归https://www.biaodianfu.com/logistic-regression.html
技术介绍2:梯度下降算法
“梯度”概述
梯度(矢量)是微积分中的一个概念:
- 在单变量的函数中,梯度其实就是函数的导数(带方向),代表着函数在某个给定点的切线的斜率
- 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向。梯度是偏导数(标量)的矢量和。
看待微分的意义,可以有不同的角度:
- 函数某点切线的斜率。
- 函数的变化率。
单变量微分例子:
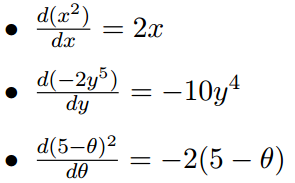
多变量微分例子:
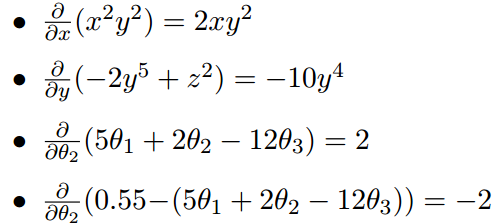
求多变量梯度的例子:
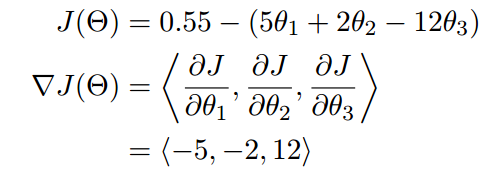
我们可以看到,梯度就是分别对每个变量进行微分,然后用逗号分割开,梯度是用<>包括起来,说明梯度其实一个向量。
梯度下降法简述
梯度下降它的主要目的和实现方法是:沿着目标函数梯度的方向更新参数值,通过迭代以期望达到到目标函数的最小值(或最大值)。
在机器学习中,常见的有:随机梯度下降法和批量梯度下降法。
梯度下降算法的数学表达
下面我们就开始从数学上解释梯度下降算法的计算过程和思想!
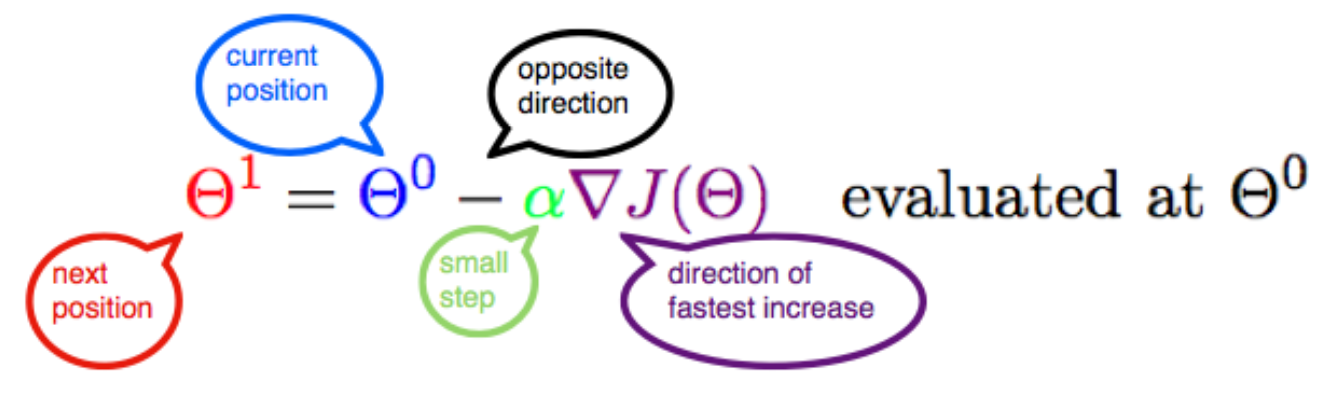
此公式的意义是:J是关于Θ的一个函数,我们当前位置在Θ0点,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是α,走完这个段步长,就到达了Θ1这个点!
下面就这个公式的几个常见的疑问:
- α的含义:
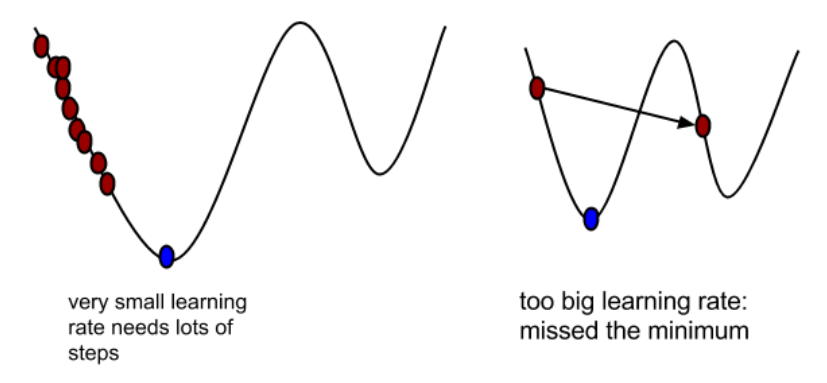
- 学习率或者步长。α不能太大也不能太小,太小导致迟迟走不到最低点,太大导致无法收敛或错过最低点!

- 为什么用减法而不是加法?
- 梯度前加一个负号,就意味着朝着梯度相反的方向前进!我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号。
单变量函数的梯度下降
假设有如下单变量函数,我们利用梯度下降法,试图找到一个参数θ的**值,使得损失函数J(θ)的值最小:
![]()
函数的微分:
![]()
初始化,起点为:
![]() (注意这里0不是次方,而是序号意思。即先设定单变量θ的初始值为2,至于函数值为多少需要去计算。
(注意这里0不是次方,而是序号意思。即先设定单变量θ的初始值为2,至于函数值为多少需要去计算。
学习率为:
![]()
根据梯度下降的计算公式:

我们开始进行梯度下降的迭代计算过程:

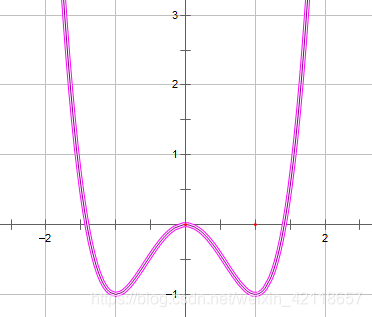
可视化收敛过程如下:
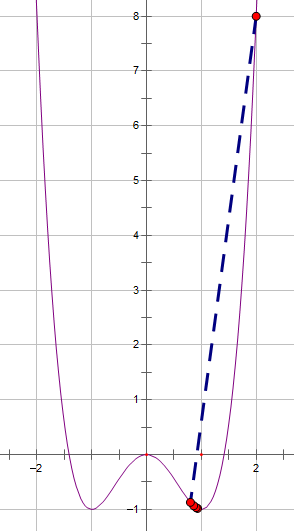

局部放大图:

从可视化中可看出,梯度下降法在趋近函数最小值(1, -1)点,那个点位的单变量值为1。
首先本案例函数是我自己设计并可视化后选定的,我在动手计算时,发现学习率对梯度下降太敏感了,本来设定的学习率为0.4,但一下就跑到左边曲线很远地方去了,0.1也会跑到左边去,最终发现0.05对于这个函数而言是比较好的学习率。所以说,花点时间亲自动手,对算法的理解还是会生动的多。
多变量函数的梯度下降
我们假设有一个损失函数:
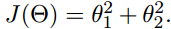
现在要通过梯度下降法计算这个函数的最小值。我们通过观察就能发现最小值其实就是 (0,0)点。但是接下来,我们会从梯度下降算法开始一步步计算到这个最小值!
我们假设初始的起点为:
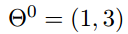
初始的学习率为:
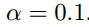
函数的梯度为:
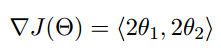
进行多次迭代:

我们发现,已经基本靠近函数的最小值点:
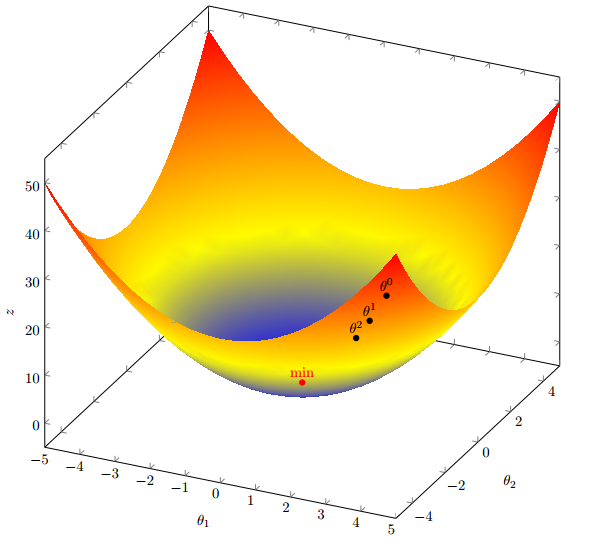
从上面能看出,多变量的函数梯度下降和单变量没有本质区别,计算的时候各变量基本是隔离的,有点像矩阵计算。
逻辑回归+梯度下降法在本项目中应用
1 sigmoid激励函数
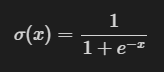
2 输出公式
![]()
3 损失函数
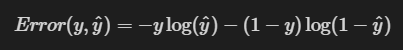
其中 y 是真值标签值,y^是预测标签值。
4 更新权值的函数
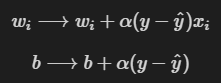
代码和输出
讯享网import matplotlib.pyplot as plt import numpy as np import pandas as pd def plot_points(X, y): admitted = X[np.argwhere(y==1)] rejected = X[np.argwhere(y==0)] plt.scatter([s[0][0] for s in rejected], [s[0][1] for s in rejected], s = 25, color = 'blue', edgecolor = 'k') plt.scatter([s[0][0] for s in admitted], [s[0][1] for s in admitted], s = 25, color = 'red', edgecolor = 'k') def display(m, b, color='g--'): plt.xlim(-0.05,1.05) plt.ylim(-0.05,1.05) x = np.arange(-10, 10, 0.1) plt.plot(x, m*x+b, color) # Activation (sigmoid) function def sigmoid(x): return 1 / (1 + np.exp(-x)) # Output (prediction) formula def output_formula(features, weights, bias): return sigmoid(np.dot(features, weights) + bias) # Error (log-loss) formula def error_formula(y, output): return - y*np.log(output) - (1 - y) * np.log(1-output) # Gradient descent step def update_weights(x, y, weights, bias, learnrate): output = output_formula(x, weights, bias) d_error = y - output weights += learnrate * d_error * x bias += learnrate * d_error return weights, bias def train(features, targets, epochs, learnrate, graph_lines=False): # 初始化 errors = [] n_records, n_features = features.shape last_loss = None weights = np.random.normal(scale=1 / n_features.5, size=n_features) bias = 0 for e in range(epochs): del_w = np.zeros(weights.shape) #开始一个epoch的梯度下降计算 for x, y in zip(features, targets): #zip:逐个元素打包成元组。 weights, bias = update_weights(x, y, weights, bias, learnrate) # Printing out the log-loss error on the training set out = output_formula(features, weights, bias) loss = np.mean(error_formula(targets, out)) errors.append(loss) if e % (epochs / 10) == 0: #无论多少epoch,都只打印10次结果 print("\n========== Epoch", e,"==========") if last_loss and last_loss < loss: print("Train loss: ", loss, " WARNING - Loss Increasing") else: print("Train loss: ", loss) last_loss = loss # e.g. 0.95 --> True (= 1), 0.31 --> False (= 0) predictions = out > 0.5 # print(out) # print(targets) accuracy = np.mean(predictions == targets)#相等为1,不相等为0,均值就是精度。 print("Accuracy: ", accuracy) if graph_lines and e % (epochs / 100) == 0: #每个epoch绘制一次‘分割线’ display(-weights[0]/weights[1], -bias/weights[1]) # 绘制预测效果图 plt.title("Solution boundary") display(-weights[0]/weights[1], -bias/weights[1], 'black') # 绘制最终的分割线 plot_points(features, targets)# 绘制所有样本点 plt.show() # 绘制loss曲线 plt.title("Error Plot") plt.xlabel('Number of epochs') plt.ylabel('Error') plt.plot(errors) plt.show() """ X:point坐标集 y:标签集(0或1) """ data = pd.read_csv('data.csv', header=None) X = np.array(data[[0,1]]) y = np.array(data[2]) np.random.seed(44) epochs = 100 learnrate = 0.01 train(X, y, epochs, learnrate, True)
========== Epoch 0 ========== Train loss: 0.81634 Accuracy: 0.4 ========== Epoch 10 ========== Train loss: 0.54962 Accuracy: 0.59 ========== Epoch 20 ========== Train loss: 0.69508 Accuracy: 0.74 ========== Epoch 30 ========== Train loss: 0.2473 Accuracy: 0.84 ========== Epoch 40 ========== Train loss: 0.61401 Accuracy: 0.86 ========== Epoch 50 ========== Train loss: 0. Accuracy: 0.93 ========== Epoch 60 ========== Train loss: 0.71399 Accuracy: 0.93 ========== Epoch 70 ========== Train loss: 0.39074 Accuracy: 0.93 ========== Epoch 80 ========== Train loss: 0. Accuracy: 0.94 ========== Epoch 90 ========== Train loss: 0.79921 Accuracy: 0.94

总结
学习如何编码实现梯度下降算法,并且在一个小数据集上应用。
即:使用梯度下降算法,找到一条直线,使之能最大程度的分隔两类数据点。
参考:
- 梯度下降法和反向传播算法是什么关系?https://www.zhihu.com/question//answer/
- ★★深入浅出--梯度下降法及其实现https://www.jianshu.com/p/c7eb0e
- ★多元函数的偏导数、方向导数、梯度以及微分之间的关系思考https://zhuanlan.zhihu.com/p/
- 逻辑回归和神经网络之间有什么关系?https://blog.csdn.net/tz_zs/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/45692.html