
这篇文章来自 Sebastian Raschka 大神,这篇文章的核心观点是:编程智能体之所以比普通聊天式 LLM 更强,往往不是单靠模型本身,而是靠 live repo context、提示词缓存、结构化工具、上下文压缩、会话记忆和有边界委派等系统设计共同撑起来的。
最后作者还对比了编程工具Codex,Claude Code和OpenClaw的区别到底是什么。
如果你对最近正流行的各种AI概念有迷惑,那么本文正好适合你。
第 1 段 · 先抛出总问题:编程智能体到底由什么组成
In this article, I want to cover the overall design of coding agents and agent harnesses: what they are, how they work, and how the different pieces fit together in practice.
在这篇文章里,作者想系统介绍编程智能体与智能体脚手架的整体设计:它们是什么、如何运作,以及各个部件在实际中怎样彼此配合。
Readers of my Build a Large Language Model (From Scratch) and Build a Large Reasoning Model (From Scratch) books often ask about agents, so I thought it would be useful to write a reference I can point to.
不少读者在看完他关于大语言模型和推理模型的书后,常常会继续追问“智能体到底是怎么回事”,所以他想写一篇可以反复引用的系统性说明。
重点词汇与表达
第 2 段 · 为什么这个话题重要:真实进步很多来自“怎么用模型”
More generally, agents have become an important topic because much of the recent progress in practical LLM systems is not just about better models, but about how we use them.
更广义地说,智能体之所以成为重要议题,是因为近来许多实用型 LLM 系统的进步,并不只是来自模型更强,还来自我们如何使用模型。
In many real-world applications, the surrounding system, such as tool use, context management, and memory, plays as much of a role as the model itself. This also helps explain why systems like Claude Code or Codex can feel significantly more capable than the same models used in a plain chat interface.
在很多真实应用里,工具调用、上下文管理和记忆等外围系统,与模型本身一样重要。这也解释了为什么 Claude Code 或 Codex 这类系统,往往会让人觉得比相同模型在普通聊天界面里更能干。
重点词汇与表达
第 3 段 · 先把 Claude Code 和 Codex 放到正确位置上
Claude Code or the Codex CLI are essentially agentic coding tools that wrap an LLM in an application layer, a so-called agentic harness, to be more convenient and better-performing for coding tasks.
Claude Code 和 Codex CLI 本质上都是“把 LLM 包在应用层里的编程智能体工具”。这层应用层,也就是所谓的 agentic harness,会让模型在编码任务里更方便也更高效。
Coding agents are engineered for software work where the notable parts are not only the model choice but the surrounding system, including repo context, tool design, prompt-cache stability, memory, and long-session continuity.
编程智能体是为软件工作专门工程化出来的系统。真正关键的并不只有模型选择,还有代码仓上下文、工具设计、提示词缓存稳定性、记忆,以及长会话延续能力。
重点词汇与表达
第 4 段 · 把 LLM、推理模型、agent、harness 分清楚
An LLM is the core next-token model. A reasoning model is still an LLM, but usually one that was trained and/or prompted to spend more inference-time compute on intermediate reasoning, verification, or search over candidate answers.
LLM 是核心的 next-token 模型。推理模型本质上仍然是 LLM,只是通常经过训练和提示优化,会在中间推理、验证或候选答案搜索上投入更多推理时算力。
An agent is a layer on top, which can be understood as a control loop around the model. Typically, given a goal, the agent layer decides what to inspect next, which tools to call, how to update its state, and when to stop.
智能体则是套在模型外层的一层控制循环。给定一个目标之后,agent 会决定下一步检查什么、调用什么工具、怎样更新状态,以及什么时候结束。
Roughly, the LLM is the engine, a reasoning model is a beefed-up engine, and an agent harness is what helps us use the model inside a working system.
粗略地说,LLM 像引擎,推理模型像强化版引擎,而 agent harness 则是帮助我们把这个引擎真正装进可运作系统里的那一层。
重点词汇与表达
第 5 段 · 作者真正想强调的是:harness 往往决定实际体验
Coding work is only partly about next-token generation. A lot of it is about repo navigation, search, function lookup, diff application, test execution, error inspection, and keeping all the relevant information in context.
编码工作只是在一部分层面上属于“继续生成 token”。更大一部分其实是代码仓导航、搜索、函数定位、应用 diff、运行测试、查看报错,以及在整个过程中维持相关上下文。
The takeaway here is that a good coding harness can make a reasoning and a non-reasoning model feel much stronger than it does in a plain chat box.
这里的核心 takeaway 是:一个好的 coding harness,会让推理模型和非推理模型都显得比在普通聊天框里更强。
重点词汇与表达
第 6 段 · 组件一与二:实时代码仓上下文 + 稳定提示前缀缓存
When a user says “fix the tests” or “implement xyz,” the model should know whether it is inside a Git repo, what branch it is on, and which project documents might contain instructions.
当用户说“修好测试”或“实现某功能”时,模型最好知道自己是不是在 Git 仓库里、当前分支是什么、哪些项目文档可能带有指令。
The coding agent collects stable facts as a workspace summary upfront so that it is not starting from zero on every prompt.
因此,coding agent 会先收集一组稳定事实,整理成 workspace summary,而不是每次都在零上下文中重新开始。
Smart runtimes do not rebuild everything as one giant undifferentiated prompt on every turn. They keep a stable prompt prefix and only update the parts that change frequently, such as short-term memory, recent transcript, and the newest request.
聪明的 runtime 不会在每一轮都把所有信息重新拼成一个巨大而不分层的 prompt。它们会保留一个稳定的 prompt prefix,只更新那些变化更频繁的部分,比如短期记忆、最近的 transcript 和最新用户请求。
重点词汇与表达
第 7 段 · 组件三:真正像 agent 的地方,是结构化工具调用
A plain model can suggest commands in prose, but an LLM in a coding harness should be able to execute the command and retrieve the results.
普通模型只能在文字里建议你去执行某个命令;但处在 coding harness 里的 LLM,应该能够真正执行命令,并把结果拿回来继续用。
Instead of letting the model improvise arbitrary syntax, the harness usually provides a predefined list of allowed tools with clear inputs and boundaries.
与其让模型自由发挥任意语法,不如由 harness 提供一份预先定义好的工具列表,每个工具都有清晰的输入格式和边界。
The runtime can then ask: Is this a known tool? Are the arguments valid? Does this need user approval? Is the path inside the workspace?
这样一来,runtime 就可以程序化地检查:这是已知工具吗?参数合法吗?需不需要用户批准?目标路径是不是在工作区之内?
重点词汇与表达
第 8 段 · 组件四:很多“模型质量”,其实是上下文质量
Coding agents are even more susceptible to context bloat than regular LLMs during multi-turn chats, because of repeated file reads, lengthy tool outputs, and logs.
与普通 LLM 多轮聊天相比,编程智能体更容易遭遇上下文膨胀,因为它们会反复读取文件、产生长工具输出和日志。
A good coding harness clips large outputs, deduplicates older file reads, and compresses the transcript before it goes back into the prompt.
好的 coding harness 会裁剪大输出、去重旧文件读取记录,并在内容重新喂回 prompt 前压缩 transcript。
A lot of apparent model quality is really context quality.
很多表面上的“模型质量”,其实本质上是“上下文质量”。
重点词汇与表达
第 9 段 · 组件五:记忆要分层,不能一股脑塞给模型
A coding agent usually separates state into at least two layers: a small working memory and a full transcript.
一个成熟的 coding agent 通常至少会把状态分成两层:一层是小而精炼的 working memory,另一层是完整的 transcript。
The full transcript stores the whole history and makes the session resumable. The working memory is a distilled version that keeps the most important current information.
完整 transcript 保存整个历史,因此会话可以恢复;working memory 则是经过提炼的版本,保留当前最重要的信息。
The compact transcript is for prompt reconstruction, while the working memory is for task continuity.
compact transcript 的职责是帮助重建 prompt,而 working memory 的职责则是维持任务连续性。
重点词汇与表达
第 10 段 · 组件六:委派有用,但前提是“有边界”
Once an agent has tools and state, one of the next useful capabilities is delegation.
当一个智能体已经拥有工具和状态之后,下一项非常有价值的能力就是委派。
A subagent is only useful if it inherits enough context to do real work. But if we do not restrict it, multiple agents may duplicate work, touch the same files, or keep spawning more subagents.
子智能体只有在继承了足够上下文时才真正有用;但如果不给它边界,多个智能体就可能重复劳动、碰同一批文件,甚至不断继续生出更多子智能体。
The design challenge is not only how to spawn a subagent, but how to bind one.
因此,真正的设计难题并不只是“怎样生成一个子智能体”,而是“怎样把它约束住”。
重点词汇与表达
第 11 段 · 最后的比较:OpenClaw 不是同一种产品,但有很多重叠
OpenClaw is more like a local, general agent platform that can also code, rather than being a specialized coding assistant.
OpenClaw 更像是一个本地的通用智能体平台,它也能写代码,但并不是一个高度专门化的 coding assistant。
There are still several overlaps with a coding harness: it uses workspace instruction files, keeps session files, performs transcript compaction, and can spawn helper sessions and subagents.
不过它和 coding harness 依然有许多重叠之处,例如读取工作区指令文件、保存会话文件、做 transcript compaction,以及生成 helper session 和 subagent。
The emphasis is different: coding harnesses optimize for a person working in a repository, while OpenClaw optimizes for many long-lived local agents across chats, channels, and workspaces.
真正的区别在于优化目标不同:coding harness 主要优化“人在仓库里高效完成编码任务”,而 OpenClaw 更偏向“在多个聊天、频道和工作区里运行长生命周期本地智能体”。
重点词汇与表达

说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
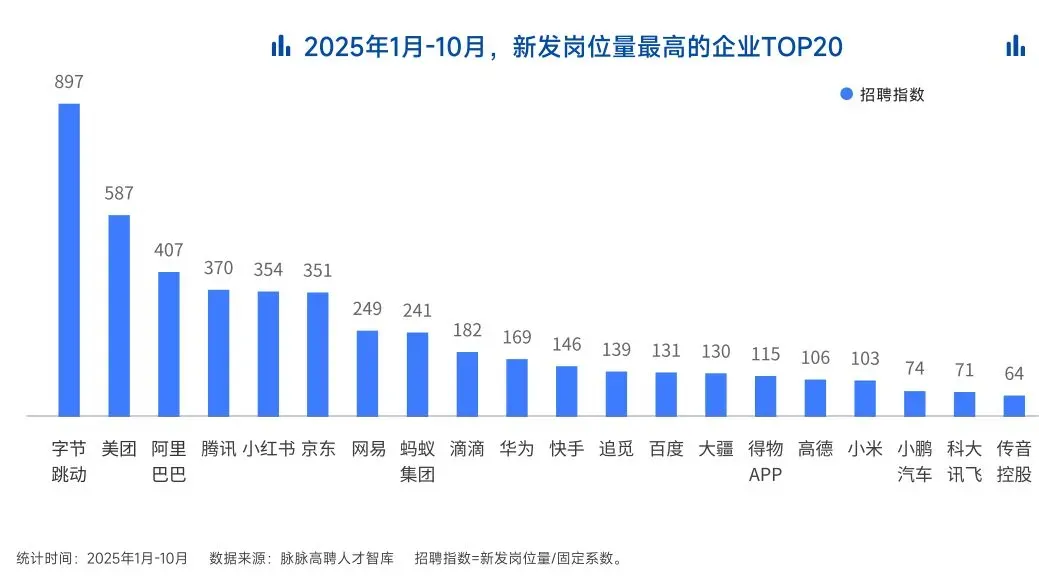
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的**路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/267722.html