
摘要(abstract)
虽然深度学习在许多模式识别任务中都取得了良好的效果,但对于含有大量参数集、标记数据有限的深度网络,过拟合问题仍然是一个严重的问题。在这项工作中,二进制自动编码器(BAEs)和叠置二进制自动编码器提出了一种从大规模无标记人脸数据集中学习领域知识的方法。通过将知识转移到另一个基于二值化神经网络(BNNs)的带有限标记数据的监督学习任务,可以提高BNNs的性能。将无约束人脸归一化方法与LBP描述符、BAEs和BNNs的变体相结合,构建了一个真实的人脸表情识别系统。实验结果表明,整个系统在野外(SFEW)基准测试中取得了良好的静态面部表情性能,硬件要求最低,内存和计算成本较低。
1. 介绍(Introduction)
面部表情的研究是由心理学家发起的。Mehrabian等人[1]提出,同时发生的言语、声音和面部态度交流的综合效应是它们各自独立效应的加权和,系数为分别为7%、38%和55%。面部表情在人机交互(HCI)、情感计算、人类行为分析等方面发挥着重要作用。面部动作编码系统(FACS)[2]与情绪面部动作编码系统(EMFACS)[3]是由Ekman和Friensen提出的。FACS和EMFACS定义了一组行为单元(AUs),与愤怒、厌恶、恐惧、快乐、悲伤和惊讶等六种基本情绪相关。AUs和six basic emotions成为机器学习中分类/检测任务最常用的表达标签。
在早期,面部表情识别(FER)的研究是基于使用专门的记录设备在实验室环境中记录的数据集。一些数据集包含了摆态表达式[4],另一些数据集包含了自发表达式[5]。现有的识别方法可以分为三种类型,基于几何的方法[6-8],基于外观的方法[9-11]和混合方法[12]。基于几何的方法利用地标的位置、地标之间的距离、网格中三角形的角度等作为目标一维特性。基于外观的方法使用全局图像或地标周围的局部小块来提取各种二维图像特征。这些方法取得了显著的效果。本文主要研究无约束FER问题,这是目前研究的一个热点。不受约束的人脸包含头部姿态、表情强度、光照条件、背景、遮挡和其他扭曲的变化[13-15]。这些条件与现实世界中的条件非常接近。无约束的FER是一个具有挑战性的未解决问题。
研究趋势表明,基于卷积神经网络(CNNs)的FER方法越来越受欢迎。在最近的表情挑战中采用最先进的方法[16]为例。Alex-Net [17,18], VGG-Net [19-21], GoogLeNet[21,22]和各种CNNs[18,20,23]用于无约束拿来。在这些研究中,外部数据如TFD数据集[24],FER-2013年数据集[25],使用CAISA Web人脸数据集[26](18、20、21、23)。决策融合被广泛应用于提高4-7%的性能[18,20,21,23]。
CNNs的基本假设是图像的不同区域具有相同的局部统计特性。这个假设不适用于对齐的面。包含本地连接的CNNs 提出了385-395 layer[27]来缓解这一问题。然而,局部连接层有大量的参数。在小数据集上进行训练是不切实际的。此外,训练/测试时间长、内存开销大是这些基于CNNs的方法的常见缺点。本文介绍了一种新型的全连通神经网络代替神经网络。我们认为,在人脸对齐和不变特征的帮助下,全连通神经网络仍然是广泛应用于人脸的一个很好的选择。
近年来,使用二进制权值或激活的神经网络得到了越来越多的关注。从硬件的角度来看,这些二进制权值和激活可以加速网络的反向传播(BP)和正向传播。它们还可以降低记忆峰训练和测试的成本。噪声权重也作为一个强大的正则化器,以防止过拟合。一个设计良好的算法可以在性能损失可接受的情况下具有这些优点。本文研究了二值化神经网络(BNNs)[28]和二值化自编码器在FER系统中,BAEs作为分类器和特征提取器。
这项工作的主要贡献包括:
•基于新的二值化神经网络(BNNs)[28],提出了一种无监督的特征学习方法——二值化自编码器(BAE)。BAEs可以学习外部大规模无标记人脸数据集的特征,提高监督学习任务的性能。
•一种称为多尺度密集局部二进制的低层图像特性提出了一种基于模式(MDLBP)的人脸识别信息提取方法
•据我们所知,本文是第一个将二进制特征提取器、二进制无监督特征学习器和二进制神经网络结合到真实的FER系统中。该系统以最少的硬件需求(即,降低内存和计算成本)
论文的其余部分组织如下:第二部分对相关工作进行回顾。在第三节中,提出了主要方法。实验结果见第4节。第五部分给出结论。
2. 相关工作(Related work)
2.2 二值化神经网络(Binarized Neural Networks)
具有二进制权值或激活的神经网络在[28-31]等文献中得到了广泛的研究。预期反向传播(EBP)[29,30]是一种训练具有二元权值和激活的神经网络的训练算法。二进制连接[31]是另一种使用二进制权值+实权值+训练时的实激活值和测试时的二进制权值+实激活值的方法。包括但不限于上述的研究都有使用真实值的局限性。这些实值限制了神经网络的速度。灵感来自于EBP和二进制连接,二值化神经网络[28]在训练和测试中同时使用二进制权值和二进制激活。本文是基于BNNs的扩展工作。BNNs的核心思想是,权值和活度都被限制为+1或- 1。用xnorcount操作代替浮点数乘法累加操作,将给快速传播带来极大的好处。将al、Wl、bl分别表示为l层BNN的激活、权值的实版、偏置,利用递归式
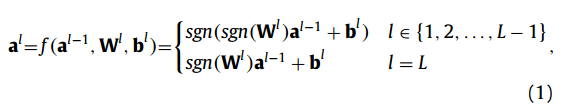
其中sgn是矩阵和向量的元素符号函数。由两个sgn函数引起的噪声,通过对多个二进制分量sgn(Wl)sgn(···)求和得到平均。二值化对正向传播的精度影响不大。L层BNN的末端是最终的活化aL。在分类或二元多元回归时,在末端附加铰链损耗。损失函数定义为
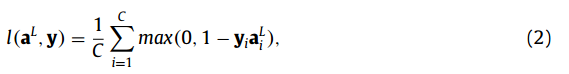
其中C为aL的维数,为类数或二元多元回归的目标维数。y是二进制教学向量,其元素要么为+1,要么为-1。由于铰链损耗在yiaL i = 1时是不可微的,因此采用子梯度来实现算法。
将第i个训练对表示为(xi, yi),可以将BNNs的训练问题定义为
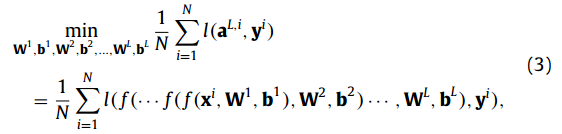
其中aL,i是xi输入网络时的最终激活。
在训练过程中保持二进制和真实版本的权重是很重要的。二进制版本用于正向传播和反向传播,而实际版本用于权重更新。有关向后传播和权重更新的详细信息,请参阅[28]。
2.2. Auto-encoders
2.3. 深度二进制表示(Deep binary representations)
二值化自动编码器(BAEs)用于学习大规模未标记人脸数据集中紧凑的二值化人脸表示。无监督哈希算法[34]与BAEs非常相似。它们都是从长原始数据中计算一个短二进制代码。但是,它们是为不同的任务而设计的。贝叶斯压缩的比特可以用来重建原始数据。BAEs擅长于基于神经网络的分类或回归任务特征提取。然而,设计良好的哈希代码可以保持本地数据结构。通过计算哈希码之间的汉明距离,可以测量数据的相似性。
2.4. 无约束的脸标准化(2.4. Unconstrained face normalization)
在真实的FER系统中,无约束人脸归一化通常是第一步。它通常集成了现有的几种人脸图像预处理算法,包括人脸地标检测、人脸对齐和光照归一化。一个无约束的面部图像可以包含零个或多个不同姿态和任意光照条件下的人脸。在这项工作中,使用方向梯度直方图检测紧边界框(HOG)特征与线性分类器、图像金字塔和滑动窗口检测方案[35]相结合。为简便起见,如果没有检测到框,则拒绝样本。否则,只保留最大的盒子。采用基于回归[36]的路标检测器对这些边界盒中的路标进行检测。对人脸的三维形状进行[37]估计。人脸对齐到一个预定义的三维人脸几何图形。边界盒检测器和地标检测器在iBUG 300-W人脸地标数据集[38]by上进行预训练King等人。[39]。在LFW数据集上对对齐模型进行了预处理《[40]》,哈斯纳等人著。

试验了两种光照归一化方法。基于各向同性扩散的方法(IN-IS)利用图像的各向同性平滑来估计光照函数,然后对其进行补偿。基于离散余弦变换的方法(in -DCT)将低频段的DCT系数截断为零[42]。对于无约束人脸归一化,两种方法都能获得良好的视觉效果。应该注意的是,IN是一个可选步骤,特别是在使用LBP特性时。关于如何使用IN和LBP的更多细节将在后面讨论4.3节。
2.5. 局部二值模式(Local Binary Patterns)
局部二值模式[43]及其变化在人脸图像处理中得到了广泛的应用。Chen等人提出了一种基于高维LBP[44]的人脸验证方法。迪豪等。采用局部相位量化(LPQ)[10,13],是该方法的扩展采用线性SVM分类器进行分类。赵等人提出了LBP-TOP[45]用于表情动作识别[14,45]。利等。提出了一种改进LBP码的映射方法,并将映射后的LBP码作为CNNs[21]的输入。这些研究中要么使用LBP直方图,要么使用LBP编码图。在这项工作中,使用了LBP代码映射的一个变体。该功能是一组单热模式码,它描述了在不同的位置,在不同的分辨率模式。它是一个W×H×P的稀疏二元三维张量,其中W×H为图像维数,P为模式数。
空间LBP映射称为稠密LBP (DLBP)描述符。空间LBP映射称为稠密LBP (DLBP)描述符。表示裁剪后的人脸图像的强度通道为I∈RW×H,即一热均匀旋转不变码映射为映射,定义I的DLBP描述符为
![]()
其中,在位置i处采样的p位模式码j定义为
![]()

![]()
![]()
p、r、s分别为采样邻域数、半径和步长。P是数的均匀和旋转不变的模式。
2.6. 基于gpu的并行计算
在实际应用中,应认真实现BNN、BAE和FER算法,以达到其理论性能。基于图形处理单元(GPU)的并行计算是实现高性能算法的一种流行技术。例如,Liu等人提出了一种基于GPU[46]的高效的稀疏PCA并行算法。该算法与并行实现是两个正交的研究方向。本文的主要目的是提出一种高效的FER算法。我们基于gpu的并行实现的详细信息可以在源代码[47]中找到。
3. 提出的方法(The proposed method)
局部二值模式(LBP)描述符[43]是一种强大的图像分类工具。多尺度稠密LBP (MDLBP)包含一组稠密LBP (DLBP)描述符,用于提取不同分辨率下的模式。每个位置说明:DLBP描述符,局部模式描述为一个热代码。然后将矢量化的特征输入到堆叠的二进制自动编码器(堆叠BAE)中进行无监督的特征学习。然后将矢量化的特征输入到堆叠的二进制自动编码器(堆叠BAE)中进行无监督的特征学习。
3.1. Binarized Auto-encoders
基于BNNs的二进制自动编码器(BAEs)可以直接由自动编码器(AEs)扩展而来。它包含两个二值化的完全连接层,即编码层和解调层。表示二进制输入向量x,二进制中间表示xˆh和二进制重建,我们可以定义编码层
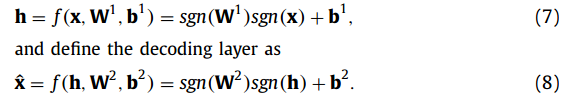
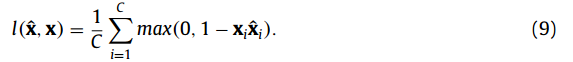
如果x是一个稀疏向量(number of +1 elements <<number of-1 elements, e.g., the sparsity of the MDLBP feature is 1 - 1P ) or a dense vector (number of +1 elements>>number of -1 elements),式(9)中的损失函数可能无法评价实际重建性能。Eq.(9)可以通过元素重加权的方法得到改进。将x的稀疏性表示为s,可以将BAE的再加权损失函数定义为
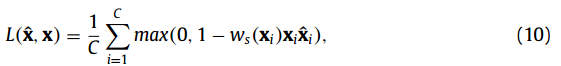
元素加权为



二值化自动编码器和二值化神经网络。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/29326.html