

作者丨安静怡
学校丨吉林大学
研究方向丨神经网络模型压缩
近日,小米 AI 实验室 AutoML 团队展示了最新成果 MoGA (作者:初祥祥,张勃,许瑞军),超过由 Google Brain 和 Google AI 强强联合的代表作 MobileNetV3 ,并且公布了 MoGA 源码和预训练模型。MoGA 将真实场景的使用设备移动端 GPU 作为考量,模型可以直接服务于手机端视觉产品。


截止发稿,谷歌还未公布 V3 的模型代码,小米 AutoML 团队此时推出 MoGA ,在 ImageNet 1K 分类任务 200M 量级从移动端 GPU 维度超过 MobileNetV3。可以说,该方法基于 FairNAS 改进,且结果也超过了 FairNAS。
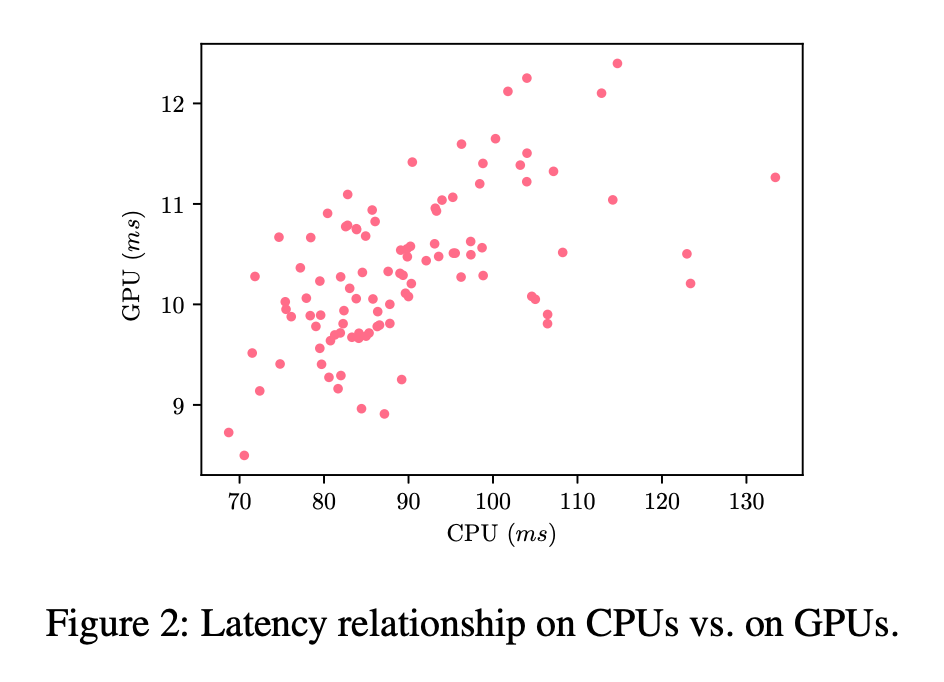
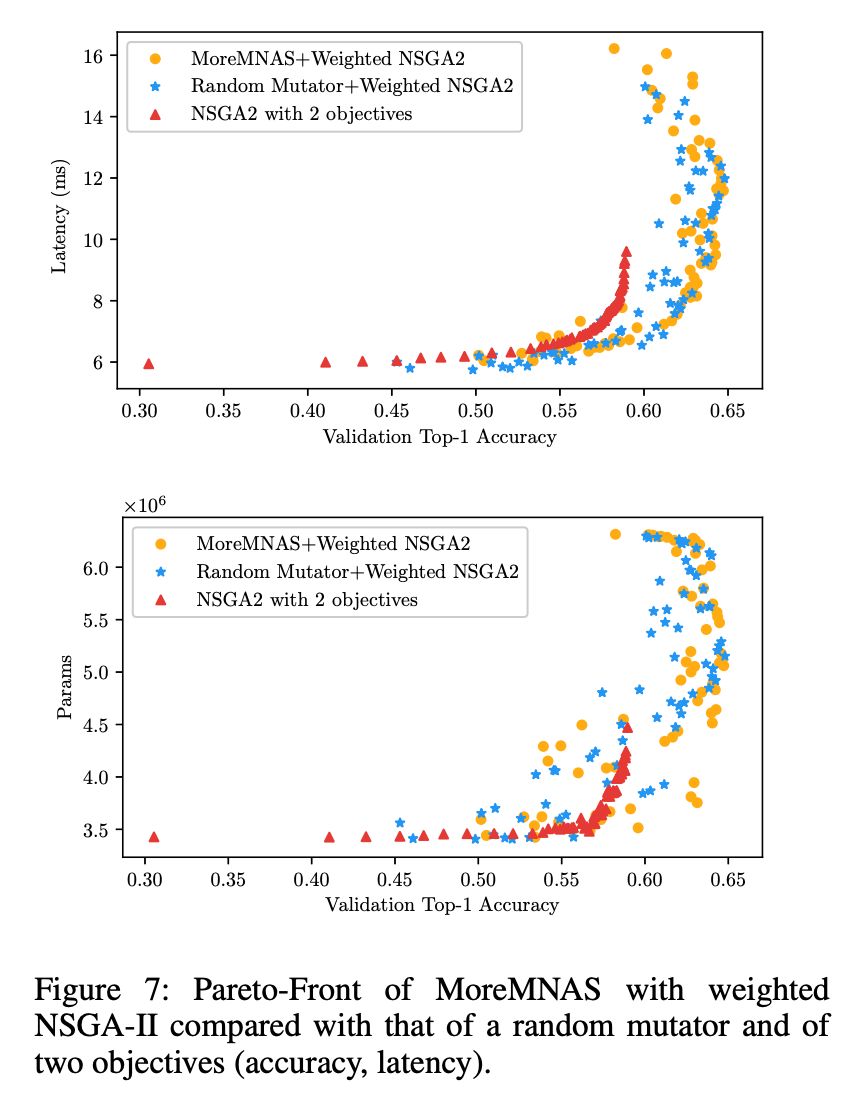
源码: https://github.com/xiaomi-automl/MoGA MoGA 这篇文章第一个新颖点是 Mobile GPU-Aware(MoGA),即从实际使用角度,设计移动端 GPU 敏感的模型。过去的研究普遍只考虑移动端 CPU 的延迟,但实际使用的时候往往都运行在 GPU 上,两者的延迟并非简单的线性,不仅和硬件相关,还是框架实现相关,参见 Fig2 根据采用的搜索空间中随机采样的 100 个模型对应的 CPU/GPU 运行时间绘制的散点图。
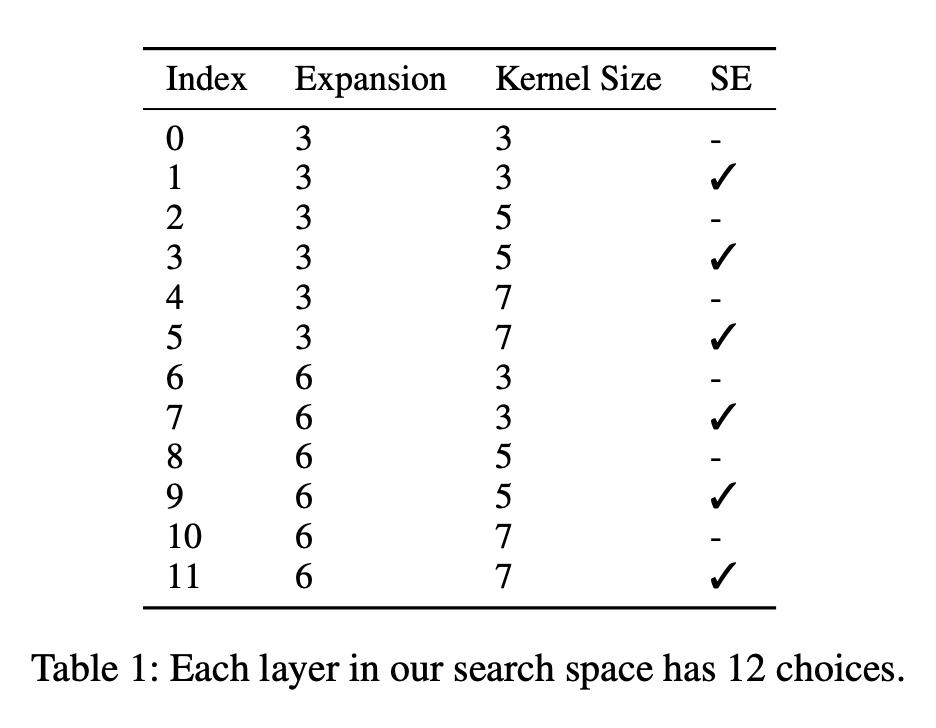
在 FairNAS 基础上,MoGA 每层的可选择运算模块(choice block)从 6 个增加到了 12 个,超网的训练依然很快收敛。
文章的第二个观点来自于对 MobileNet 三部曲的分析 ,从V1 到 V3,各项指标均在提升,但模型参数量反而增多。这对设计多目标的优化条件给出了方向。文章认为,除了业务指标 Top-1 Acc,模型在设备端的运行时间是作为衡量模型的关键指标,而非乘加数,所以在目标中剔除乘加数。
另外,之前的方法都是在尽量压缩参数量,这对多目标优化极为不利。在非损人不能利己的帕累托边界上,必须有舍才有得。文章认为,参数量是模型能力的表征,所以选择鼓励增加参数量反而能增大搜索范围,从而获得高参数但低时延的模型。
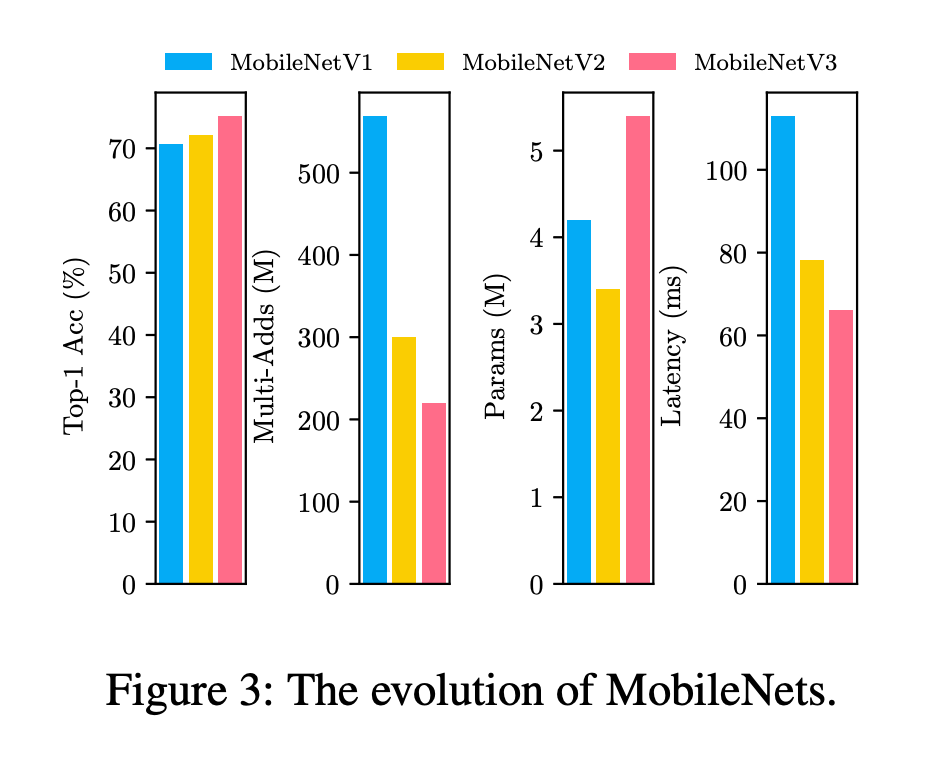
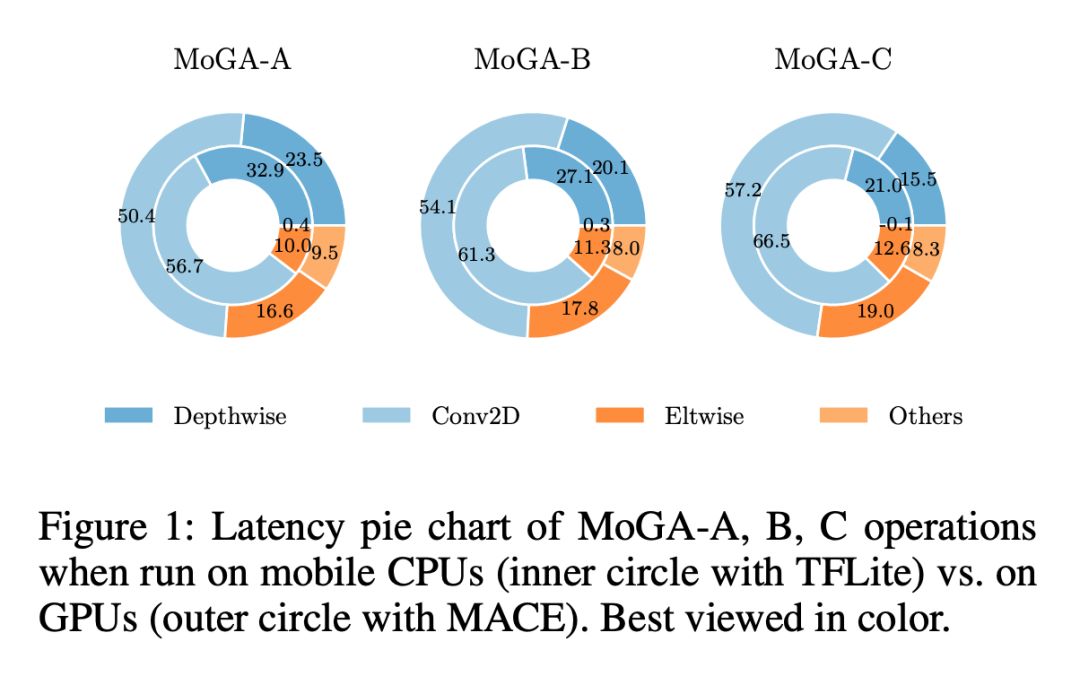
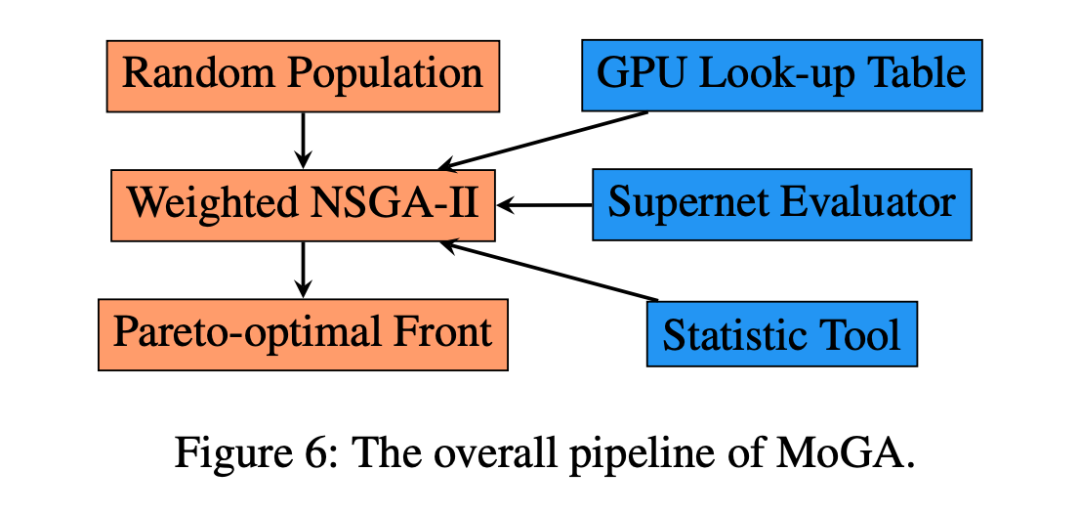
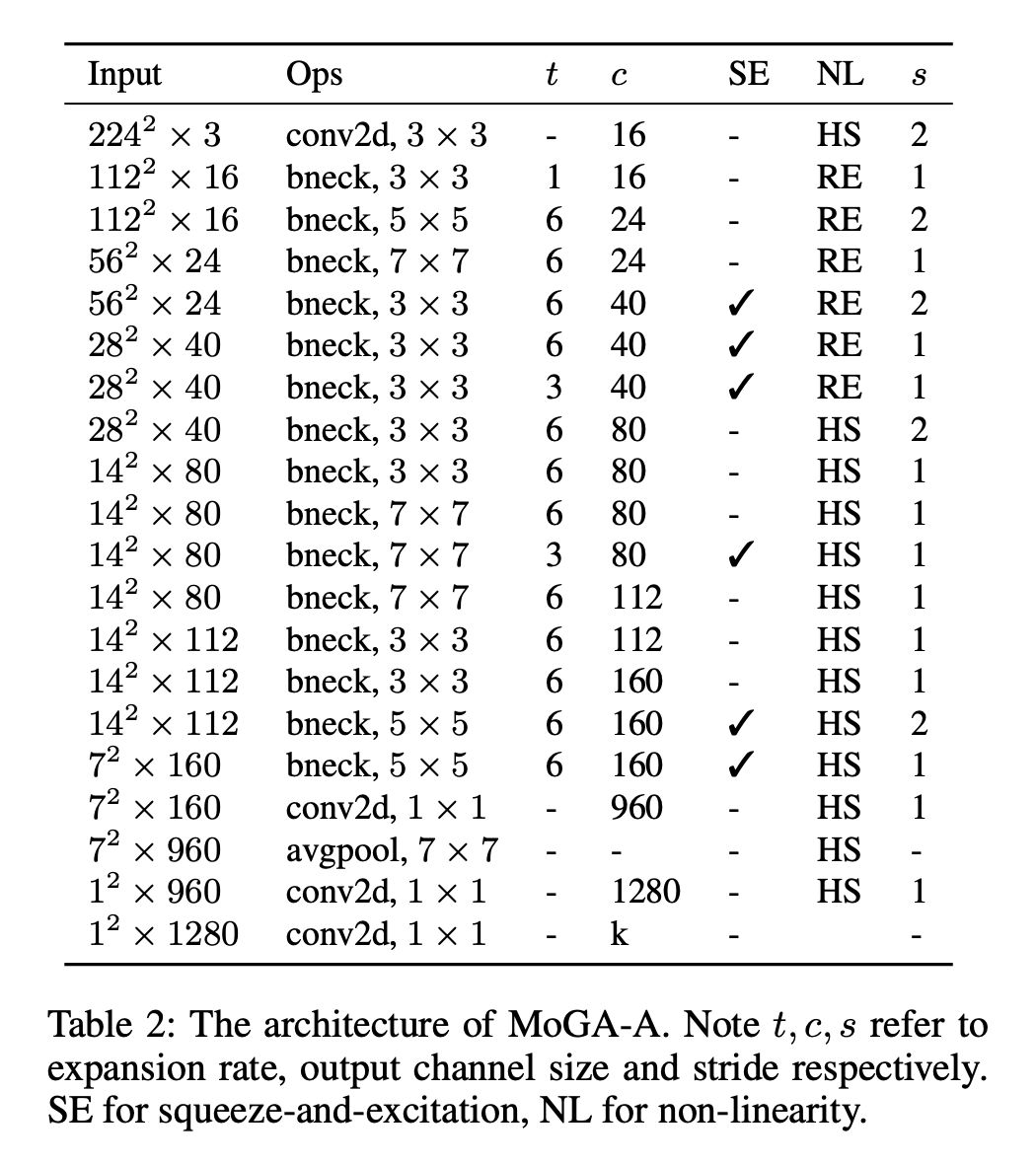
图 9 给出了三款模型 MoGA-A,B,C 的可视化展示。
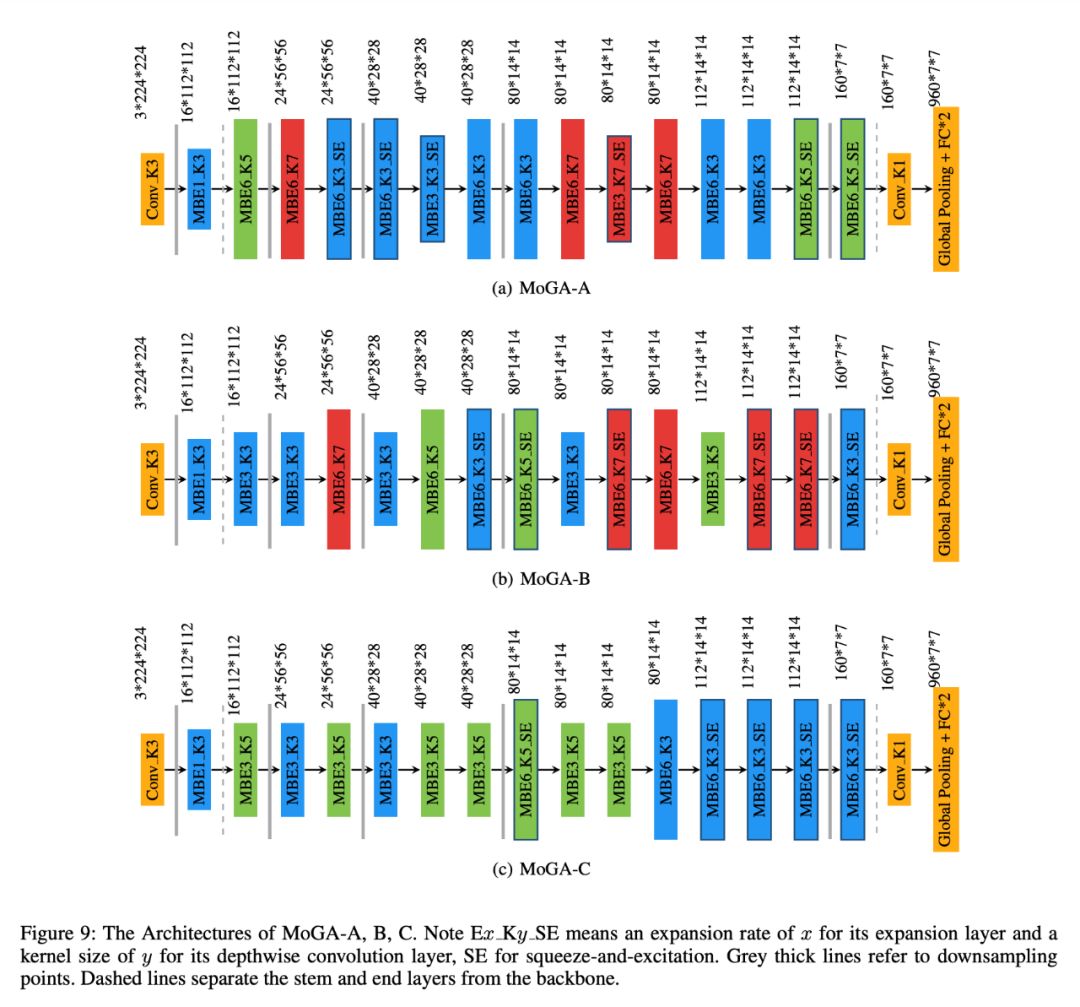
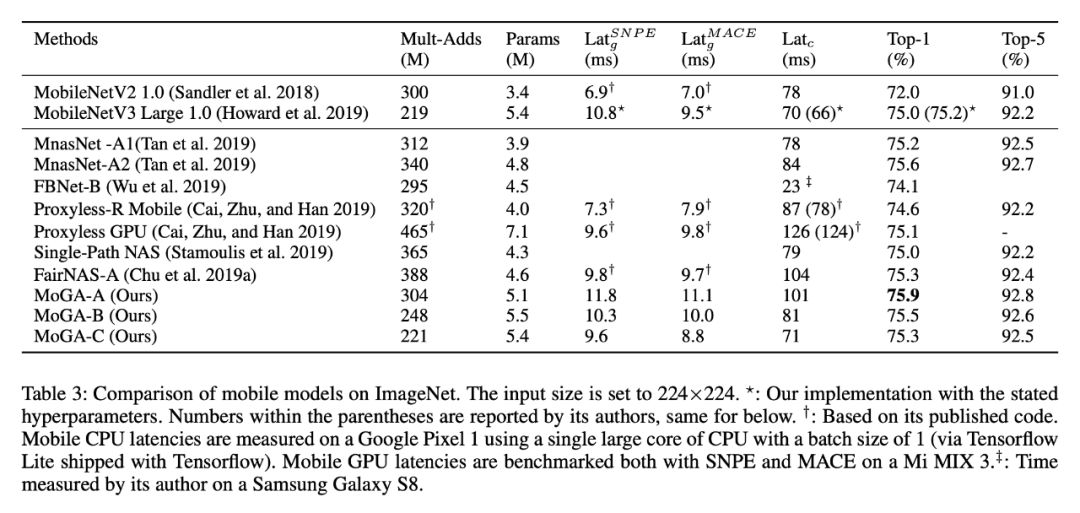
表 3 是对当前同量级 SOTA 模型的对比。MoGA-C 比 MobileNetV3 Large 有更高的精度,更短的移动端 GPU 时延(SNPE、MACE 结果一致),从 SNPE 结果看,MoGA-B 也超过了 V3,所以本文揭示了不仅要 GPU-Aware,还需要 Framework-aware,不同的框架对模型也有不同的要求。另外 300M 模型 MoGA-A 也是再次刷新记录,达到了 75.9%。
消去实验
总结
参考文献
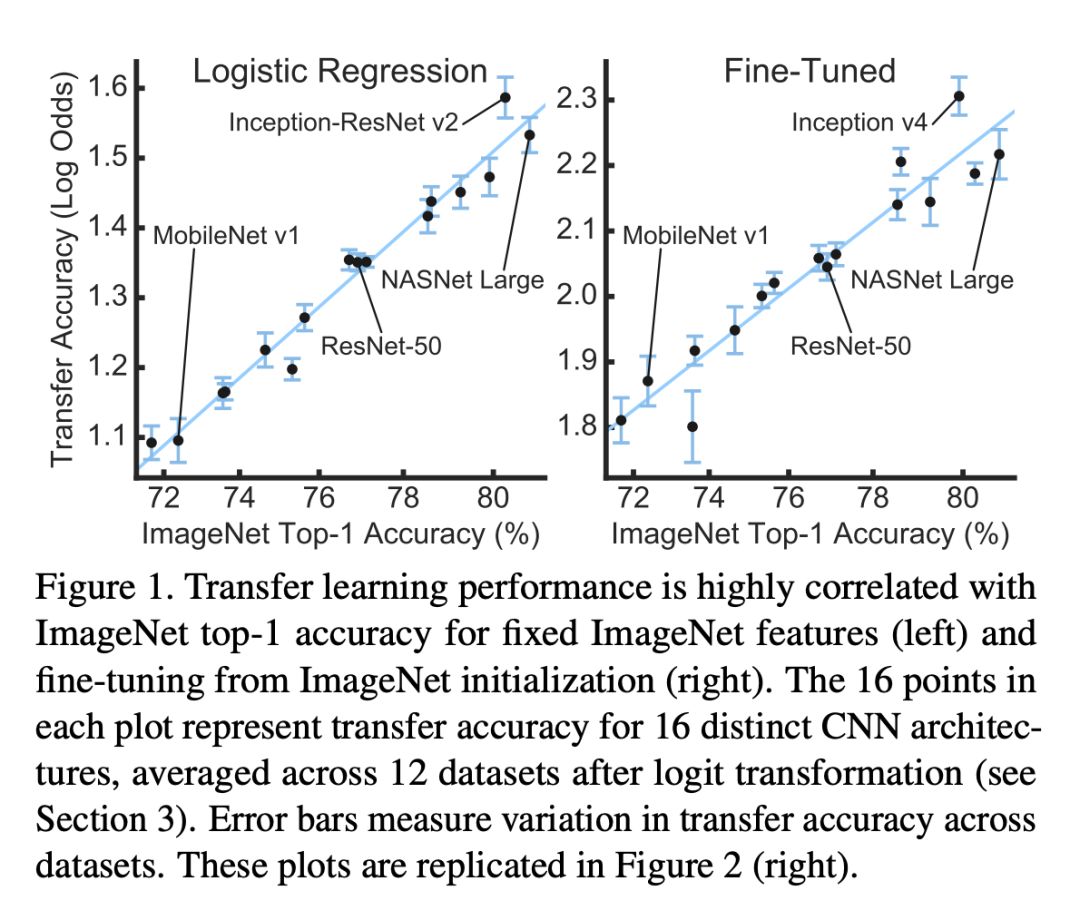
[1] Chu et al. MoGA: Searching Beyond MobileNetV3 http://arxiv.org/abs/1908.01314 [2] MoGA 模型开源地址:https://github.com/xiaomi-automl/MoGA [3] Chu et al., FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search https://arxiv.org/abs/1907.01845 [4] FairNAS 模型开源地址:https://github.com/xiaomi-automl/FairNAS [5] Chu et al., Multi-Objective Reinforced Evolution in Mobile Neural Architecture Search https://arxiv.org/abs/1901.01074 [6] Andrew Howard et al., Searching for MobileNetV3, https://arxiv.org/abs/1905.02244 [7] Kornblith et al., Do Better ImageNet Models Transfer Better https://arxiv.org/pdf/1805.08974.pdf
点击以下标题查看更多往期内容:
- KDD Cup 2019 AutoML Track冠军团队技术分享

- 神经网络架构搜索(NAS)综述 | 附资料推荐
- 小米拍照黑科技:基于NAS的图像超分辨率算法
- 深度解读:小米AI实验室最新成果FairNAS
- 自动机器学习(AutoML)最新综述
- NAS-FPN:基于自动架构搜索的特征金字塔网络

 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/34792.html