
最近在使用claude code时,突然发现一个问题:
在同一轮对话中,为什么我token的消耗量,总是有那么几次特别高?如下图所示: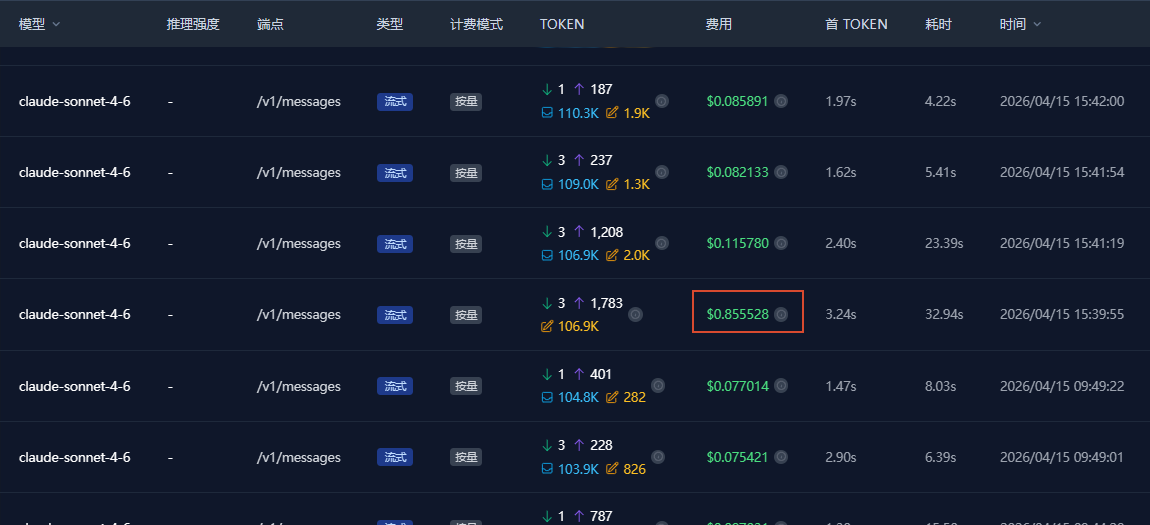
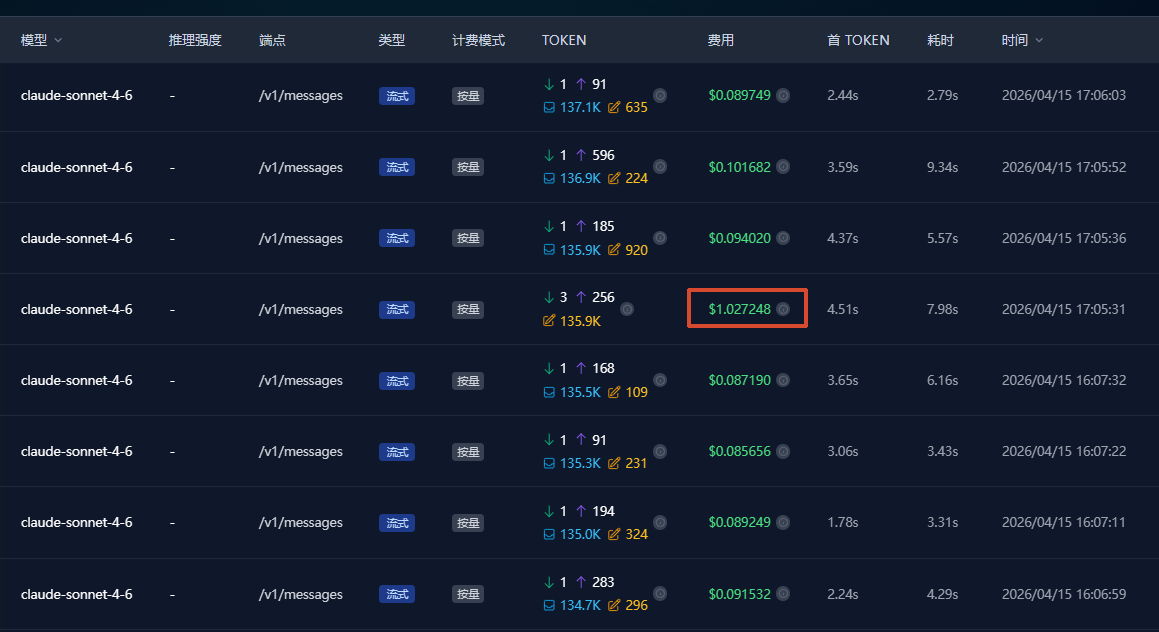
可以看到,前后几次请求消耗的token都是正常值,只有这么一下特别高。
我们都知道,每次发消息给模型,都会带上之前几轮对话的上下文。
那么,每次新对话其实带上的上下文有很大部分都是重复的。
不能让重复的数据白白耗费不必要的token呀。
所以,缓存功能诞生。
缓存机制:其核心在于"空间换时间",它将模型对输入文本处理后的中间计算结果(Key 和 Value 向量)保存在显存中。如果不使用缓存,模型每生成一个新词,都需要重新计算前面所有词的关系,这会导致计算量随字数增加呈指数级增长;有了缓存后,模型只需计算当前新产生的 Token,并直接读取内存里的"既定记忆",从而消除了重复劳动,大幅降低了计算成本与响应延迟。
在实际运行中,流程分为预填充、解码两个阶段。首先,系统会对你输入的 Prompt 进行一次性处理,将生成的 KV 向量存入缓存层;随后进入生成环节,模型每预测出一个新 Token,就会将其计算结果实时更新到缓存中,供下一个词的生成使用。如果是支持 Context Caching 的长文本场景,系统还会对固定内容进行持久化存储,当你再次调用相同背景资料时,模型会直接跳过预填充阶段,实现瞬间"唤醒"并开始回答。
接着,我们再说一下token的价格组成:
- 输入(Input): 你给模型的"原材料",模型一次性读取并理解,计算效率高,价格最便宜。
- 输出(Output): 模型吐出的"成品",由于需要逐字推理生成,消耗算力最大,价格最贵。
- 缓存(Cache): 预先存好的"半成品",将重复使用的长文本存在内存里,省去了重复计算,大幅降低了成本和延迟。
缓存的token的价格是要比输入输出token的价格更低的,所以这也是为什么能省钱的原因。
那么回到我们最开始的问题,为什么我的token消费时高时低?
只有一种可能——平时对话时,命中缓存,消费低。当缓存过期时,下一次对话不仅无法命中花奴才能,还要重新构建缓存,这就造成消费高。
再看刚刚的截图,消费高的那一轮对话,和上一轮对话的间隔时间通常都比较长。这也再次印证了,确实是缓存过期的问题。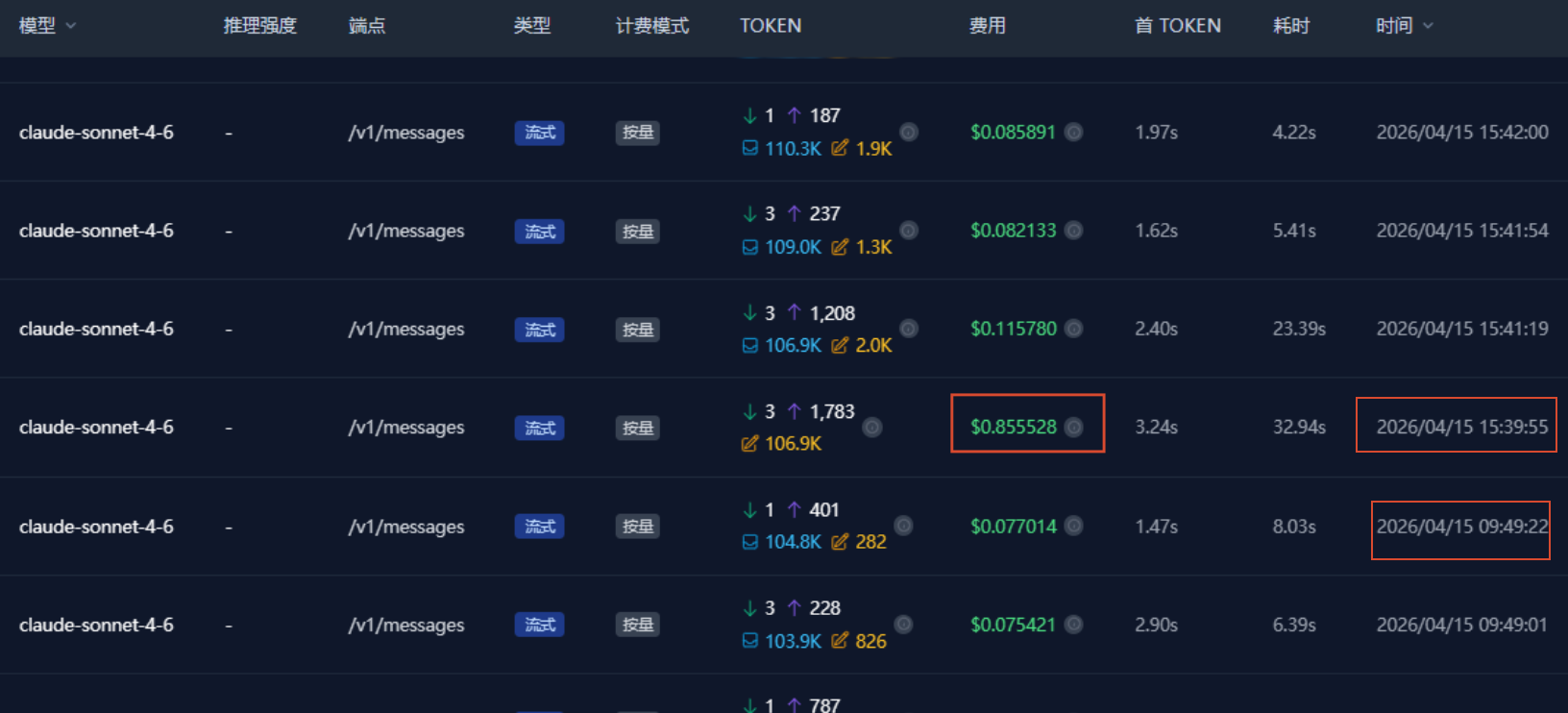
关于缓存过期的时间:
在之前,anthropic设定的缓存时间一直是1h,但在前几天,anthropic将缓存时间改为了5min。这也造成了越来越频繁的缓存过期问题,token消费自然也就高了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/271278.html