
1、快照的概念
1.1创建一个快照不同的设备需要不同的命令,但对于系统来说,基本都包括如下几个步骤:
1、首先发起创建指令
2、在发起时间点,指令通知操作系统暂停应用程序和文件系统的操作
3、刷新文件系统缓存,结束所有的读写事务
4、创建快照点
5、创建完成之后,释放文件系统和应用程序,系统恢复正常运行。
1.2 快照在不同层级的实现
在IT设备的不同层级都会有相应的产品去实现快照,而且不同的存储产品也经常会使用多种技术实现快照。
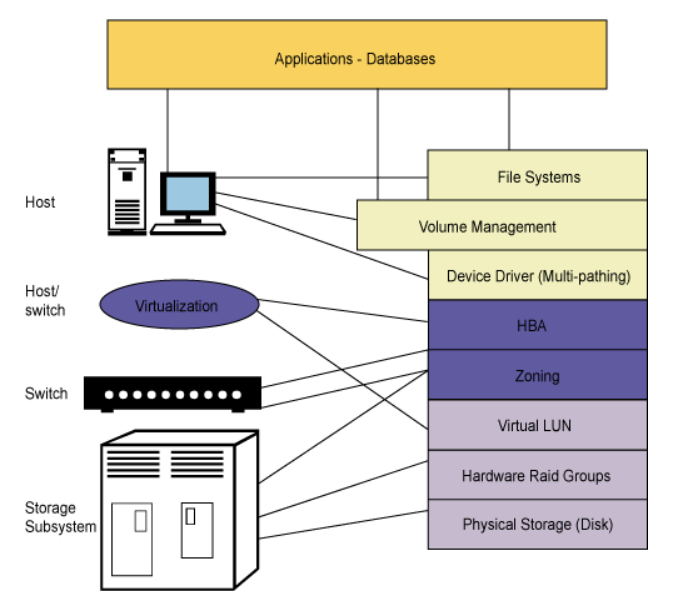
广义的快照技术通常可有7个不同类型的实现主体:
1、主机文件系统(包括服务器、台式机、笔记本电脑) 2、逻辑卷管理器(LVM) 3、网络附加存储系统(NAS) 4、磁盘阵列 5、存储虚拟化设备 6、主机虚拟化管理程序 7、数据库。 讯享网
基于文件系统和LVM的快照
1.2.1 基于文件系统的快照
很多文件系统都支持快照功能,免费是文件系统快照的优势之一,因为它集成在文件系统内部;另一个优点是非常好用,最新版文件系统的快照功能通常使用起来很简单。但存在的劣势是每个文件系统都必须独立进行管理,当系统数量激增时,管理工作会变得非常繁重
1.2.2 基于LVM逻辑卷管理器快照
我们可以创建跨多个文件系统的LVM快照。像赛门铁克的Veritas Volume Manager可以支持大多数常见的操作系统和文件系统。LVM通常还包括存储多路径和存储虚拟化等功能。
基于NAS和磁盘阵列的快照
1.2.3 基于NAS的快照
1.2.4 基于磁盘阵列的快照
基于磁盘阵列的快照与基于NAS的快照有非常相似的优点,即所有与磁盘阵列相连的计算机系统都可以使用这种标准的通用快照功能。
基于存储虚拟化的快照技术
1.2.5 基于存储设备的快照
这里所说的存储虚拟化设备主要用于SAN光纤网络环境,不同于基于文件(NFS)应用的网络设备,像F5 Network公司的Acopia ARX产品就是排除在这个范畴之外的。主要的存储虚拟化软硬件存储设备(或融合了虚拟化功能的存储系统)都支持快照能力。
1.2.6 基于主机虚拟化软件的快照
随着服务器虚拟化应用的普及,基于主机虚拟化管理软件(Hypervisor)的快照技术也逐渐流行起来。像Citrix公司的 XenServer、微软的Hyper – V、SUN的xVM Ops Center、以及VMware的ESX和vSphere4等主机虚拟化产品都支持快照功能。
1.2.7 基于数据库的快照
在数据库中,快照动作被称为“SnapShot Isolation(快照隔离)”,这点在SQL Server中应用比较多(其6个事物隔离级别中的一个就是snapshot isolation)
1.3 快照的分类

- Clone or split mirror 克隆或镜像分离
- Copy-on-write with background copy 后台拷贝的复制写
- 写时拷贝 (Copy-On-Write),COW
- 写时重定向 (Redirect-On-Write),ROW
二、快照实现原理
2.1 Clone or split mirror 克隆或镜像分离
Clone(或Split-Mirror)快照所创建的是数据的完整副本。
- clone:顾名思义,就是完整复制数据,需要在没有写入的时候复制,这样数据才具有一致性。
- split mirror:
讯享网
如下图,先创建一个原始卷的镜像卷,每次写磁盘的时候,都会往原始卷和快照卷同时写入内容,当启动快照时,则镜像卷能快速脱离,生成一个快照卷。 然后重新创建一个原始卷的镜像卷,等待下次快照。
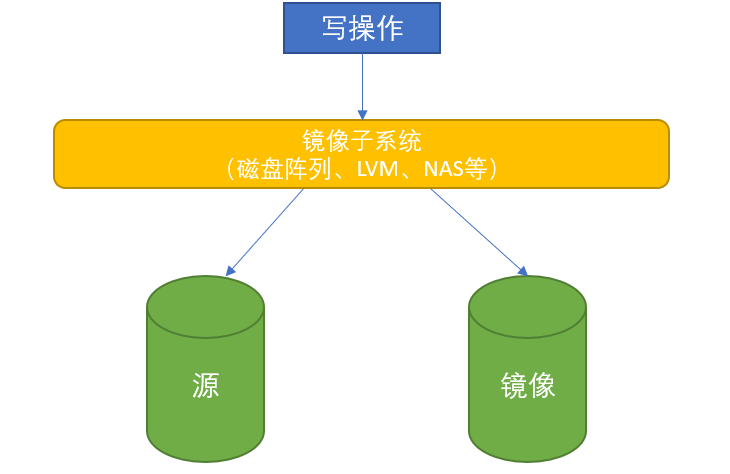
可以看到这种方案最大的缺点是很费磁盘空间,每个快照都需要占用和原始卷同样的空间,而且写数据时同时写两份,对写入性能影响比较大。 优点是快照生成和恢复都方便,而且数据隔离很好,不存在快照卷和原始卷的相互影响。 2.2 Copy-on-write with background copy 后台拷贝的复制写
该快照有两个生成步骤,首先创建一个瞬时即可生成的COW快照,然后利用后台进程将数据卷的数据复制到快照空间,最后生成一份数据卷的克隆或镜像。
讯享网创建这种快照的目的是发挥COW快照的优势,同时尽量屏蔽它的不足。因此,这种快照常常被形容为COW和Clone快照的混合体。
2.3 COW快照(copy on write)
2.3.1 COW快照原理:
- 每个源数据卷都具有一张数据指针表(元数据),简称源数据指针表,表记录就是指向相应源数据块的地址指针。
- 在创建快照时,存储子系统会建立源数据指针表的一个副本(元数据拷贝),作为快照卷的数据指针表,简称快照数据指针表。
- 在创建快照之后,这个快照就相当于一个可供上层应用访问的存储逻辑副本,快照卷与源数据卷通过各自的指针表共享同一份物理数据。
- 当源数据卷中任意数据将要被改写时,COW会在原始数据修改之前进行拷贝到快照卷中,然后将新数据写入到源数据块中覆盖原始数据,并且将原始数据在快照卷中的新地址更新到快照数据指针表记录中,使快照时间点后更新的数据不会出现在快照卷中。
2.3.2 图解原理
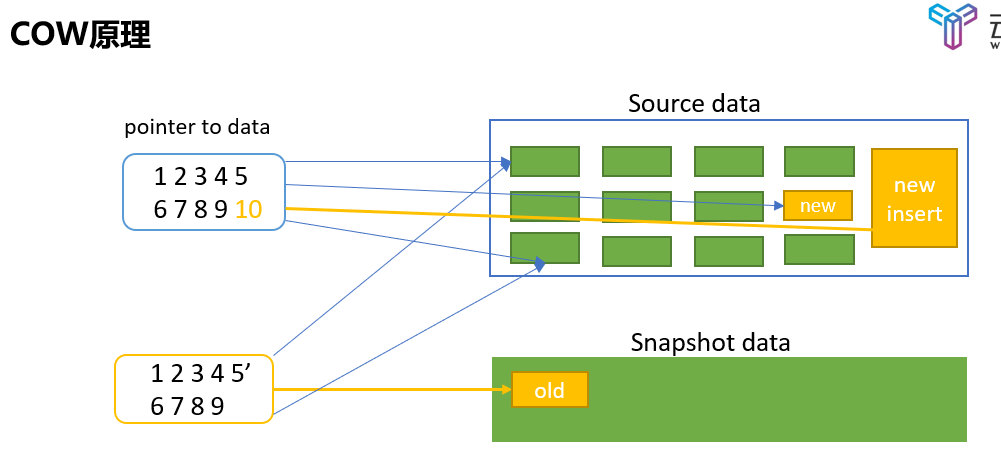
- 在创建快照时,会同时创建快照卷和快照数据指针表。快照卷只需要很少的存储空间;
- 更改数据时,会拷贝旧数据到快照卷,源数据会被覆盖,快照指针表的地址会更新;插入新数据,自然是不会对快照卷有影响。
- 再次创建快照,会再次拷贝源数据指针表,新的修改会记录到旧的快照卷和新的快照卷。
2.3.3 优缺点
- 优点:原始卷物理块连续,没有碎片
- 缺点:降低源数据卷的写性能,每首次更新数据,至少进行两次写操作。
2.3.4 注意
- 只有首次对原始数据进行更改的数据会被拷贝到快照卷;
- 源数据指针表至此至终都不会发生变化;
- 如果执行了多次快照,那么对一个数据的修改会有多次写操作,导致
读写延时较大;
2.4 ROW快照(redirect on write)
2.4.1 ROW快照原理
- ROW 的实现原理与 COW 非常相似,区别在于ROW 对原始数据卷的首次写操作,会将新数据重定向到预留的快照卷中,而非 COW 一般会使用新数据将原始数据覆盖。
- 所以,ROW 快照中的原始数据依旧保留在源数据卷中,并且为了保证快照数据的完整性,在创建快照时,源数据卷状态会由读写变成只读的。
2.4.2 图解原理
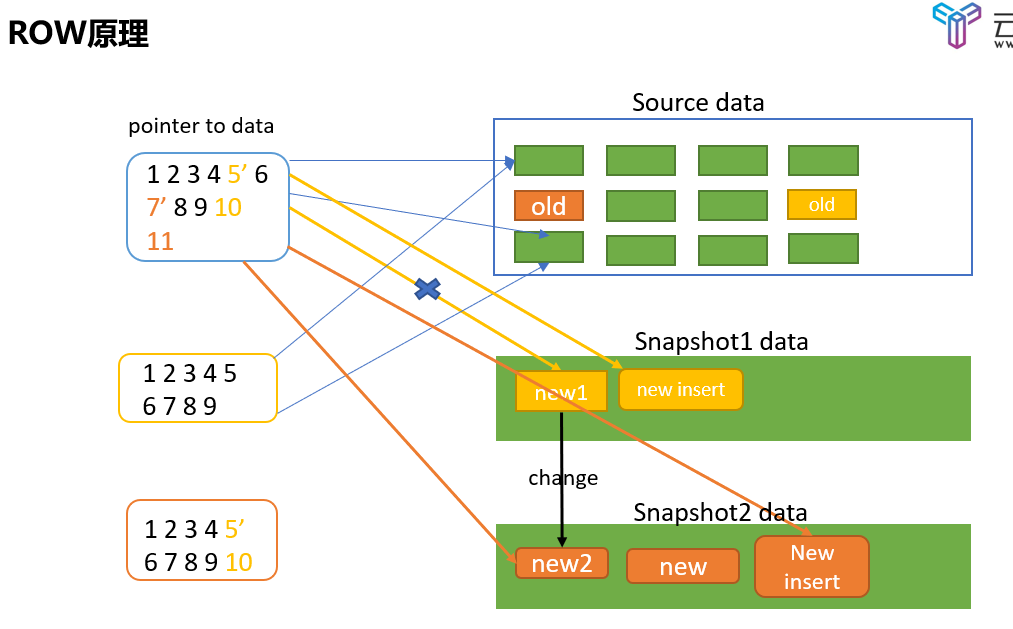
- 创建快照时,也会copy一份源数据指针表作为快照数据指针表,此时两张表的指针记录都相同;
- 发生了写操作,那么新数据会直接被写入到快照卷中,然后再更新源数据指针表的记录,使其指向新数据所在的快照卷地址;
- 再次创建快照,会再次copy一份源数据指针表,新的修改会写入到新的快照卷;
- 因为源数据指针表上有上次快照的修改和新增数据,所以显然快照之间的关系是链式,恢复后面的快照需要源数据以及全面的快照作为基础。
2.4.3 优缺点
- 优点:写性能基本没有损耗,只是修改指针
- 缺点:没有一个完整的快照卷,其快照之间的关系是链式,如果快照层级越多,进行快照恢复时的系统开销会比较大;
2.4.4 删除中间快照原理
假设需要删除快照链中的某一份快照S1,则流程示意图和逻辑概览如下所示:
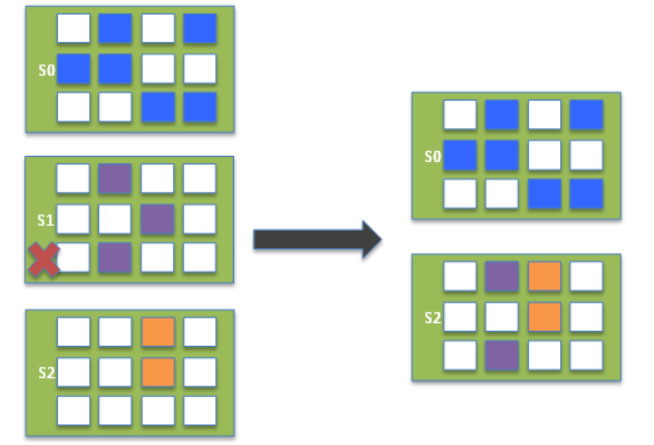
- 阿里云离线分析已删除快照S1的所有数据块(Block),删除未被快照链中其他快照引用的数据块。
- 添加快照S1脏数据块到快照S2。剩下的快照一共记录了10个Block的信息:
- 快照S0的6个
- 快照S1的2个脏数据块
- 快照S2的2个。
2.5 COW和ROW小结及使用场景
- COW的快照卷存放的是原始数据,而 ROW的快照卷存放的是新数据。
- 根据以上的介绍,可以总结的是COW的写性能开销较大,但是存储的数据是顺序的,适合顺序读取。所以其适合读多写少场景。
- ROW的写性能基本没有损耗,但是其数据会变得非常离散(源数据指针表记录被更新),所以其连续读写性能不如COW。
- 在分布式场景下,读取不再是性能瓶颈,数据越分散,性能越高,所以现阶段,ROW + 分布式存储的快照方式是业界发展的主要方向。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/33584.html