
github:https://github.com/deepseek-ai/DeepSeek-OCR-2
huggingface:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
这会不会是DeepSeek V4发布前上的前菜呢?
其实DeepSeek-OCR-2 从其Benchmark看来,算不上SOTA,更多是是之前工作DeepSeek-OCR的延伸。
DeepSeek-OCR 发布于25年10月,而这次OCR2发布仅隔了三个月。DeepSeek最近老玩OCR,是否意味着V4是个多模态模型?(管你啥模态模型,别又再过年发布了求你了)
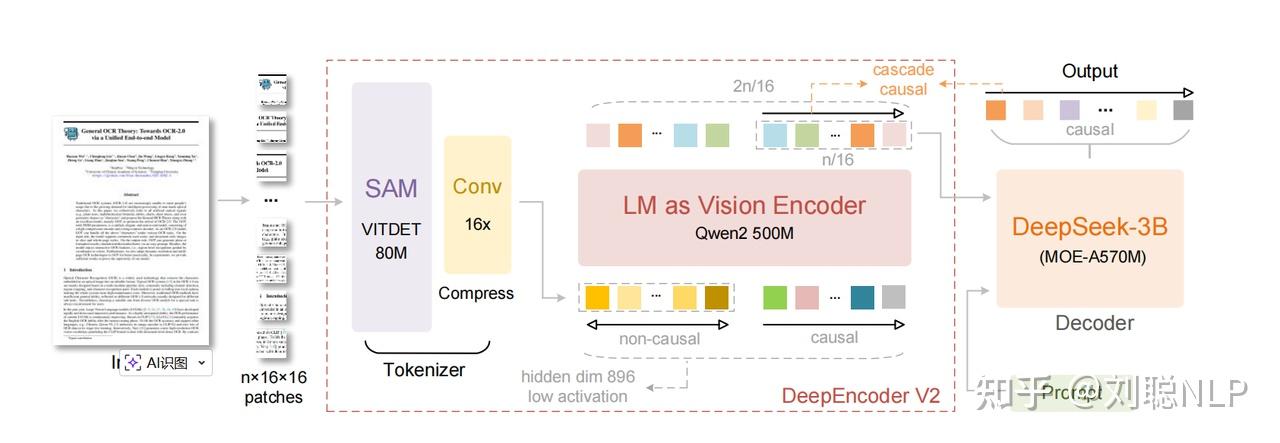
这次OCR2的改动主要在Deep Encoder。
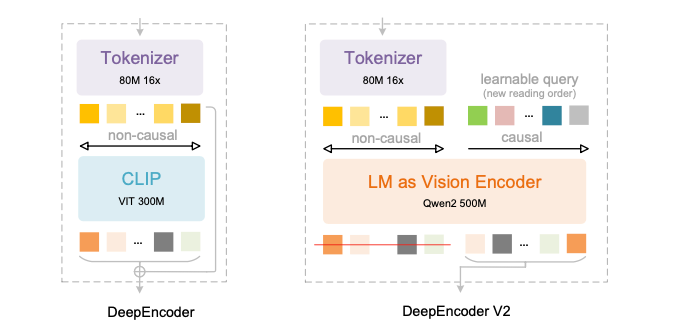
其中CLIP(CLIP讲解见之前我写的一篇文章)的部分,换成了 LLM(Qwen2 500M)。
题外话:
知乎上有个问题是:qwen3-0.6B这种小模型有什么实际意义和用途吗?,我想DeepSeek-OCR-2可以提供一个思路。不过,我好奇为啥它不用Qwen3-0.6B,而使用更早的Qwen2-0.5B
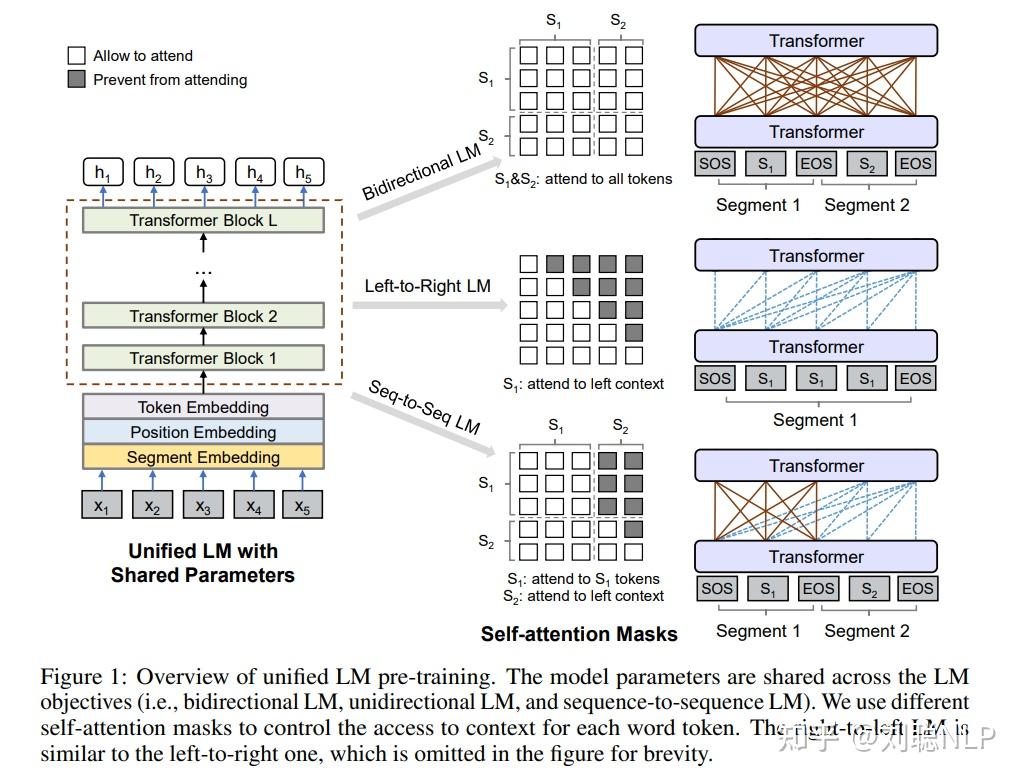
而其动机,是为了模仿人的逻辑,提升效率。传统视觉语言模型(VLMs)处理图像时,会以 「左上到右下」的刚性光栅扫描顺序处理视觉 token,忽略语义关联(如表格、公式的非线性布局);而 DeepSeek-OCR 2 的DeepEncoder V2 就是解决这个问题的。具体过程论文里也有提到,传统做法是把2D图像patch → 拉平成 1D → 固定 raster-scan 顺序(左上到右下) → 再喂给 LLM → 强行让 LLM 去学「真实阅读顺序」;而DeepSeek-OCR-2的做法是,在 encoder 里引入「因果查询 token(causal flow queries)」,让模型先在视觉侧学会「应该按什么顺序看」。
怎么衡量其效率呢?大家看它的论文,会注意到有个指标叫  。
。
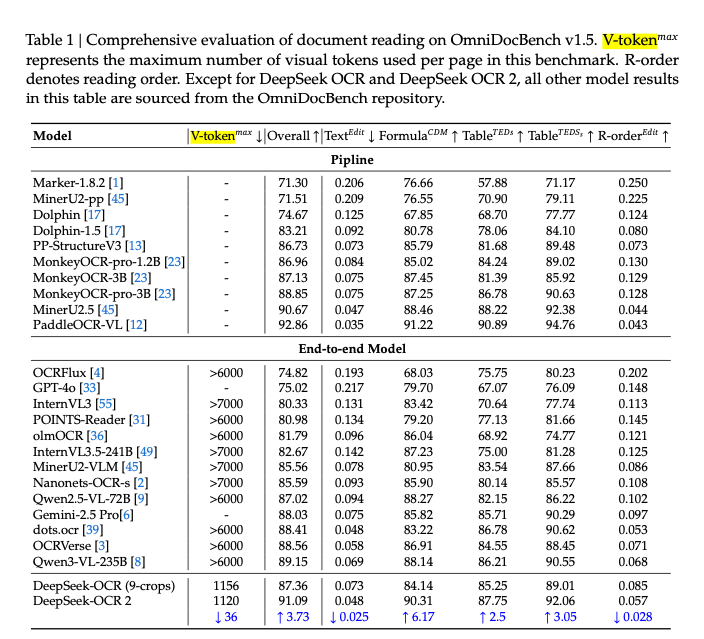
是「单页文档 / 图像在模型中使用的最大Visual Tokens数量」。你可以简单理解为数量越低,代表其效率越高(当然,质量是另一回事)。当然,这个数值,是可以人为设定的。
可以看到, 设定为1120的情况下,Overall分数上,DeepSeek-OCR 2达到了91.09分,比前代上升了3.73分,同时,还少用了36。而且,两代DeepSeek-OCR模型,都比市面上其他端到端的OCR模型效率更高,的数值低很多很多。虽然Overall分数落后于PaddleOCR-VL(注:这并非端到端的模型,而是pipeline),但考虑到其效率,确实非常高性价比了。
DeepSeek太秀了,更新了DeepSeek-OCR-2,
又是高立意的一篇文章,验证了了LLM架构有作为VLM编码器的潜力,有远大的理想。
我之前分享过DeepSeek-OCR相关内容,见
- DeepSeek又开源,这次是OCR模型!附论文解读!
- 再谈DeepSeek-OCR的信息压缩论!附DeepSeek-OCR与PaddleOCR实测对比!
- DeepSeek OCR的高OCR准确率,全是幻觉?
咱们今天来看看DeepSeek-OCR-V2怎么回事儿,
一些文章介绍什么双向+因果流视觉推理,可能理解起来会比较迷糊,我这里带着大家简单理解,并且通过代码来看其中的细节。
相较于DeepSeek-OCR V1的核心改动就是视觉编码模块。
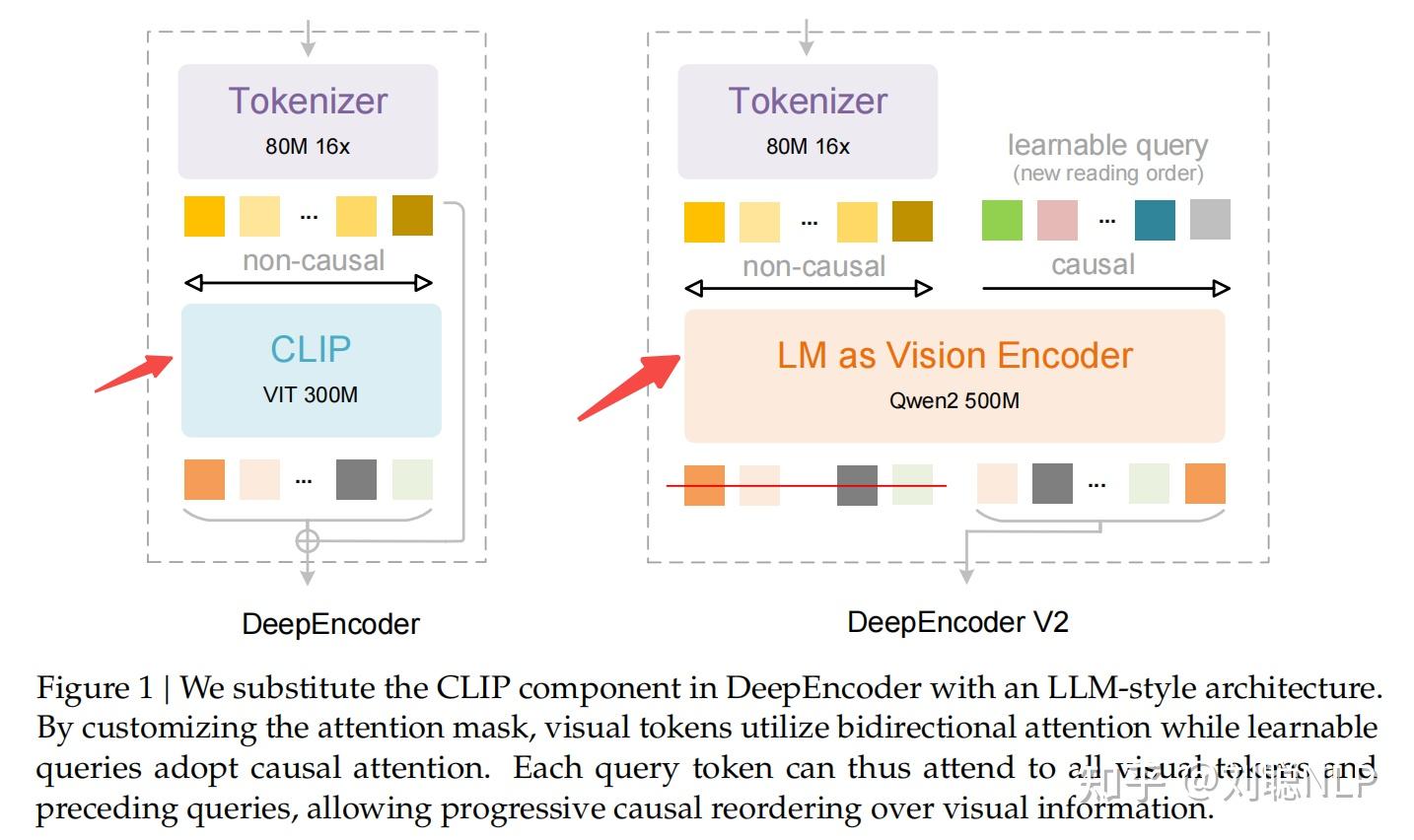
将原始的ViT改成了LM格式,你可以这么理解,ViT就是纯Encoder结构,会让每个视觉Token都彼此看见。
那么就存在了一个问题,就是视觉token其实是2维的,直接Patch会出现信息错乱,因此加入位置编码,
但是这样就相当于看图像,就是必须从左上一直看到右下,按照顺序来阅读,
而人在看图片的时候,会考虑每个模块的语义关联性,会有一定的阅读顺序,当然跟排版页有关。
比如双栏的,如果直接横行阅读,那么就会出现视觉和语义的Gap,或者是竖版文字识别等。
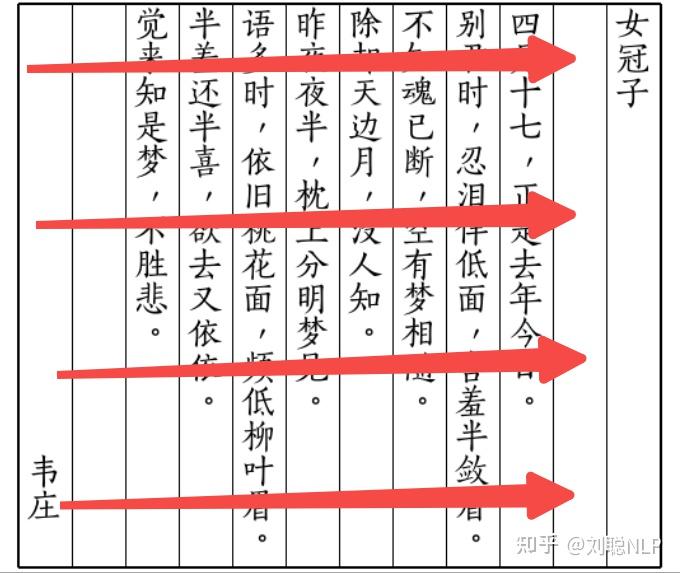
那么怎么做呢,直觉的做法,就是我对视觉Token进行排序就可以了嘛,
事实上DeepSeek-OCR-V2也是这么做的。
而对视觉Token排序,可以是encoder-decoder框架也可以是纯decoder框架,
encoder-decoder类似于mBART式交叉注意力结构,但是经过实验发现若采用,视觉 token 隔离在独立编码器内,难以收敛。
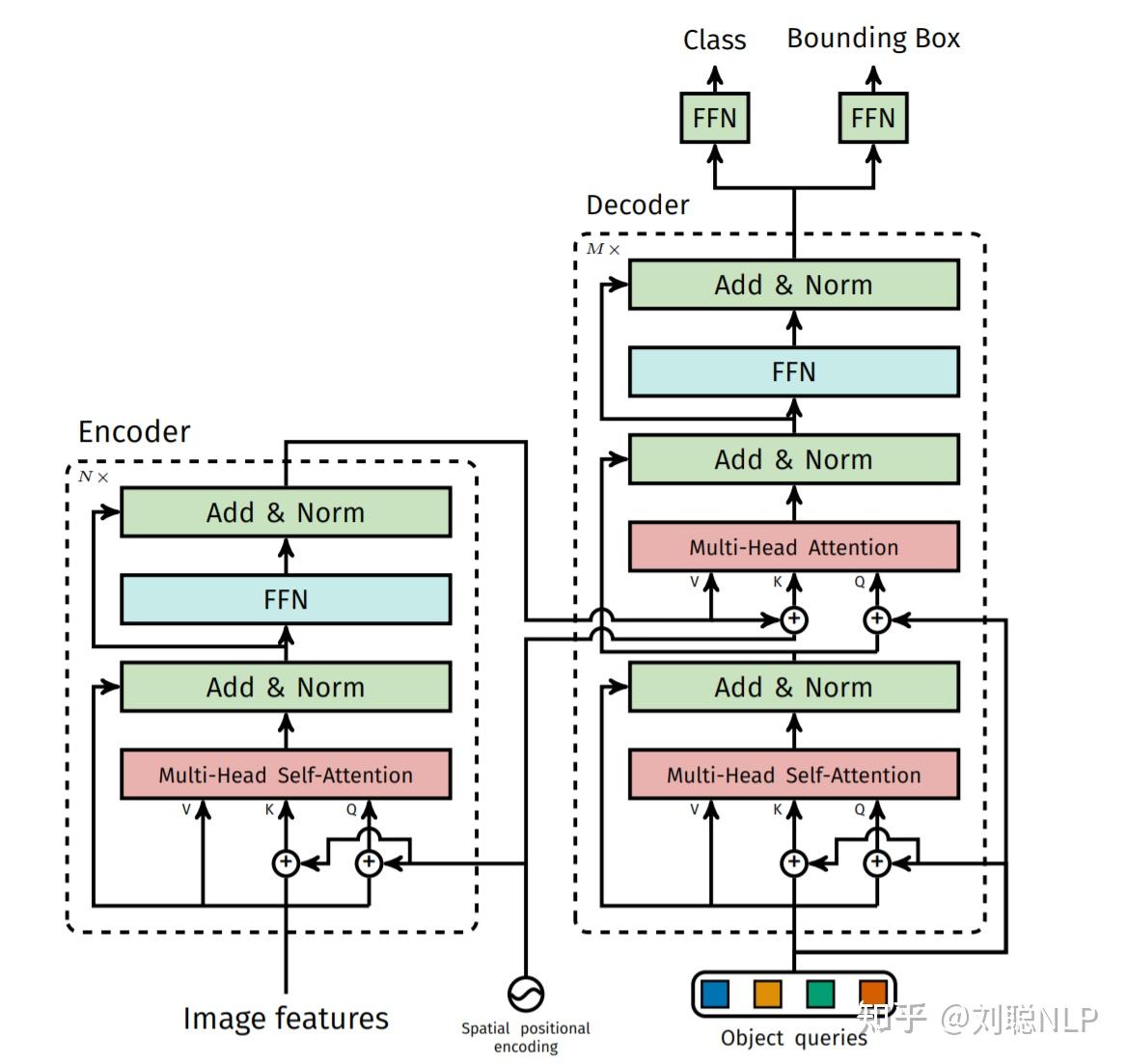
而纯decoder,让视觉token前面内容看不到后面内容,也是不合理的,
所以采用prefix LM结构,同时引入可学习query交互,有效压缩视觉信息。
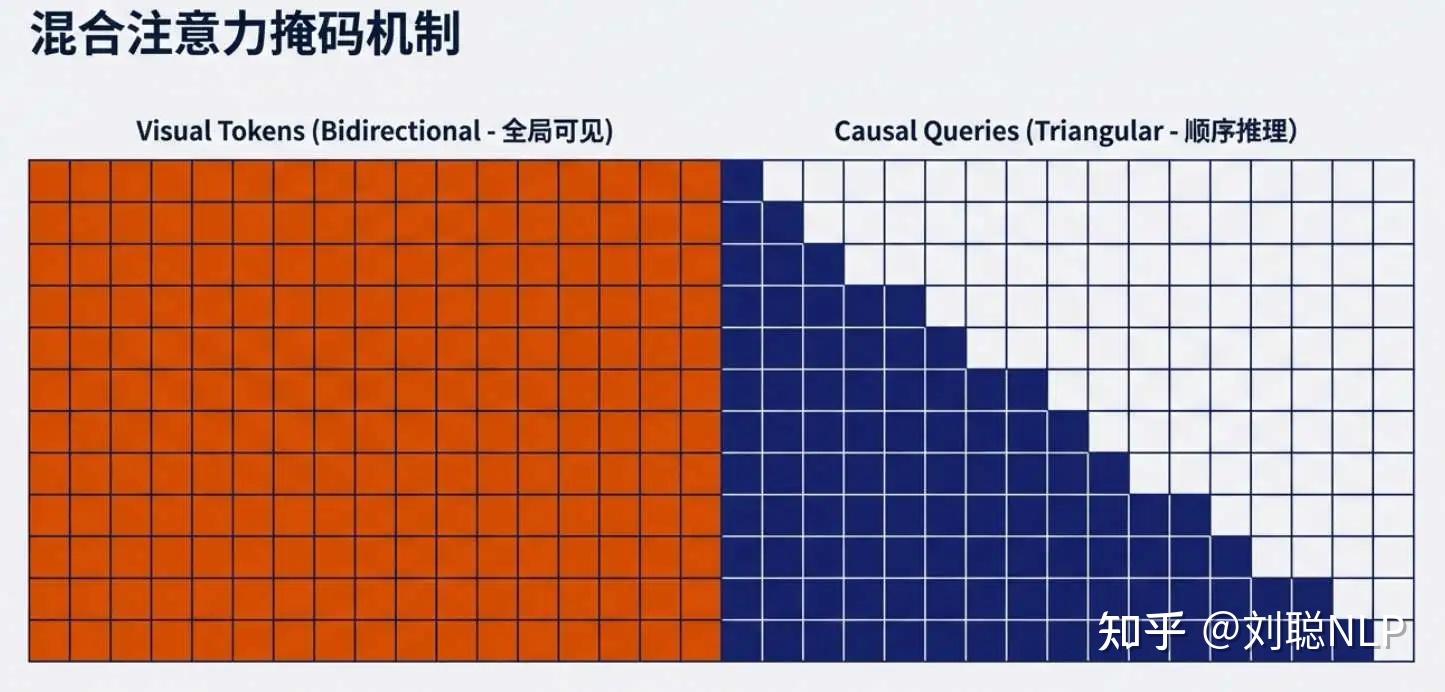
就是你们看到的双流(双向+因果)注意力架构,这不是是首创,不过确实是在编码器里首次使用。
如果你早期做过bert的话,一定知道unilm,
当然很早的ChatGLM1,也是这种prefix LM结构

就是通过mask,保证前面视觉token是彼此之间相互可以看见的,可学习query,是当前token只能看到前面内容,看不到后面内容的。
实现可以看代码,
def _create_custom_4d_mask(self, sequence_length, dtype, device, batch_size, token_type_ids, ):min_dtype = torch.finfo(dtype).min masks = [] for b in range(batch_size): mask = torch.full((sequence_length, sequence_length), fill_value=min_dtype, dtype=dtype, device=device) type_ids = token_type_ids[b] image_positions = (type_ids == 0).nonzero(as_tuple=True)[0] text_positions = (type_ids == 1).nonzero(as_tuple=True)[0] # non-casual if len(image_positions) > 0: mask[image_positions[:, None], image_positions] = 0.0 # causal for i, text_pos in enumerate(text_positions): if len(image_positions) > 0: mask[text_pos, image_positions] = 0.0 mask[text_pos, text_positions[:i + 1]] = 0.0 masks.append(mask) mask = torch.stack(masks, dim=0).unsqueeze(1) return mask DeepSeek-OCR-2的核心贡献是验证了LLM作为视觉编码器的可行性。
因为视觉编码利用LM、后面解码器用的也是LM,所以架构统一了,也为原生多模态打下基础。
整个训练流程分三步,
- Step1:仅训练DeepEncoder-V2部分,尾部加个MLP,预测token内容,训练Vision Tokenizer(DeepEncoder初始化)和LLM编码器(Qwen2-0.5B-base初始化)
- Step2:LLM编码器和DeepSeek-LLM解码器,用于增强可训练Query的表征能力
- Step3:仅训练DeepSeek-LLM解码器,专注理解DeepEncoder-V2重排序后的视觉Token序列
评测榜单依旧是OmniDocBench v1.5评测,
可以看到在纯端到端上DeepSeek-OCR-2相较于DeepSeek-OCR有很大提升,
但,PaddleOCR-VL依旧是神
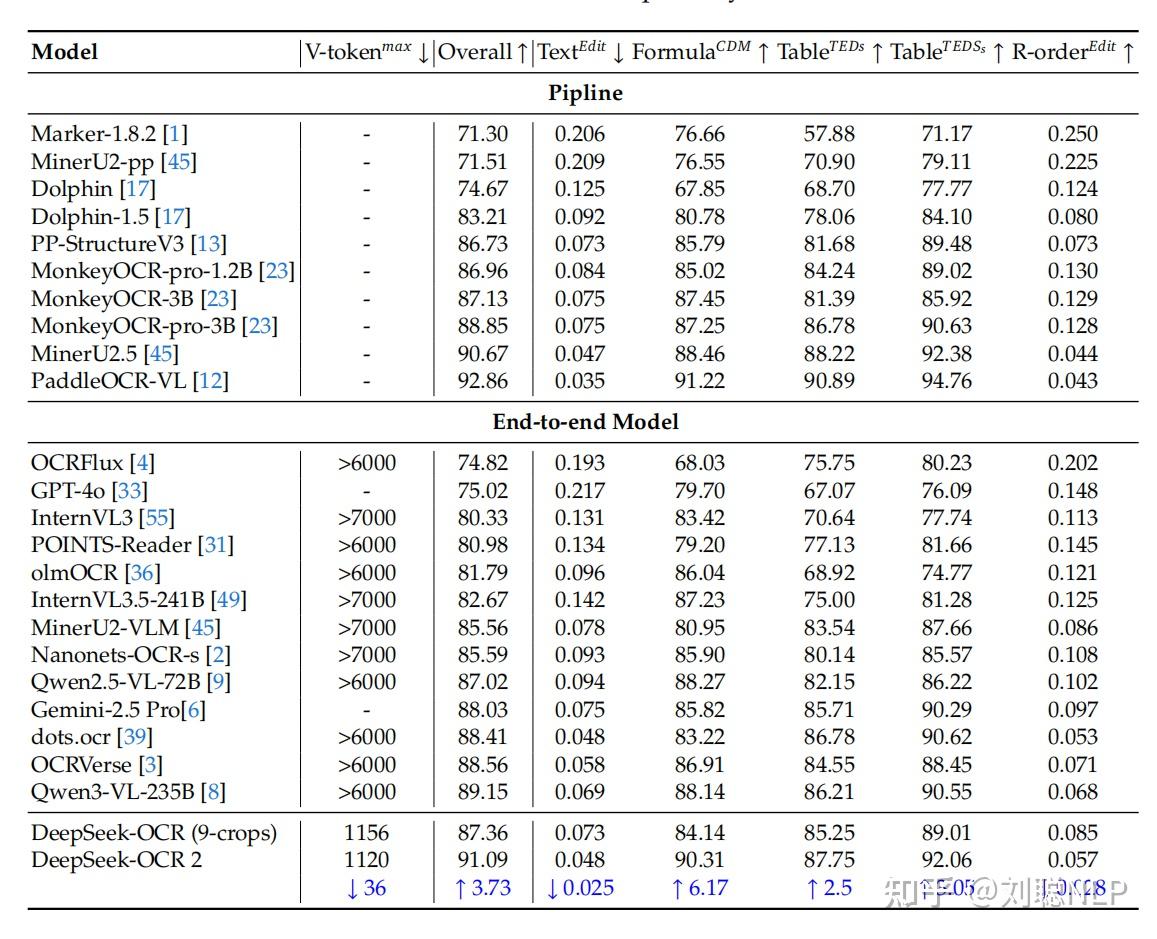
针对视觉模块排序的编辑距离,明显下降

对于DeepSeek自己来说,DeepSeek-OCR-V2主要是,
一个是在deeepseek-lm进行问答时,解决用户上传图片的问题,就是先转成文字,在给llm回答
第二个就是给deepseek造预训练数据,
都是在工程上自己使用的。
下面是真实评测,
- 机打内容的OCR识别准确很高
- 手写体简单的识别没有问题,过于连笔的会出错
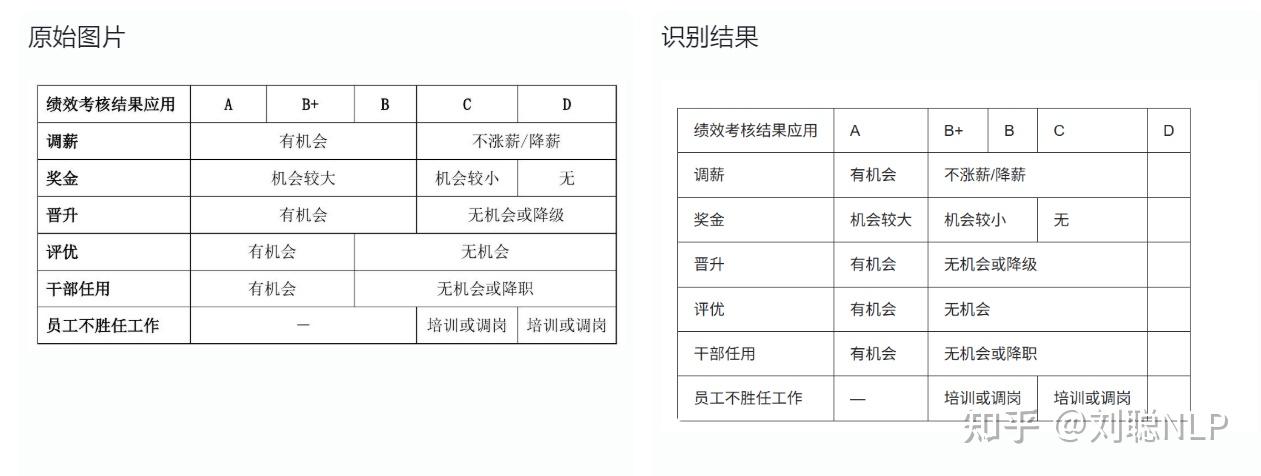
- 表格识别内容没问题,但是结构会出错
- 生僻字识别较第一版本有提高
- 竖版识别也有提高,这也是排序带来的好处
简单识别,正确。
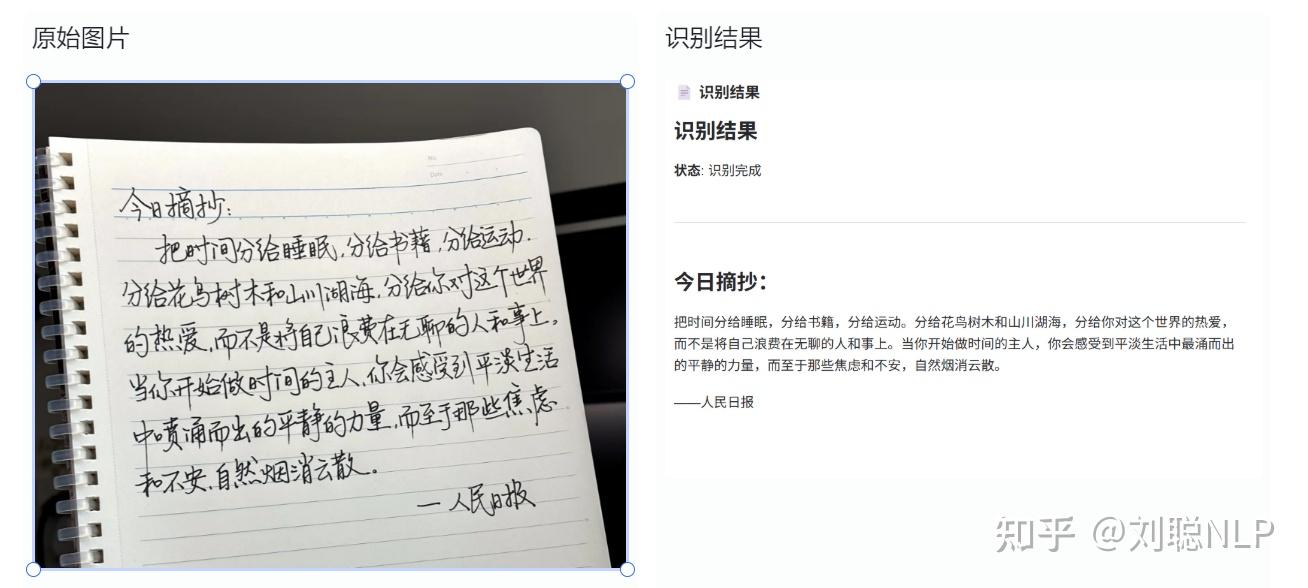
复杂手写体,会出错。

识别正确

表格的结构会识别错误,文字内容没问题
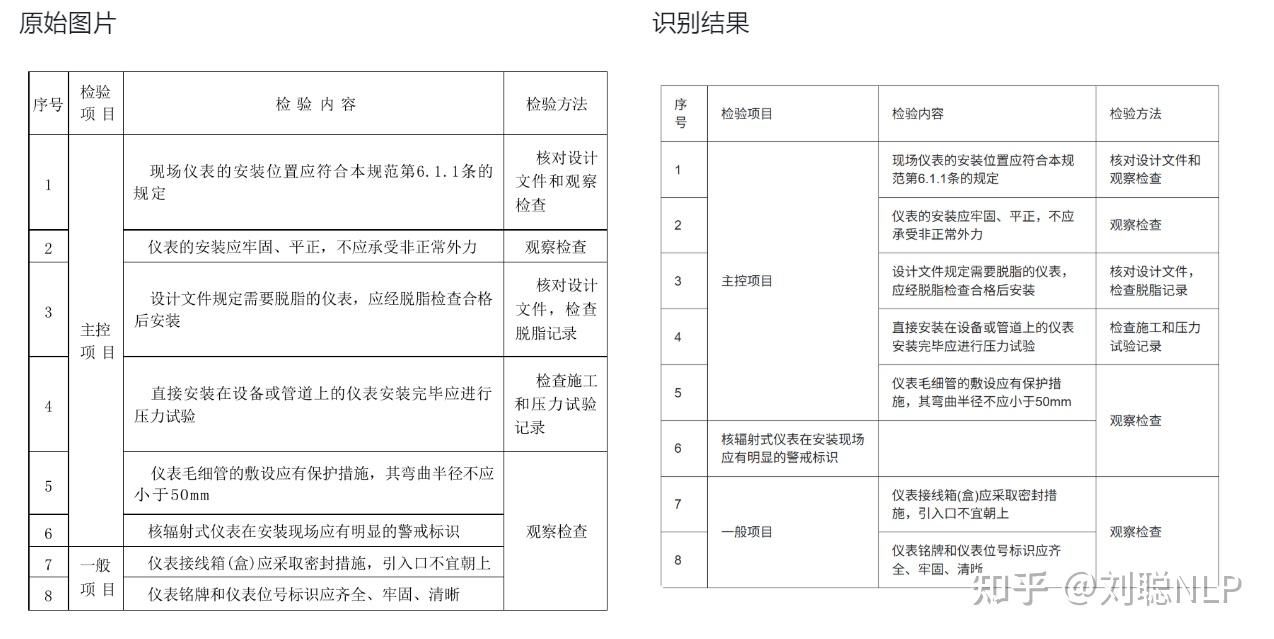
简单公式没问题,复杂公式会丢失信息,不知道是不是我图片太小,导致。

最后,
没等来DeepSeek-V4,先等来了DeepSeek-OCR-2,
将LLM作为视觉编码器,
验证了一种可能,
只能说,DeepSeek创新这一块,
没毛病~
在之前的文章中,我们介绍过 DeepSeek-OCR 这个工作(参考DeepSeek团队发布视觉压缩OCR模型,哪些信息和技术亮点值得关注?)。一个重要的启发是:它验证了图片是文本的高效压缩格式,用几百个 token 就能压进上千字的文本。
最近,官方又发布了第二版,我们主要看看进行了哪些改进。
从 DeepSeek-OCR V1 到 V2,最关键的叙事转变是从 物理压缩(Compression) 转向了 逻辑感知(Reasoning/Flow)。
而这个转变最主要的动机在于:V1 的编码器,沿用了传统的 ViT 那套架构,具体来说,是 SAM + Conv + CLIP 的组合,如下图中间虚线框起来的那部分:
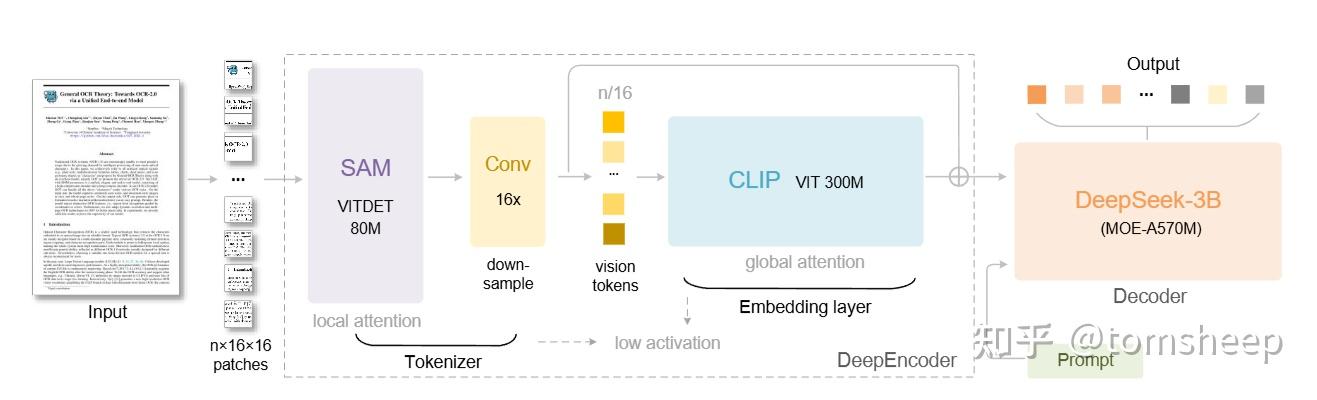
为了让照顾对 CV 领域不太熟悉的读者,我们稍微介绍一下这几个组件的功能:
- SAM:SAM 是 Meta 发布的高性能分割模型,在 DeepSeek-OCR 里,主要利用它的 Image Encoder 部分,扮演「感知者」的角色。因为它擅长处理高分辨率输入。
- 它使用一种叫 窗口注意力 的技术,就像你在看报纸,你不会一眼看完整个版面,而是把视线局限在一个个小方格(窗口)里,只关注局部的纹理、笔画和边缘。
- 它能极其清晰地捕捉到文字的形状、边界和布局细节,而且因为是只看局部,显存占用很低。
- Conv:用一个卷积层对特征进行压缩。
- SAM 虽然看清了细节,但吐出的特征点(Token)太多了。如果直接扔给大模型,计算量太大。
- 这一步就像是一个「打包压缩」的过程。它通过两层卷积网络,把 SAM 输出的特征图进行下采样。这不仅减少了数量,还把相邻的信息融合在了一起。
- CLIP:把视觉图像和文本语义对齐。
- 前面的 SAM 只知道较为原始的视觉特征,比如「这里有条黑线」、「那里是个圆圈」,但不懂那是字母
A。CLIP 的强大之处在于,它见过海量的图文对,它懂语义。 - 这一步使用的是全局注意力。因为经过中间的压缩,数据量已经很小了,CLIP 可以毫不费力地把这些特征通读一遍,理解它们之间的全局关系(比如标题和正文的关系),并把这些视觉信号翻译成 LLM(也就是后面的解码器)能听懂的语言。
这个架构看上去分工明确,很合理,它有什么问题呢?
主要在于,传统的做法,CLIP 这步输出通常是对应空间位置的特征序列(Patch Tokens),也就是说,当把这些特征喂给 LLM 时,通常是按照固定的空间顺序(光栅扫描) 拉直的,通俗地说就是从左上角一行一行死板地扫到右下角。但是,对于排版复杂一点的文档(比如表格、多栏文本),这种「从左上角到右下角」的物理顺序,往往打乱了原本的语义顺序。这让后面的 LLM 解码器理解起来非常费劲。
我们人类是怎么看这种复杂排版的文章的呢?举个例子,一篇双栏的学术论文,你会先看大标题,然后看左栏的第一段,读完左栏再跳到右栏。你的视线是跳跃的,但这种跳跃是符合语义逻辑的。
所以,V2 的作者提出:能不能让视觉编码器像人眼一样,不按死板的坐标顺序,而是按照内容的逻辑顺序来输出视觉特征?
他们把这种能力称为 视觉因果流(Visual Causal Flow)。
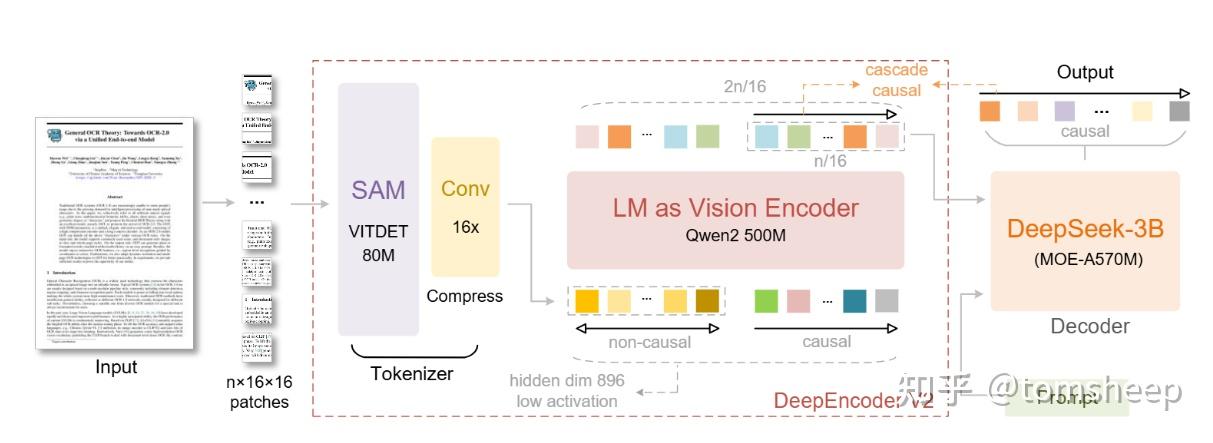
上面是 V2 的架构图,和 V1 相同的部分在于:
- 依然保留了
SAM + Conv做前端感知(也就是编码器的前半部分) - 解码器部分仍然是一个 LLM(DeepSeek-3B)
主要的变动在于编码器的后端部分,把之前的 CLIP 换成了一个小巧的 LLM(Qwen2-0.5B)。
也就是说,作者把这个编码器设计成了一个混合体,处理两种 Token:
- 视觉 Tokens: 代表图片原本的信息。
- 因果流查询 Tokens: 这是一组可学习的参数,它们负责「提取」并「排序」视觉信息。
为了让它们协同工作,作者设计了一个巧妙的 注意力掩码(Attention Mask)。这在 Transformer 的学习中非常重要,请看下面的矩阵定义:
我们可以把它拆解开:
- 左上角 (Visual to Visual): 所有的视觉 Tokens 之间可以互相看见(双向注意力)。就像看一张图时,你的余光能看到全局。
- 左下角 (Query to Visual): 所有的 Query Tokens 都能看见所有的 Visual Tokens。这保证了查询时能利用全图信息。
- 右下角 (Query to Query): 关键在这里,Query Tokens 之间是因果掩码,也就是第 个 Query 只能看见它之前的 Query,不能看见后面的。这和 LLM 生成文字的方式是一样的。
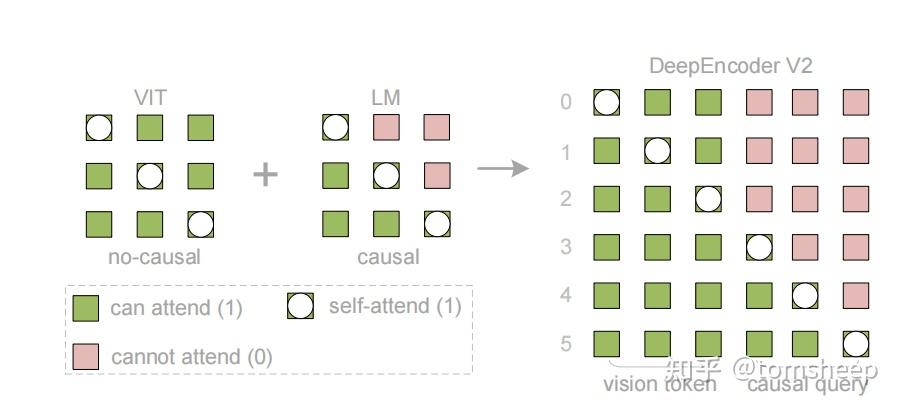
这个设计相当于引入了两个级联的因果推理机制:
- 第一级(Encoder 内部): 负责「排版推理」。它不生成文字,只负责把视觉信息按阅读逻辑排好队。每一个 Query 在生成时,不仅看着原图(Visual Tokens),还看着前面的 Query。这迫使模型学习「根据上文逻辑,下一眼该看图片的哪里」。
- 第二级(Decoder LLM): 负责「内容推理」。把排好队的特征翻译成文字。
这种设计让解码器 LLM(依然是那个 DeepSeek3B-MoE)的工作轻松了太多。这就像模型在输出视觉 token 之前,已经在内部做了一次 「隐式的思维链」,把乱序的空间像素,梳理成了有序的语义流。以前的模型是「空间坐标」决定顺序,DeepSeek-OCR 2 是「语义逻辑」决定顺序。
具体的训练中,作者用了三阶段训练法:
- 阶段一:预训练编码器:只训练 Encoder 部分(上面架构图中的红框 DeepEncoder V2 部分)。目的是让它学会怎么看图,怎么排序。
- 阶段二:查询增强:冻结最前端的 Vision Tokenizer(SAM+Conv),把 Encoder 后半部分(就是换成了 LLM 的那部分)和后面的 Decoder LLM 连起来一起训练。这是为了让 Encoder 的 Query 更好地适应 Decoder。
- 阶段三:LLM 继续训练:冻结整个 Encoder,只训练后面的 Decoder LLM。让 LLM 适应新的视觉特征,同时提高训练速度(因为 Encoder 不用算梯度了,跑得快)。
回到工程落地层面,V2 带来了哪些实实在在的好处?
- Token 预算更「抠门」了: V1 的 Gundam 模式用了 1156 个 token。V2 上限控制在 1120 个(为了对齐 Gemini-3 Pro 的视觉预算)。在 token 数减少的情况下,性能反升,说明「逻辑重排」比「堆分辨率」更管用。
- 读序错误大幅下降: OmniDocBench 上的 R-order 编辑距离从 0.085 降到 0.057。这意味着解析出来的 Markdown,段落错乱的情况会少很多。
- 解决了「复读机」问题: 生产环境的重复率(Repetition Rate)显著下降。V1 经常因为读序混乱,导致 LLM 在解码时迷失上下文,开始死循环复读。V2 提供了清晰的逻辑流,LLM 就不容易迷路了。
- 归纳偏置: 传统的「光栅扫描」是强加给模型的限制,不符合人类直觉。DeepSeek-OCR 2 试图打破这一点。
- LLM as Encoder: 作者用一个小的 LLM(Qwen2-0.5B)改造成了视觉编码器。这暗示了未来统一的全模态编码器的可能性——也许同一个架构既能编码图像,也能编码音频和文本。
- Token 效率: 在保证效果的前提下,Token 数量越少,推理成本越低。这篇文章证明了通过更好的「排序逻辑」,我们可以用更少的 Token 表达更丰富的信息。
总而言之,我还是之前的观点,DeepSeek-OCR 这个系列的工作,不在于提供一个好用的 OCR 工具(目前未必好用),DeepSeek 实际上是在探索 如何用 LLM 的架构去理解视觉。这一点未来仍然充满想象空间。
如果你觉得以上内容对你有所帮助,请不要吝惜你的点赞、分享与关注。任何互动都非常欢迎,也鼓励「批判性」转发~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/250449.html