
隐性语义索引(Latent Semantic Indexing,以下简称LSI ),有的文章也叫Latent Semantic Analysis(LSA )。其实是一个东西,后面我们统称LSI ,它是一种简单实用的主题模型。它是一种利用奇异值分解(SVD )方法获得在文本中术语和概念之间关系的索引和获取方法。该方法的主要依据是在相同文章中的词语一般有类似的含义,可以从一篇文章中提取术语关系,从而建立起主要概念内容。
隐性语义索引(Latent Semantic Idexing),也可译为隐含语义索引,是近年来逐渐兴起的不同于关键词检索的搜索引擎解决方案,其通过海量文献找出词汇之间的关系,当两个词或一组词大量出现在同一个文档中时,这些词之间就可以被认为是语义相关。比如:
(1)"手机"和"电话"这两个词在人们写文章时经常混用,这两个词在大量的网页中同时出现,搜索引擎就会认为这两个词是极为语义相关的。
(2)"Latent Semantic Idexing"和"隐性语义索引"(虽然一个是英语,一个是中文)这两个词大量出现在相同的网页中,虽然搜索引擎还不能知道"Latent Semantic Idexing或"隐性语义索引"指的是什么,但是却可以从语义上把"Latent Semantic Idexing"、"隐性语义索引"、"LSI "、"潜在语义索引"等词紧紧的连在一起。可见潜在语义索引并不依赖于语言。
(3)如梨子和李子这两个词,也是大量出现在相同文档中,不过紧密度低于同义词。所以搜索引擎不会认为它们是语义相关的。
(4)对“水”一词而言,与其语义相关的可能是“热水”、“凉水”之类,但潜在相关的则可以是“蒸汽”、“ 冰”等,这里有很大区别。
隐性语义索引使得检索结果的实际效果更接近于人的自然语言,在一定程度上提高检索结果的相关性,目前已被逐渐的应用到图书馆、数据库和搜索引擎的算法当中。Google是典型的代表。本文分利用前面已学的SVD 知识,讲解如何用SVD 进行信息检索的隐性语义检索(LSI ),并用实例进行分析。
首先简要回顾下SVD :对于一个m×n 的矩阵M,可以分解为下面三个矩阵:![]()
为了降低矩阵的维度到k ,SVD 的分解可以近似的写为:
![]()
SVD 可以看作是从单词-文档矩阵中发现不相关的索引变量(因子),将原来的数据映射到语义空间内。LSI 使用SVD 来对单词-文档矩阵进行分解,其本质上是把每个特征映射到了一个更低维的子空间(sub space) 。如果把上式用到我们的主题模型,则SVD 可以这样解释:我们输入的有m个文本,每个文本有n个词。而![]() 则对应第
则对应第![]() 个文本的第
个文本的第![]() 个词的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD 分解后,
个词的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD 分解后,![]() 对应第i
对应第i![]() 个文本和第
个文本和第![]() 个主题的相关度。
个主题的相关度。![]() 对应第j个词和第m个词义的相关度。
对应第j个词和第m个词义的相关度。![]() 对应第l个主题和第m个词义的相关度。
对应第l个主题和第m个词义的相关度。
也可以反过来解释:我们输入的有m个词,对应n个文本。而![]() 则对应第i个词档的第j个文本的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD分解后,
则对应第i个词档的第j个文本的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD分解后,![]() 对应第i个词和第l个词义的相关度。
对应第i个词和第l个词义的相关度。![]() 对应第j个文本和第m个主题的相关度。
对应第j个文本和第m个主题的相关度。![]() 对应第l个词义和第m个主题的相关度。
对应第l个词义和第m个主题的相关度。
这样我们通过一次SVD,就可以得到文档和主题的相关度,词和词义的相关度以及词义和主题的相关度。
下面来说一下如何利用SVD进行信息检索的LSI方法:
设M是一个mn维,秩为r的词汇-文档矩阵;
1.利用SVD方法将矩阵M分解转化成多个矩阵的乘积,即 ;
;
2.利用SVD分解降维后的结果来构造一个新的、改进的词汇-文档矩阵C’;
3.通过C’得到一个更好的计算相似度的方法;
4.向之前一样按相似度高低输出文档结果。
实例分析:
下面我们举个例子来说明:![]()
C为一个词项-文档矩阵,为方便,这里使用的是布尔矩阵。m为词项数目,n为文档数目。

U中每个词项对应一行,每个语义维度对应一列,矩阵中的元素Uil![]() 给出的是词项i和第l个语义维度的关系强弱程度。可以想象这些列向量分别代表了不同的语义维度,比如:政治、体育、娱乐、财经等主题。U是个正交矩阵。
给出的是词项i和第l个语义维度的关系强弱程度。可以想象这些列向量分别代表了不同的语义维度,比如:政治、体育、娱乐、财经等主题。U是个正交矩阵。

Σ中对角元素是矩阵C的奇异值。奇异值的大小度量的事相应的语义维度的重要性。

VT中每一列对应一篇文档,每一行对应一个语义维度,![]() 代表的是文档j与语义维度的关系强弱程度。矩阵VT是一个正定矩阵。
代表的是文档j与语义维度的关系强弱程度。矩阵VT是一个正定矩阵。


在这里我们通过忽略较小的奇异值,即忽略较小的奇异值对应的语义维度来达到降维的目的。不过必须提醒的是,无论是上述哪一种降维方法,都会造成信息的偏差,进而影响后续分类/聚类的准确率。 降维是希望以可接受的效果损失下,大大提高运行效率和节省内存空间。然而能不降维的时候还是不要降维(比如你只有几千篇文档要处理,那样真的没有必要降维)。
在本例题中这里假设忽略后2个小于等于1的语义维度,相当于U、VT 矩阵上的相应维度被忽略。此时的矩阵分别记为记为Σ3,U3,VT3。

原矩阵C做奇异值分解后得到的矩阵Σ对角元素舍去小于等于1的奇异值后,得到的矩阵Σ3。

原矩阵C奇异值分解后,对应Σ3的变化,将矩阵 U后两列元素记为0。
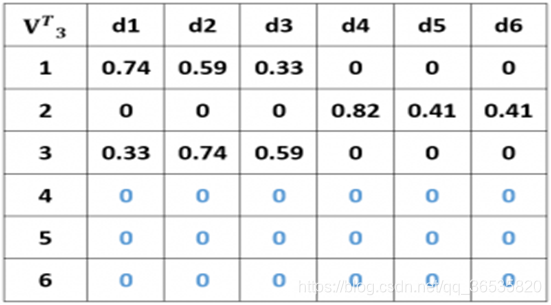
对矩阵C做奇异值分解,利用奇异值分解降维后的结果来构造一个新的、改进的词汇-文档矩阵C’=U3 * Σ3* VT3

矩阵C’可以看做是矩阵C的一个二位表示。
在上面我们通过LSI得到的文本主题矩阵(C’)可以用于文本相似度计算。而计算方法一般是通过余弦相似度。余弦相似度计算公式如下所示:
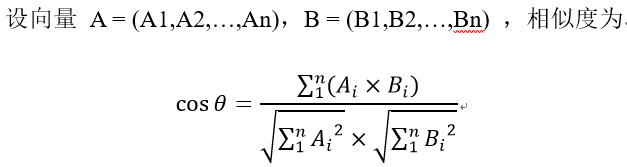
则对于上面的三文档两主题的例子。我们可以计算第一个文本和第二个文本在C与C’的余弦相似度如下 :

通过余弦相似度求得文档一与文档二在原词汇-文档矩阵中和新词汇-文档矩阵的相似度分别为0.044、0.761,相似度有所提高。可以知道原文档的相关性不高,通过LSI将它们映射到低维空间后,两者的相似度会提高。因此可知LSI能够解决一词多义与语义关联问题。
总结:
LSI是最早出现的主题模型了,它的算法原理很简单,一次奇异值分解就可以得到主题模型,同时解决词义的问题,非常漂亮。但是LSI有很多不足,导致它在当前实际的主题模型中已基本不再使用。主要的问题有:
1.SVD计算非常的耗时,尤其是我们的文本处理,词和文本数都是非常大的,对于这样的高维度矩阵做奇异值分解是非常难的。
2.主题值的选取对结果的影响非常大,很难选择合适的k值。
3.LSI得到的不是一个概率模型,缺乏统计基础,结果难以直观的解释。
对于问题1,主题模型非负矩阵分解(NMF)可以解决矩阵分解的速度问题。对于问题2,大部分主题模型的主题的个数选取一般都是凭经验的,较新的层次狄利克雷过程(HDP)可以自动选择主题个数。对于问题3,人们整出了pLSI(也叫pLSA)和隐含狄利克雷分布(LDA)这类基于概率分布的主题模型来替代基于矩阵分解的主题模型。
对于一些规模较小的问题,如果想快速粗粒度的找出一些主题分布的关系,则LSI是比较好的一个选择,其他时候,如果你需要使用主题模型,推荐使用LDA和HDP。
参考文献:
[1] We Recommend a Singular Value Decomposition(Feature Column from the AMS)。
[2] 徐树方,《矩阵计算的理论与方法》,北京大学出版社。
[3]http://blog.csdn.net/zhongkejingwang/article/details/
注:如果你在其它地方看到一篇一模一样的文章,嘻嘻,不用怀疑,是同一个人写的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/33961.html