
libsvm简单使用demo
一、libsvm使用说明

二、svm.h源码
#ifndef _LIBSVM_H //如果没有定义 _LIBSVM_H 宏 #define _LIBSVM_H //则定义 _LIBSVM_H 宏,用于防止重复包含 #define LIBSVM_VERSION 317 //定义一个宏,表示 libsvm 的版本号 #ifdef __cplusplus //如果是 C++ 编译器 extern "C" { //则使用 C 语言的链接方式 #endif extern int libsvm_version; //声明一个外部变量,表示 libsvm 的版本号 struct svm_node //定义一个结构体,表示一个特征节点 { int index; //特征的索引 double value; //特征的值 }; struct svm_problem //定义一个结构体,表示一个 SVM 问题 { int l; //训练集的行数 double *y; //训练集的标签向量 struct svm_node x; //训练集的特征矩阵 }; enum { C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR }; /* svm_type */ //定义一个枚举类型,表示 SVM 的类型 enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED }; /* kernel_type */ //定义一个枚举类型,表示核函数的类型 struct svm_parameter //定义一个结构体,表示 SVM 的参数 { int svm_type; //SVM 的类型 int kernel_type; //核函数的类型 int degree; /* for poly */ //多项式核函数的次数 double gamma; /* for poly/rbf/sigmoid */ //核函数的系数 double coef0; /* for poly/sigmoid */ //核函数的常数项 /* these are for training only */ //以下是只用于训练的参数 double cache_size; /* in MB */ //内核缓存的大小(以 MB 为单位) double eps; /* stopping criteria */ //停止准则的容差 double C; /* for C_SVC, EPSILON_SVR and NU_SVR */ //C-SVM 分类器或回归器的惩罚系数 int nr_weight; /* for C_SVC */ //不同类别的权重的个数 int *weight_label; /* for C_SVC */ //不同类别的权重的标签 double* weight; /* for C_SVC */ //不同类别的权重的值 double nu; /* for NU_SVC, ONE_CLASS, and NU_SVR */ //nu-SVM 分类器或回归器的参数 double p; /* for EPSILON_SVR */ //epsilon-SVR 回归器的损失函数的参数 int shrinking; /* use the shrinking heuristics */ //是否使用启发式收缩 int probability; /* do probability estimates */ //是否计算概率估计 }; // // svm_model // struct svm_model //定义一个结构体,表示 SVM 的模型 { struct svm_parameter param; /* parameter */ //SVM 的参数 int nr_class; /* number of classes, = 2 in regression/one class svm */ //类别的个数,回归或单类 SVM 为 2 int l; /* total #SV */ //支持向量的总数 struct svm_node SV; /* SVs (SV[l]) */ //支持向量的矩阵 double sv_coef; /* coefficients for SVs in decision functions (sv_coef[k-1][l]) */ //支持向量在决策函数中的系数 double *rho; /* constants in decision functions (rho[k*(k-1)/2]) */ //决策函数中的常数 double *probA; /* pariwise probability information */ //成对概率信息 double *probB; int *sv_indices; /* sv_indices[0,...,nSV-1] are values in [1,...,num_traning_data] to indicate SVs in the training set */ //支持向量在训练集中的索引 /* for classification only */ //以下是只用于分类的信息 int *label; /* label of each class (label[k]) */ //每个类别的标签 int *nSV; /* number of SVs for each class (nSV[k]) */ //每个类别的支持向量的个数 /* nSV[0] + nSV[1] + ... + nSV[k-1] = l */ /* XXX */ int free_sv; /* 1 if svm_model is created by svm_load_model*/ /* 0 if svm_model is created by svm_train */ //表示 svm_model 是由 svm_load_model 还是 svm_train 创建的 }; struct svm_model *svm_train(const struct svm_problem *prob, const struct svm_parameter *param); //声明一个函数,用于训练 SVM 模型,参数为 SVM 问题和 SVM 参数,返回值为 SVM 模型的指针 void svm_cross_validation(const struct svm_problem *prob, const struct svm_parameter *param, int nr_fold, double *target); //声明一个函数,用于进行交叉验证,参数为 SVM 问题、SVM 参数、交叉验证的折数和目标向量,无返回值 int svm_save_model(const char *model_file_name, const struct svm_model *model); //声明一个函数,用于保存 SVM 模型到文件,参数为文件名和 SVM 模型的指针,返回值为 0 表示成功,-1 表示失败 struct svm_model *svm_load_model(const char *model_file_name); //声明一个函数,用于从文件加载 SVM 模型,参数为文件名,返回值为 SVM 模型的指针,如果失败则为 NULL int svm_get_svm_type(const struct svm_model *model); //声明一个函数,用于获取 SVM 的类型,参数为 SVM 模型的指针,返回值为枚举类型的值 int svm_get_nr_class(const struct svm_model *model); //声明一个函数,用于获取类别的个数,参数为 SVM 模型的指针,返回值为整数 void svm_get_labels(const struct svm_model *model, int *label); //声明一个函数,用于获取每个类别的标签,参数为 SVM 模型的指针和标签向量,无返回值 void svm_get_sv_indices(const struct svm_model *model, int *sv_indices); //声明一个函数,用于获取支持向量在训练集中的索引,参数为 SVM 模型的指针和索引向量,无返回值 int svm_get_nr_sv(const struct svm_model *model); //声明一个函数,用于获取支持向量的个数,参数为 SVM 模型的指针,返回值为整数 double svm_get_svr_probability(const struct svm_model *model); //声明一个函数,用于获取 SVR 的概率估计,参数为 SVM 模型的指针,返回值为浮点数,如果失败则为 0 double svm_predict_values(const struct svm_model *model, const struct svm_node *x, double* dec_values); //声明一个函数,用于预测一个样本的决策值,参数为 SVM 模型的指针、样本的特征向量和决策值向量,返回值为预测的标签 double svm_predict(const struct svm_model *model, const struct svm_node *x); //声明一个函数,用于预测一个样本的标签,参数为 SVM 模型的指针和样本的特征向量,返回值为预测的标签 double svm_predict_probability(const struct svm_model *model, const struct svm_node *x, double* prob_estimates); //声明一个函数,用于预测一个样本的概率估计,参数为 SVM 模型的指针、样本的特征向量和概率估计向量,返回值为预测的标签 void svm_free_model_content(struct svm_model *model_ptr); //声明一个函数,用于释放 SVM 模型的内容,参数为 SVM 模型的指针,无返回值 void svm_free_and_destroy_model(struct svm_model model_ptr_ptr); //声明一个函数,用于释放并销毁 SVM 模型,参数为 SVM 模型的指针的指针,无返回值 void svm_destroy_param(struct svm_parameter *param); //声明一个函数,用于销毁 SVM 参数,参数为 SVM 参数的指针,无返回值 const char *svm_check_parameter(const struct svm_problem *prob, const struct svm_parameter *param); //声明一个函数,用于检查 SVM 参数是否合法,参数为 SVM 问题和 SVM 参数的指针,返回值为一个字符串,如果为 NULL,则表示参数合法,否则表示参数有误 int svm_check_probability_model(const struct svm_model *model); //声明一个函数,用于检查 SVM 模型是否支持概率估计,参数为 SVM 模型的指针,返回值为一个整数,如果为 0,则表示不支持,否则表示支持 void svm_set_print_string_function(void (*print_func)(const char *)); //声明一个函数,用于设置 libsvm 的输出函数,参数为一个函数指针,该函数接受一个字符串作为参数,无返回值 #ifdef __cplusplus //如果是 C++ 编译器 } #endif //则结束 C 语言的链接方式 #endif /* _LIBSVM_H */ //结束防止重复包含的条件讯享网
三、示例demo

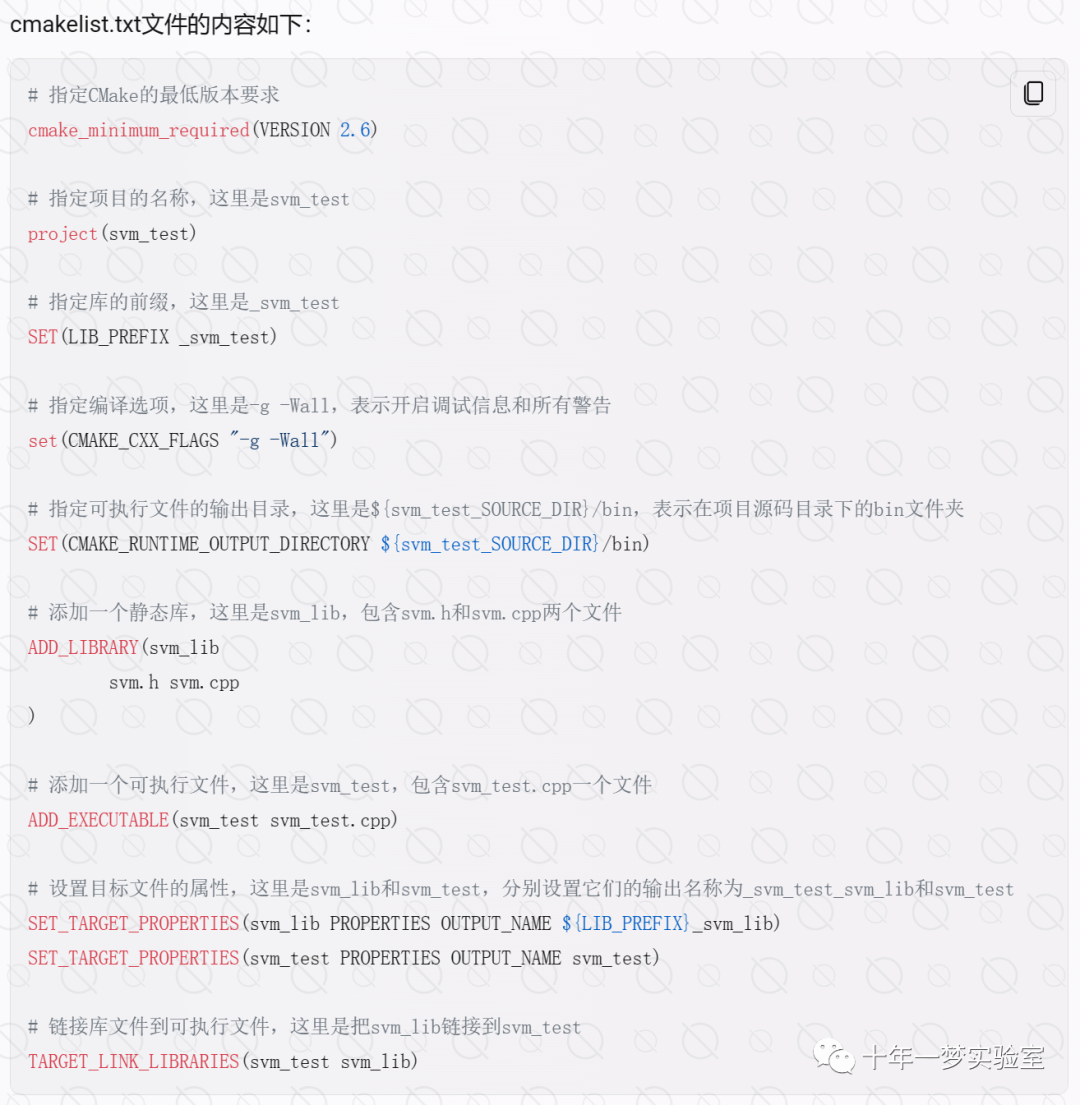
讯享网#include "svm.h" //引入 libsvm 的头文件 #include <ctype.h> //引入字符处理的头文件 #include <stdlib.h> //引入标准库的头文件 #include <vector> //引入向量容器的头文件 #include <iostream> //引入输入输出流的头文件 using namespace std; //使用标准命名空间 #define Malloc(type,n) (type *)malloc((n)*sizeof(type)) //定义一个宏,用于分配内存 struct svm_parameter param; // 由 parse_command_line 函数设置,用于存储 SVM 的参数 struct svm_problem prob; // 由 read_problem 函数设置,用于存储训练集的特征和标签 struct svm_model *model; //用于存储训练后的 SVM 模型 struct svm_node *x_space; //用于存储训练集的特征向量 vector<int> generateLabels(int labelsSize) //定义一个函数,用于生成标签向量 { std::vector<int> labels; //创建一个 int 类型的向量 for (int i=0; i<labelsSize; ++i) //循环 labelsSize 次 { labels.push_back(i%2+1); //向向量中添加元素,值为 i 除以 2 的余数加 1 } return labels; //返回向量 } vector<vector<double> > generateData(int problemSize, int featureNum) //定义一个函数,用于生成特征数据 { std::vector<std::vector<double> > data; //创建一个 double 类型的二维向量 for (int i=0; i<problemSize; ++i) //循环 problemSize 次 { std::vector<double> featureSet; //创建一个 double 类型的向量,用于存储一行特征 for (int j=0; j<featureNum; ++j) //循环 featureNum 次 { cout<<"feature pushed"<<endl; //输出提示信息 featureSet.push_back(j); //向向量中添加元素,值为 j } data.push_back(featureSet); //将向量添加到二维向量中 } return data; //返回二维向量 } int main() //定义主函数 { //here I will create a small artificial problem just for illustration int sizeOfProblem = 30; //定义一个变量,表示训练集的行数 int elements = 10; //定义一个变量,表示每行特征的个数 vector<vector<double> > data = generateData(sizeOfProblem,elements); //调用 generateData 函数,生成特征数据 vector<int> labels = generateLabels(sizeOfProblem); //调用 generateLabels 函数,生成标签数据 cout<<"data size = "<<data.size()<<endl; //输出特征数据的大小 cout<<"labels size = "<<labels.size()<<endl; //输出标签数据的大小 //initialize the size of the problem with just an int prob.l = sizeOfProblem; //将 prob 结构体的 l 成员赋值为训练集的行数 //here we need to give some memory to our structures // @param prob.l = number of labels // @param elements = number of features for each label prob.y = Malloc(double,prob.l); //为 prob 结构体的 y 成员分配内存,用于存储标签向量 prob.x = Malloc(struct svm_node *, prob.l); //为 prob 结构体的 x 成员分配内存,用于存储特征向量的指针 x_space = Malloc(struct svm_node, (elements+1) * prob.l); //为 x_space 分配内存,用于存储特征向量的索引和值 //here we are going to initialize it all a bit //initialize the different lables with an array of labels for (int i=0; i < prob.l; ++i) //循环 prob.l 次 { prob.y[i] = labels[i]; //将 prob 结构体的 y 成员的第 i 个元素赋值为标签向量的第 i 个元素 cout<<"prob.y["<<i<<"] = "<<prob.y[i]<<endl; //输出赋值结果 } //initialize the svm_node vector with input data array as follows: int j=0; //定义一个变量,用于遍历 x_space for (int i=0;i < prob.l; ++i) //循环 prob.l 次 { //set i-th element of prob.x to the address of x_space[j]. //elements from x_space[j] to x_space[j+data[i].size] get filled right after next line prob.x[i] = &x_space[j]; //将 prob 结构体的 x 成员的第 i 个元素赋值为 x_space 的第 j 个元素的地址 for (int k=0; k<data[i].size(); ++k, ++j) //循环 data[i].size() 次,同时增加 j 的值 { x_space[j].index=k+1; //将 x_space 的第 j 个元素的 index 成员赋值为 k+1,表示特征的索引 x_space[j].value=data[i][k]; //将 x_space 的第 j 个元素的 value 成员赋值为 data[i][k],表示特征的值 cout<<"x_space["<<j<<"].index = "<<x_space[j].index<<endl; //输出赋值结果 cout<<"x_space["<<j<<"].value = "<<x_space[j].value<<endl; //输出赋值结果 } x_space[j].index=-1;//state the end of data vector x_space[j].value=0; //将 x_space 的第 j 个元素的 index 成员赋值为 -1,表示特征向量的结束,将 value 成员赋值为 0 cout<<"x_space["<<j<<"].index = "<<x_space[j].index<<endl; //输出赋值结果 cout<<"x_space["<<j<<"].value = "<<x_space[j].value<<endl; //输出赋值结果 j++; //增加 j 的值 } //ok, let's try to print it for (int i = 0; i < prob.l; ++i) //循环 prob.l 次 { cout<<"line "<<i<<endl; //输出提示信息 cout<<prob.y[i]<<"---"; //输出标签 for (int k = 0; k < elements; ++k) //循环 elements 次 { int index = (prob.x[i][k].index); //获取特征的索引 double value = (prob.x[i][k].value); //获取特征的值 cout<<index<<":"<<value<<" "; //输出索引和值 } cout<<endl; //换行 } cout<<"all ok"<<endl; //输出提示信息 //set all default parameters for param struct param.svm_type = C_SVC; //将 param 结构体的 svm_type 成员赋值为 C_SVC,表示使用 C-SVM 分类器 param.kernel_type = RBF; //将 param 结构体的 kernel_type 成员赋值为 RBF,表示使用径向基核函数 param.degree = 3; //将 param 结构体的 degree 成员赋值为 3,表示多项式核函数的次数 param.gamma = 0; // 1/num_features //将 param 结构体的 gamma 成员赋值为 0,表示核函数的系数,如果为 0,则默认为 1/num_features param.coef0 = 0; //将 param 结构体的 coef0 成员赋值为 0,表示核函数的常数项 param.nu = 0.5; //将 param 结构体的 nu 成员赋值为 0.5,表示 nu-SVM 分类器或回归器的参数 param.cache_size = 100; //将 param 结构体的 cache_size 成员赋值为 100,表示内核缓存的大小(以 MB 为单位) param.C = 1; //将 param 结构体的 C 成员赋值为 1,表示 C-SVM 分类器或回归器的惩罚因子 param.eps = 1e-3; //将 param 结构体的 eps 成员赋值为 1e-3,表示停止准则的容差 param.p = 0.1; //将 param 结构体的 p 成员赋值为 0.1,表示 epsilon-SVR 回归器的损失函数的参数 param.shrinking = 1; //将 param 结构体的 shrinking 成员赋值为 1,表示是否使用启发式收缩 param.probability = 0; //将 param 结构体的 probability 成员赋值为 0,表示是否计算概率估计 param.nr_weight = 0; //将 param 结构体的 nr_weight 成员赋值为 0,表示不同类别的权重的个数 param.weight_label = NULL; //将 param 结构体的 weight_label 成员赋值为 NULL,表示不同类别的权重的标签 param.weight = NULL; //将 param 结构体的 weight 成员赋值为 NULL,表示不同类别的权重的值 //try to actually execute it model = svm_train(&prob, ¶m); //调用 svm_train 函数,用 prob 和 param 作为参数,训练 SVM 模型,并将结果赋值给 model return 0; //返回 0,表示程序正常结束 }
输出结果:
feature pushed(第1行) …… feature pushed(第300行) data size = 30 labels size = 30 prob.y[0] = 1 prob.y[1] = 2 prob.y[2] = 1 prob.y[3] = 2 prob.y[4] = 1 prob.y[5] = 2 prob.y[6] = 1 prob.y[7] = 2 prob.y[8] = 1 prob.y[9] = 2 prob.y[10] = 1 prob.y[11] = 2 prob.y[12] = 1 prob.y[13] = 2 prob.y[14] = 1 prob.y[15] = 2 prob.y[16] = 1 prob.y[17] = 2 prob.y[18] = 1 prob.y[19] = 2 prob.y[20] = 1 prob.y[21] = 2 prob.y[22] = 1 prob.y[23] = 2 prob.y[24] = 1 prob.y[25] = 2 prob.y[26] = 1 prob.y[27] = 2 prob.y[28] = 1 prob.y[29] = 2 x_space[0].index = 1(第1个数据) x_space[0].value = 0 x_space[1].index = 2 x_space[1].value = 1 x_space[2].index = 3 x_space[2].value = 2 x_space[3].index = 4 x_space[3].value = 3 x_space[4].index = 5 x_space[4].value = 4 x_space[5].index = 6 x_space[5].value = 5 x_space[6].index = 7 x_space[6].value = 6 x_space[7].index = 8 x_space[7].value = 7 x_space[8].index = 9 x_space[8].value = 8 x_space[9].index = 10 x_space[9].value = 9 x_space[10].index = -1 x_space[10].value = 0 (第2个数据) x_space[11].index = 1 x_space[11].value = 0 x_space[12].index = 2 x_space[12].value = 1 x_space[13].index = 3 x_space[13].value = 2 x_space[14].index = 4 x_space[14].value = 3 x_space[15].index = 5 x_space[15].value = 4 x_space[16].index = 6 x_space[16].value = 5 x_space[17].index = 7 x_space[17].value = 6 x_space[18].index = 8 x_space[18].value = 7 x_space[19].index = 9 x_space[19].value = 8 x_space[20].index = 10 x_space[20].value = 9 x_space[21].index = -1 x_space[21].value = 0 …… (第30个数据) x_space[319].index = 1 x_space[319].value = 0 x_space[320].index = 2 x_space[320].value = 1 x_space[321].index = 3 x_space[321].value = 2 x_space[322].index = 4 x_space[322].value = 3 x_space[323].index = 5 x_space[323].value = 4 x_space[324].index = 6 x_space[324].value = 5 x_space[325].index = 7 x_space[325].value = 6 x_space[326].index = 8 x_space[326].value = 7 x_space[327].index = 9 x_space[327].value = 8 x_space[328].index = 10 x_space[328].value = 9 x_space[329].index = -1 x_space[329].value = 0 line 0 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 1 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 2 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 3 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 4 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 5 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 6 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 7 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 8 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 9 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 10 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 11 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 12 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 13 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 14 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 15 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 16 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 17 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 18 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 19 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 20 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 21 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 22 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 23 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 24 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 25 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 26 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 27 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 28 1---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 line 29 2---1:0 2:1 3:2 4:3 5:4 6:5 7:6 8:7 9:8 10:9 all ok * optimization finished, #iter = 15 nu = 1.000000 obj = -30.000000, rho = 0.000000 nSV = 30, nBSV = 30 Total nSV = 30参考网址
https://github.com/cjlin1/libsvm
https://github.com/niosus/SVM_example
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/40681.html