
老王 2秒钟翻完了我的简历,推了推眼镜问:“看你精通 Claude Code,你这么厉害咋不手撸一个呢?”
我愣了一下,笑了:“就这?”
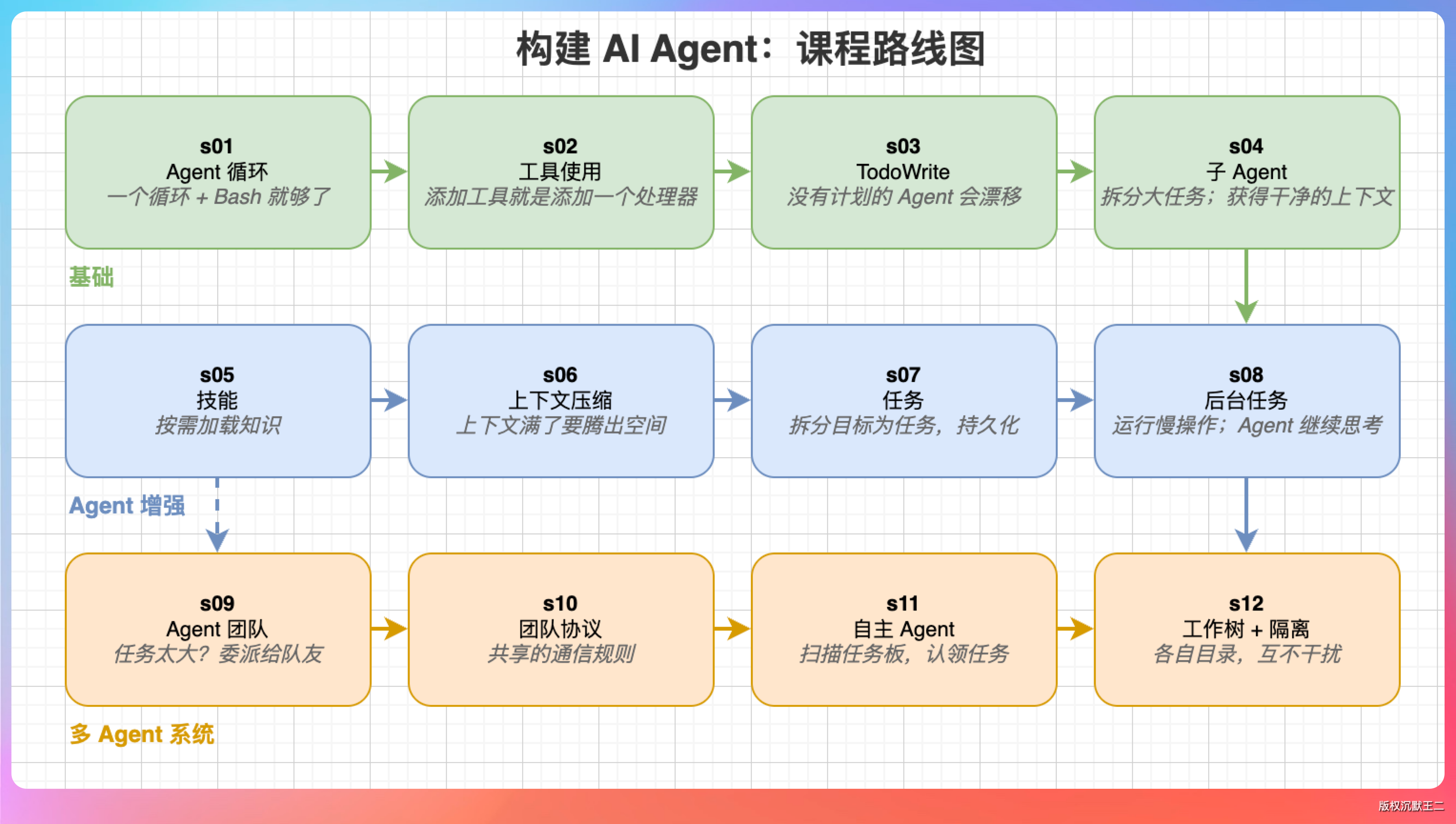
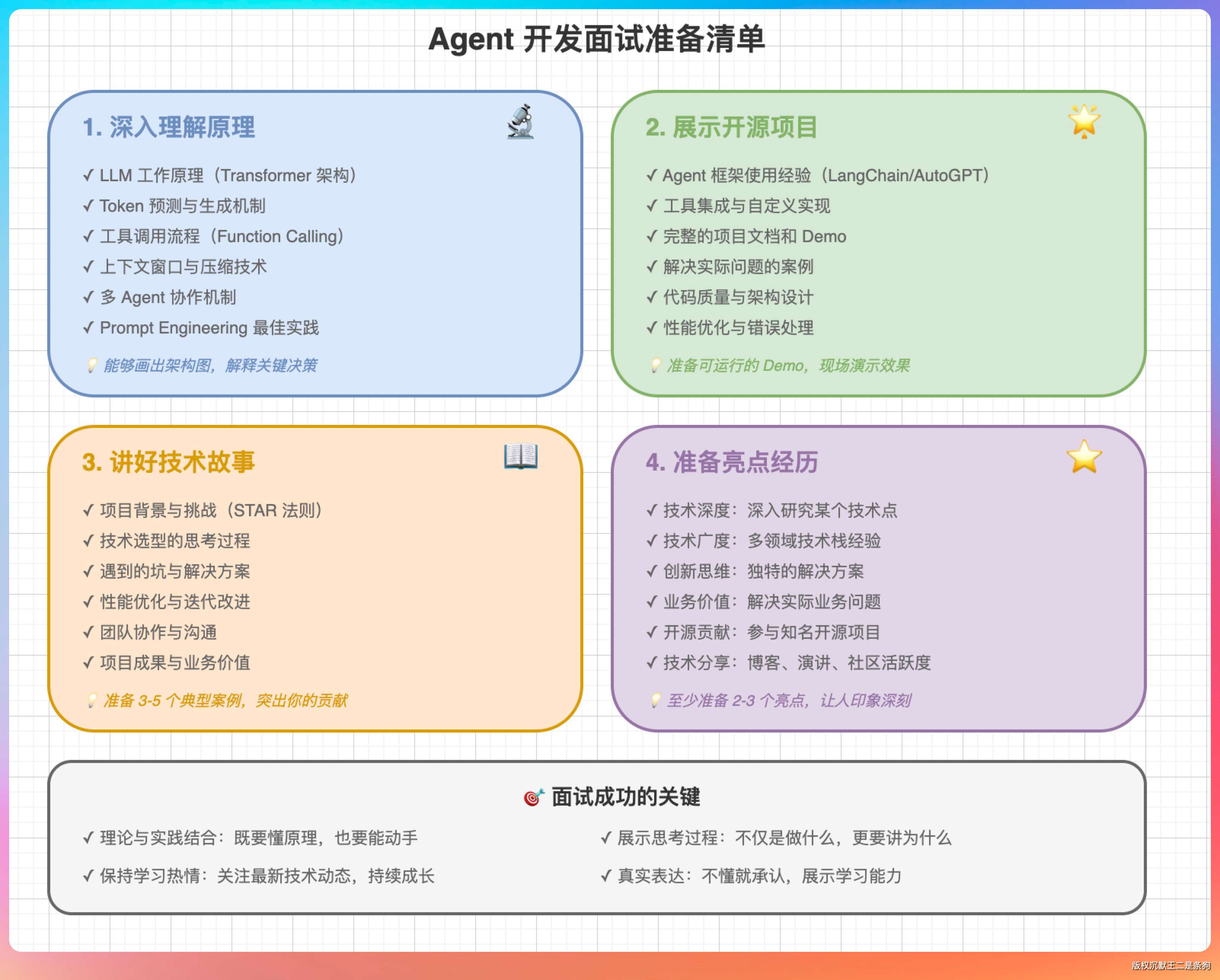
接下来的 40 分钟,我从最基础的 Agent 循环开始,一层一层给他拆解了 12 层架构。讲到最后,他说:“现在就办入职手续吧!”
今天我就把聊的内容整理出来,分享给正在面试或者想深入理解 Agent 原理的小伙伴。
先交代一下背景。我面的这个岗位是 AI 应用开发工程师,要求有 Agent 开发经验。我确实在简历上写了“精通 Claude Code,深入理解其底层原理”,我是真没想到老王让我手搓一个。
还好我之前深入研究过 learn-claude-code 这个开源项目,不然当场就尴尬了。
learn-claude-code 是什么呢?
它是一个开源教程,教我们如何从零实现一个类 Claude Code 的 Agent。项目的核心理念是:The model is the agent. The code is the harness.。
系好安全带,我们发车。
老王的第一个问题很直接:“你说说,Agent 和普通的聊天机器人有什么区别?”
普通聊天机器人是输入-输出,问啥答啥。Agent 是输入-思考-行动-观察-再思考,循环往复直到任务完成。
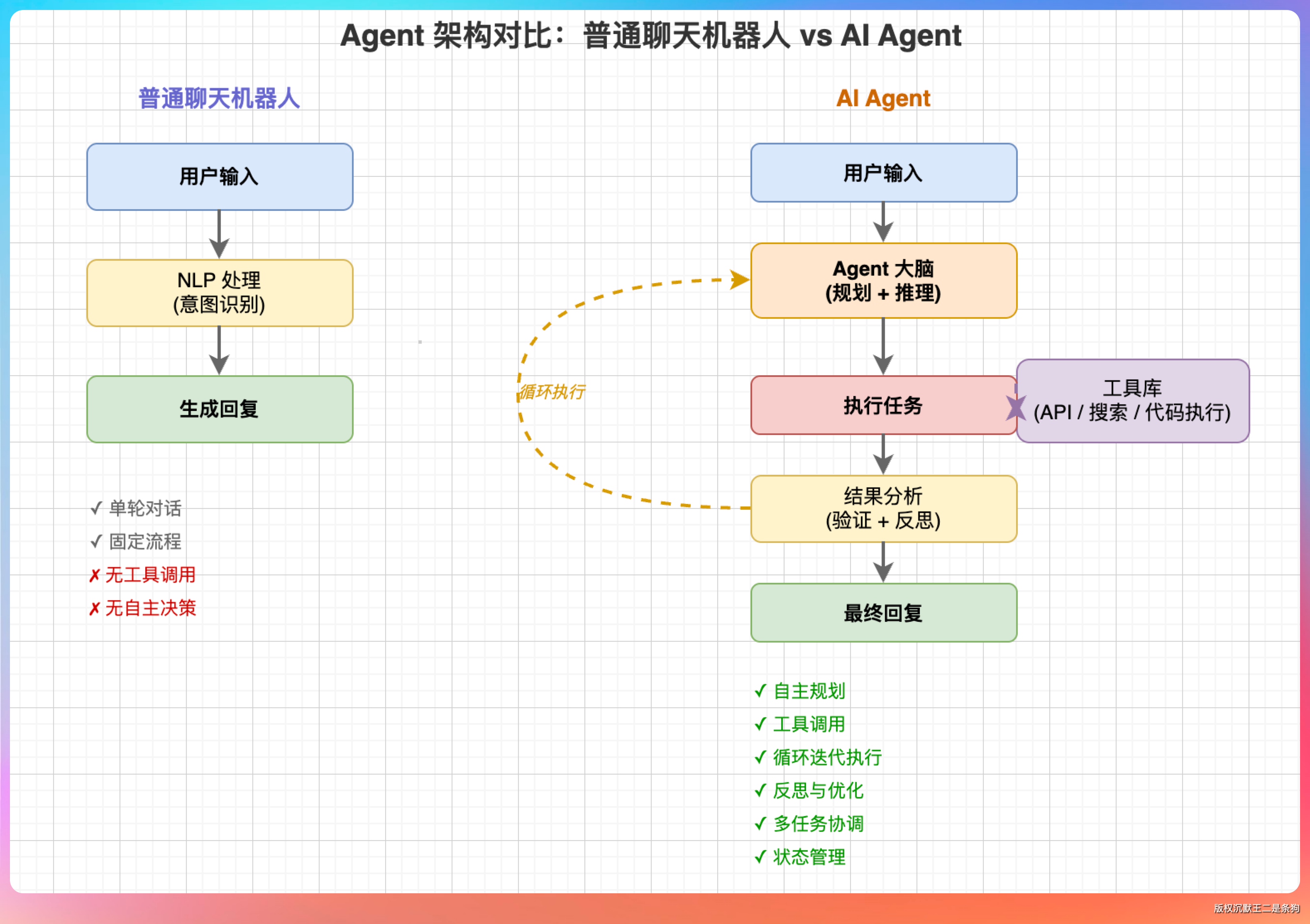
关键区别就在工具这两个字。
Agent 能调用工具。读文件、写代码、执行命令、查数据库,这些工具让 Agent 从“会说话”变成“能干活”。
举个例子。我们问聊天机器人“这个项目里有多少个 Java 文件”,它会告诉我们“不知道,你可以用 find 命令查一下”。问 Agent 同样的问题,它会直接执行 find 命令,然后告诉我们“找到了 23 个 Java 文件”。
这就是差别。Agent 不只是给建议,而是直接动手解决问题。
我还补充了一个观点:Agent 的价值不在于它能做多少事,而在于它能独立完成一件事。聊天机器人是“顾问”,只给建议不负责;Agent 是“执行者”,说到做到。这种从“建议”到“执行”的跨越,是 AI 应用从玩具走向工具的关键。
“这个区分很清晰。”老王点点头。
“这就是最基础的 Agent 循环,”我说,“看起来就是个 while 循环,但它定义了 Agent 的基本形态。”
client = anthropic.Anthropic() while True: user_input = input("You: ") response = client.messages.create( model="claude-sonnet-4-", max_tokens=1024, messages=[{"role": "user", "content": user_input}] ) print(f"Claude: {response.content[0].text}") 老王追问:“那这个循环和普通的聊天机器人有什么区别?”
“区别在于‘状态’。”我解释道,“普通聊天机器人是无状态的,每次请求都是独立的。Agent 是有状态的,它维护着一个上下文,这个上下文决定了它下一步要做什么。”
“比如用户说‘帮我改一下刚才那个文件’,Agent 需要知道‘刚才那个文件’是哪个。这个信息就保存在上下文中。”
老王若有所思:“所以 Agent 的本质是一个状态机?”
“可以这么理解,但比状态机更灵活。状态机的状态转移是预定义的,Agent 的状态转移是模型自己决定的。模型根据当前状态和输入,决定下一步做什么。”
“好,”老王继续问,“既然 Agent 的核心是工具,那工具是怎么被调起来的?”
模型本身并不知道怎么读文件、怎么执行命令。它只知道“有一个工具可以读文件,有一个工具可以执行命令”。具体怎么实现,是代码层的事情。
GPT plus 代充 只需 145tools = [ { "name": "read_file", "description": "读取指定路径的文件内容", "input_schema": { "type": "object", "properties": { "path": { "type": "string", "description": "要读取的文件路径" } }, "required": ["path"] } } ]
“关键点在这里,”我接着说,“模型根据 description 这个描述决定什么时候调用这个工具。描述写得好不好,直接决定模型能不能用对工具。”
老王打断我:“那如果模型调用了工具,结果怎么返回?”
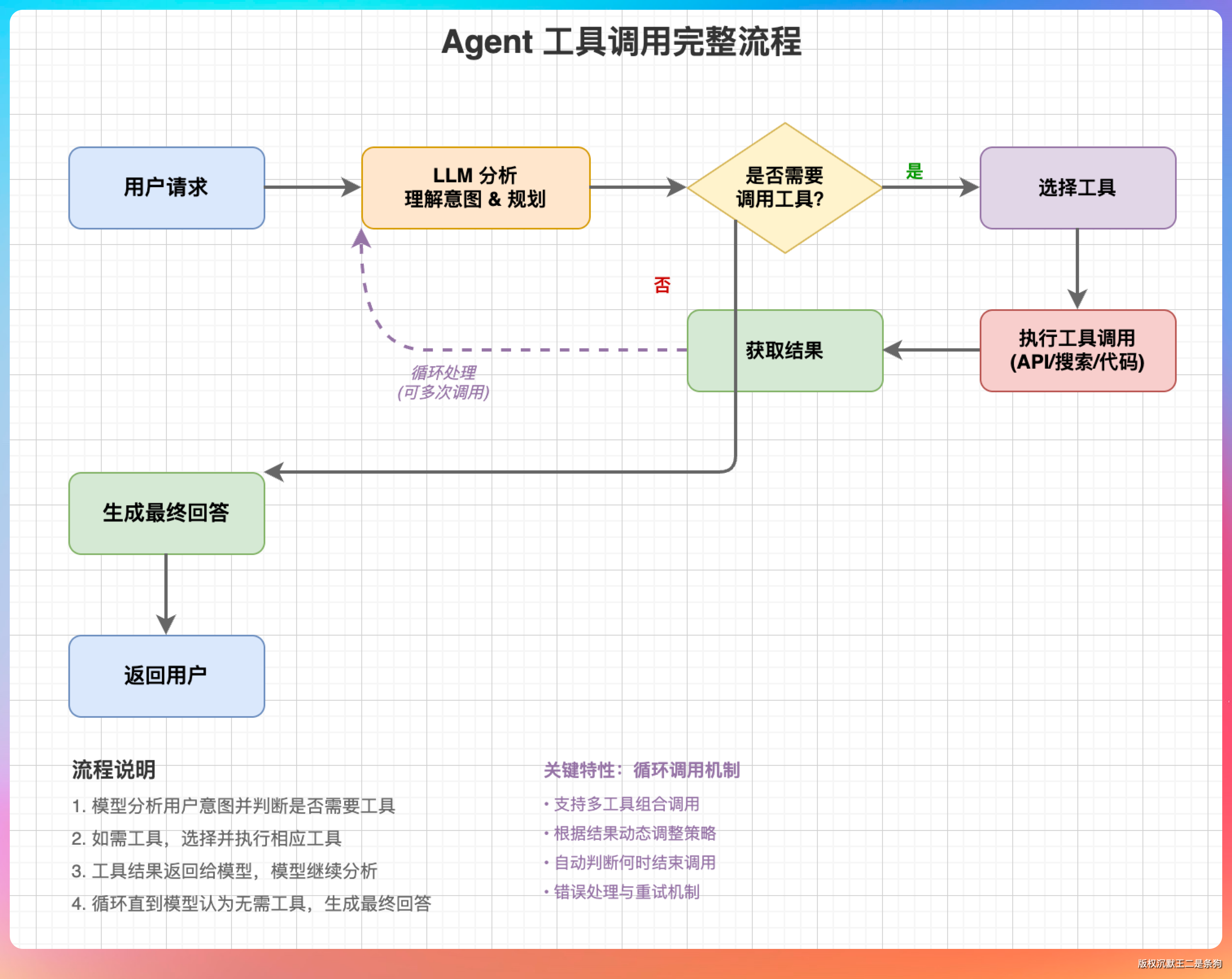
模型输出工具调用请求,系统解析并执行,然后把结果返回给模型。模型拿到结果后,决定是继续调用其他工具,还是直接给用户返回最终答案。
“工具调用失败怎么办?超时怎么办?返回结果格式不对怎么办?”老王打断我:“能具体说说吗?”
“好。工具调用失败分几种情况。第一种是工具执行出错,比如读文件时文件不存在。这种情况下,系统要把错误信息返回给模型,让模型决定怎么处理。可能是换个路径再试,也可能是告诉用户文件找不到。”
“第二种是工具超时。比如执行一个耗时很长的命令,这时候不能一直等着。Claude Code 的做法是设置超时时间,超时后把‘任务正在后台执行’的信息返回给模型,模型可以先处理其他事情,稍后再来检查结果。”
“第三种是返回结果格式不对。模型可能期望一个 JSON,但工具返回了纯文本。这时候系统要做格式转换,或者把原始结果包装成模型能理解的格式。”
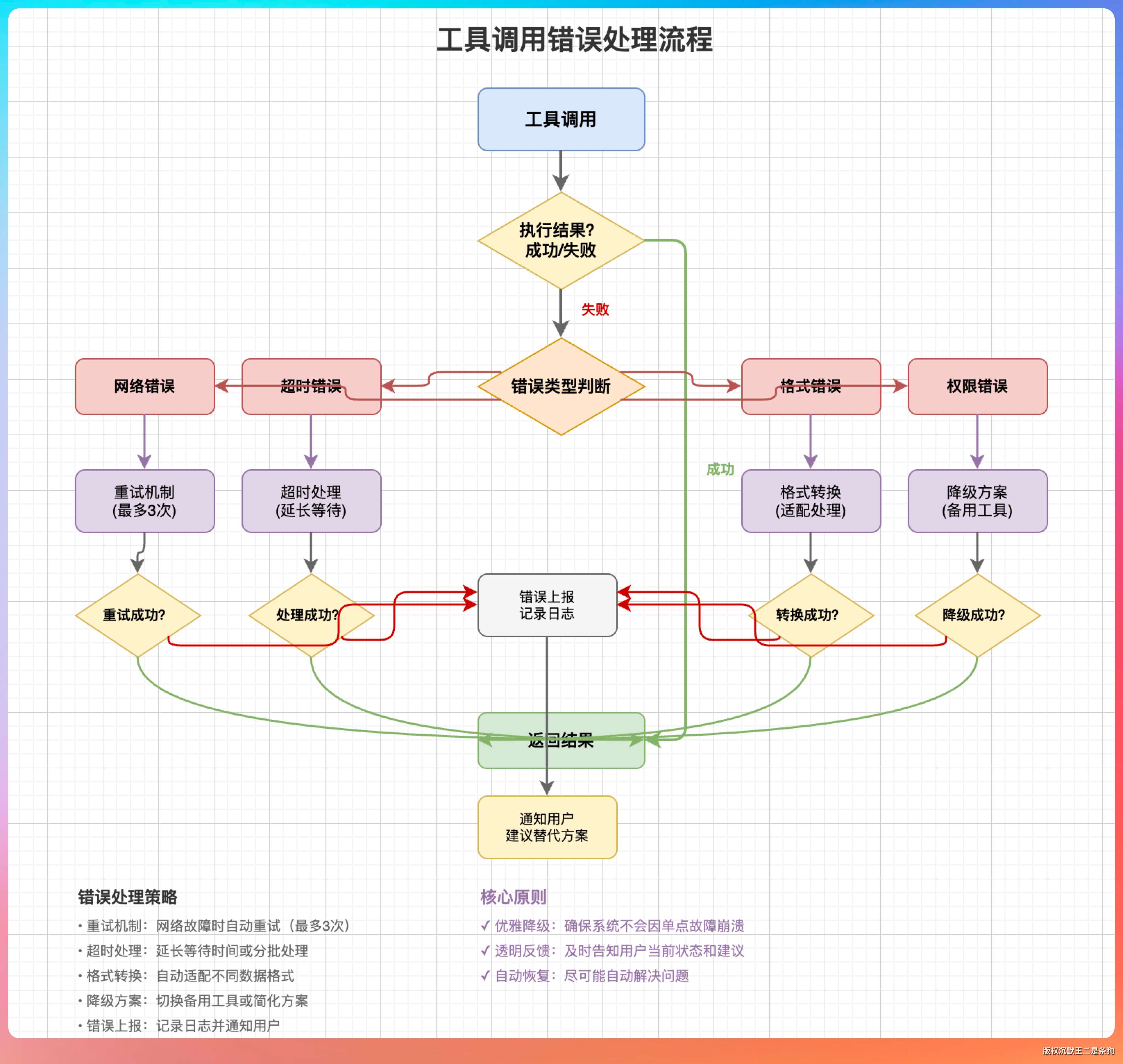
“这些边界情况的处理,往往是区分一个 Demo 和一个生产级 Agent 的关键。”我说。
老王追问:“那在工具设计上,有什么**实践吗?”
“有几点。”我说,“第一,工具描述要具体。不要写‘读取文件’,要写‘读取指定路径的文本文件内容,支持 UTF-8 编码’。描述越具体,模型越知道什么时候该用这个工具。”
“第二,参数设计要合理。参数不能太多,模型容易搞混;也不能太少,功能不够用。一般 3 到 5 个参数比较合适。每个参数都要有清晰的描述和类型定义。”
“第三,错误信息要友好。工具执行失败时,返回的错误信息要让模型能理解,这样它才能决定下一步怎么做。比如‘文件不存在’比‘Error: ENOENT’更有用。”
“第四,要有默认值和约束。比如文件路径参数,可以设置默认值为当前目录;字符串参数,可以设置长度限制。这样模型调用的时候不容易出错。”
“下一个问题,”老王说,“如果用户说‘帮我重构这个项目’,Agent 怎么处理?”
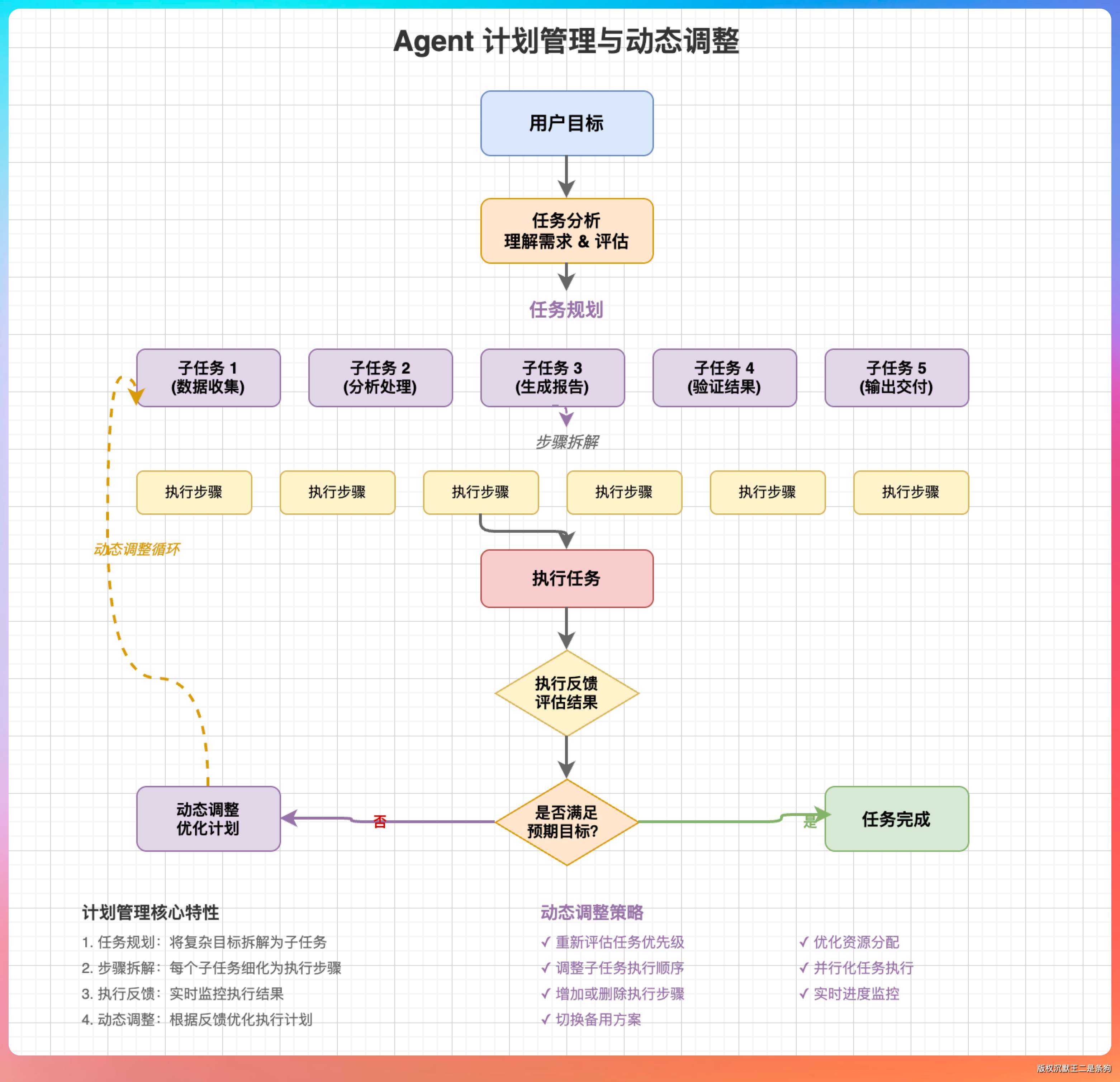
我说,模型不能收到任务就直接干,而是要先制定计划,把大任务拆成小步骤。
PLAN_SYSTEM_PROMPT = """ 你是一个任务规划助手。收到用户任务后,先制定执行计划,把大任务拆成小步骤。 输出格式: 1. 步骤一:xxx 2. 步骤二:xxx """ def create_plan(task): response = client.messages.create( model="claude-sonnet-4-", system=PLAN_SYSTEM_PROMPT, messages=[{"role": "user", "content": task}] ) return parse_plan(response.content[0].text) “比如重构项目,模型会先拆成:分析项目结构、识别需要重构的模块、制定重构方案、逐个执行重构。”
老王追问:“如果执行到一半发现计划有问题呢?”
“那就要动态调整计划。”我说,“Claude Code 的厉害之处在于,它不仅能制定计划,还能在执行过程中根据实际情况调整计划。这不是硬编码的逻辑,而是模型自己判断。”
老王追问:“计划管理和普通的任务队列有什么区别?”
“区别在于‘动态性’。”我说,“普通任务队列是静态的,任务一旦入队就不会变。计划管理是动态的,模型可以根据执行反馈随时调整计划。”
“比如执行到第三步的时候,模型发现前两步的结果和预期不一样,它可以选择跳过某些步骤,或者插入新的步骤,甚至完全重新制定计划。这种灵活性是硬编码的任务队列做不到的。”
“还有一个点,”我补充道,“计划管理不仅仅是拆解任务,还包括资源估算和风险评估。”
“比如重构一个项目,模型在制定计划的时候,应该估算每一步需要多长时间、需要哪些资源、可能遇到什么风险。这样用户才能判断这个计划是否可行,是否需要调整。”
“Claude Code 在这方面做得不错。它会在计划中标注哪些步骤是‘关键路径’,哪些步骤可以‘并行执行’,哪些步骤有‘依赖风险’。这种信息对决策很有帮助。” 
老王明显来了兴趣:“如果任务太复杂,一个 Agent 搞不定怎么办?”
“Sub Agent。”
GPT plus 代充 只需 145class SubAgent: def __init__(self, name, system_prompt): self.name = name self.system_prompt = system_prompt self.context = [] # 独立的上下文 def execute(self, task): response = client.messages.create( model="claude-sonnet-4-", system=self.system_prompt, messages=self.context + [{"role": "user", "content": task}] ) self.context.append({"role": "user", "content": task}) self.context.append({"role": "assistant", "content": response.content[0].text}) return response.content[0].text
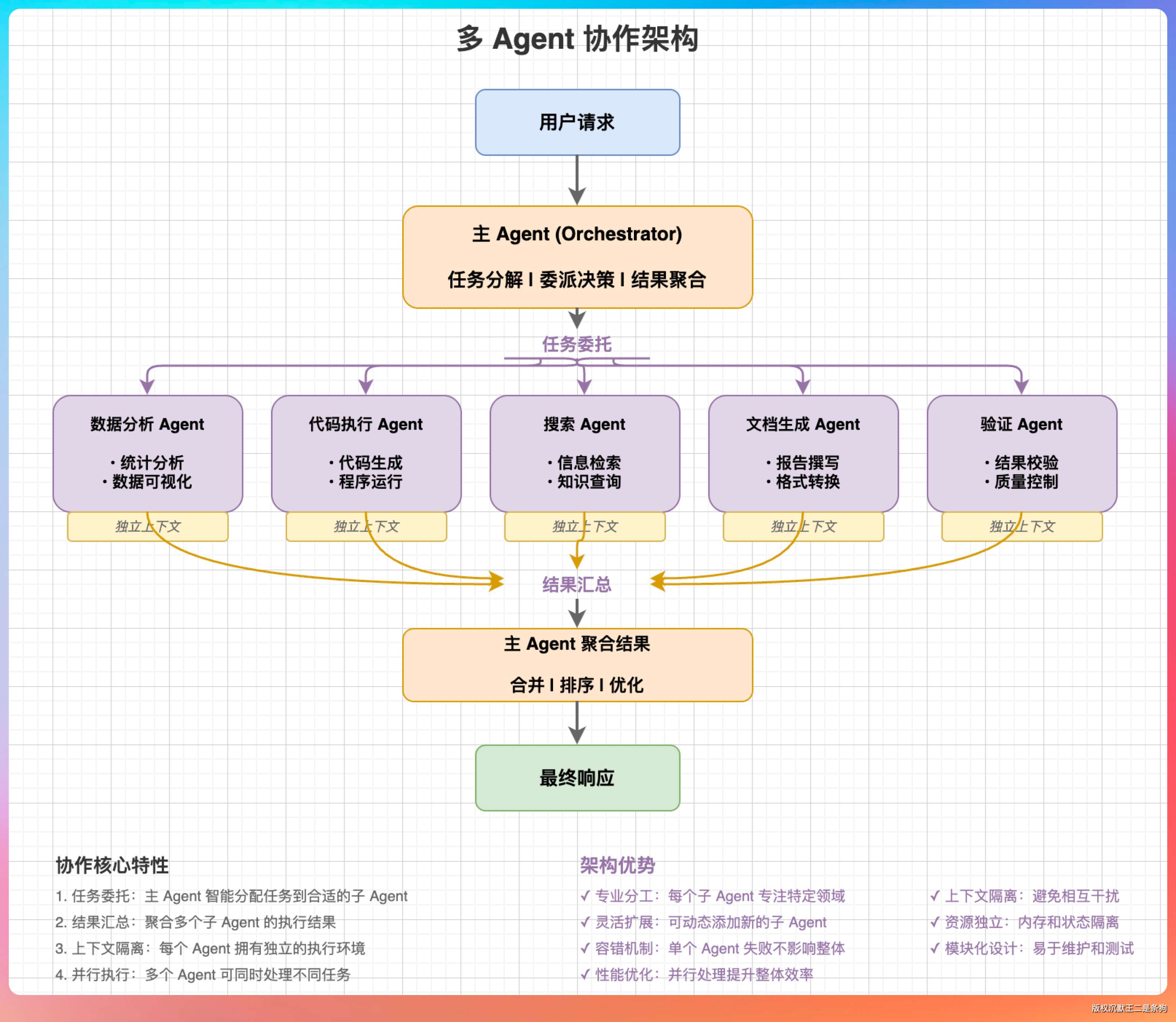
“子 Agent 有独立的上下文,执行完再把结果汇报给主 Agent。”
“举个例子,”我说,“主 Agent 负责整体架构设计,它可以创建三个子 Agent:一个专门分析代码质量,一个专门写测试用例,一个专门处理文档。三个子 Agent 并行工作,最后把结果汇总给主 Agent。”
老王眼睛亮了:“这有点像微服务的架构思想?”
“对!”我说,“Agent 的协作模式和微服务很像。每个 Agent 有单一职责,通过消息传递协作。但比微服务更灵活,因为 Agent 的‘拆分’和‘组合’是动态的,不是静态部署的。”
老王追问:“子 Agent 的上下文怎么管理?如果多个子 Agent 同时访问同一个资源,会不会有冲突?”
“好问题。”我说,“工作树隔离就是解决这个问题的。每个子 Agent 有独立的工作目录,互不干扰。就像 Docker 容器一样,每个 Agent 在自己的沙箱里运行。”
“具体实现上,主 Agent 在创建子 Agent 的时候,会为它分配一个临时工作目录。子 Agent 的所有文件操作都限制在这个目录内。执行完成后,主 Agent 可以选择保留结果,或者清理临时文件。”
“这样设计有几个好处:”我掰着手指头数,“第一,安全性,子 Agent 不会误删主 Agent 的文件;第二,并发性,多个子 Agent 可以并行执行,不用担心文件冲突;第三,可复现性,每次执行都是干净的环境,不会因为历史残留导致奇怪的问题。”
老王眼睛更亮了:“这个设计和 CI/CD 里的容器化思路很像。”
“对,工程上的很多问题,解决方案都是相通的。”
“我再补充一点,”我说,“子 Agent 不仅仅是任务分工,还可以实现‘专家系统’。”
“比如主 Agent 是‘全栈工程师’,它创建的子 Agent 可以是‘前端专家’、‘后端专家’、‘数据库专家’。每个专家有自己的知识库和**实践,处理特定领域的问题比通用 Agent 更高效。”
“这种模式在复杂项目中特别有用。一个人不可能精通所有技术栈,但一个团队可以。多 Agent 协作模拟的就是团队协作的模式。”
老王问:“那主 Agent 怎么知道该创建哪些子 Agent?”
“可以在系统提示词里预定义,也可以让主 Agent 自己判断。Claude Code 的做法是,主 Agent 在分析任务后,根据任务类型动态创建需要的子 Agent。任务完成后,子 Agent 会被销毁,资源得到释放。”
“我再补充一个细节,”我说,“子 Agent 的创建和销毁,其实也是一种‘资源管理’。如果子 Agent 执行完任务后不销毁,会占用大量内存和上下文空间。所以主 Agent 需要及时清理不再需要的子 Agent。”
“Claude Code 的做法是,子 Agent 执行完任务后,把结果返回给主 Agent,然后自动进入‘休眠’状态。如果一段时间内没有新任务,就彻底销毁。这种‘懒销毁’策略,既保证了响应速度,又避免了资源浪费。”
“工具多了,”老王问,“每次请求都把全部工具塞给模型吗?”
“当然不是,按需加载。”
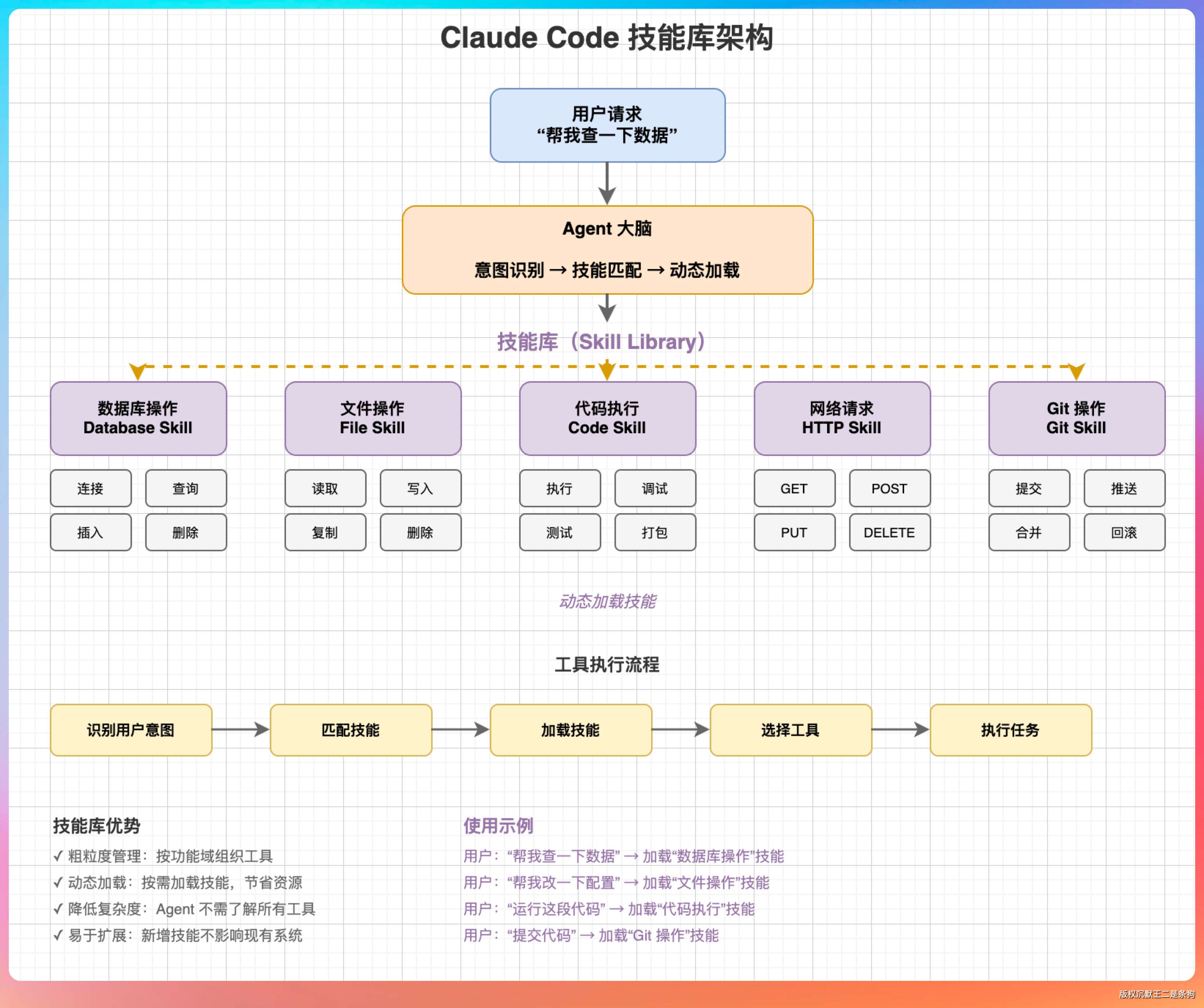
我说,不是把所有工具都塞给模型,而是根据任务类型,动态加载相关的技能定义。
“比如用户说‘帮我查一下数据库’,Agent 就加载数据库相关的工具;用户说‘帮我改前端代码’,Agent 就加载前端相关的工具。”
“这样做有两个好处:”我竖起两根手指,“第一,减少 token 消耗,模型不需要看一堆用不到的工具定义;第二,提高调用准确率,工具越少,模型选对的概率越高。”
老王追问:“怎么判断哪些工具需要加载?”
“有几种策略。最简单的是关键词匹配,用户输入里提到‘数据库’就加载数据库工具。更智能的做法是让模型自己判断,先给模型一个工具目录,让它选择需要加载哪些。”
“Claude Code 的做法更高级,它维护了一个技能库,每个技能是一组相关工具的集合。比如‘数据库操作’技能包含连接、查询、插入、删除等工具,‘文件操作’技能包含读、写、复制、删除等工具。”
“用户说‘帮我查一下数据’,Agent 加载‘数据库操作’技能;用户说‘帮我改一下配置’,Agent 加载‘文件操作’技能。这样粒度更粗,管理起来更方便。”
老王点点头:“这个设计很合理。实际工作中,我们的工具库可能有几十个甚至上百个,全塞进去确实不现实。”
“而且,”我补充道,“技能加载还可以和热更新结合。比如用户突然说‘帮我连一下 Redis’,Agent 可以动态加载 Redis 相关的技能,而不需要重启。”
“这种动态加载的能力,让 Agent 具备了‘学习新技能’的能力。就像人类一样,遇到不会的事情,先学再做。”
老王问:“技能之间会不会有冲突?”
“有可能。比如‘文件操作’技能和‘数据库操作’技能可能都有‘读取’相关的工具。这时候需要命名空间来区分,比如 file.read 和 db.read。”
“另外,技能加载的顺序也很重要。有些技能可能依赖其他技能,需要先加载依赖项。Claude Code 的做法是,每个技能声明自己的依赖关系,系统按拓扑排序加载。”
“还有一个问题,”老王说,“对话历史太长,token 不够用了怎么办?”
“上下文压缩。”
我说,当对话历史太长时,不是简单截断,而是提取关键信息,保留重要的上下文。
“具体怎么做?”他问。
“有几种策略。最简单的,保留最近的 N 轮对话,丢弃更早的。但这样会丢失重要信息。更好的做法是,让模型自己总结历史对话的关键点,然后用总结替代原始对话。”
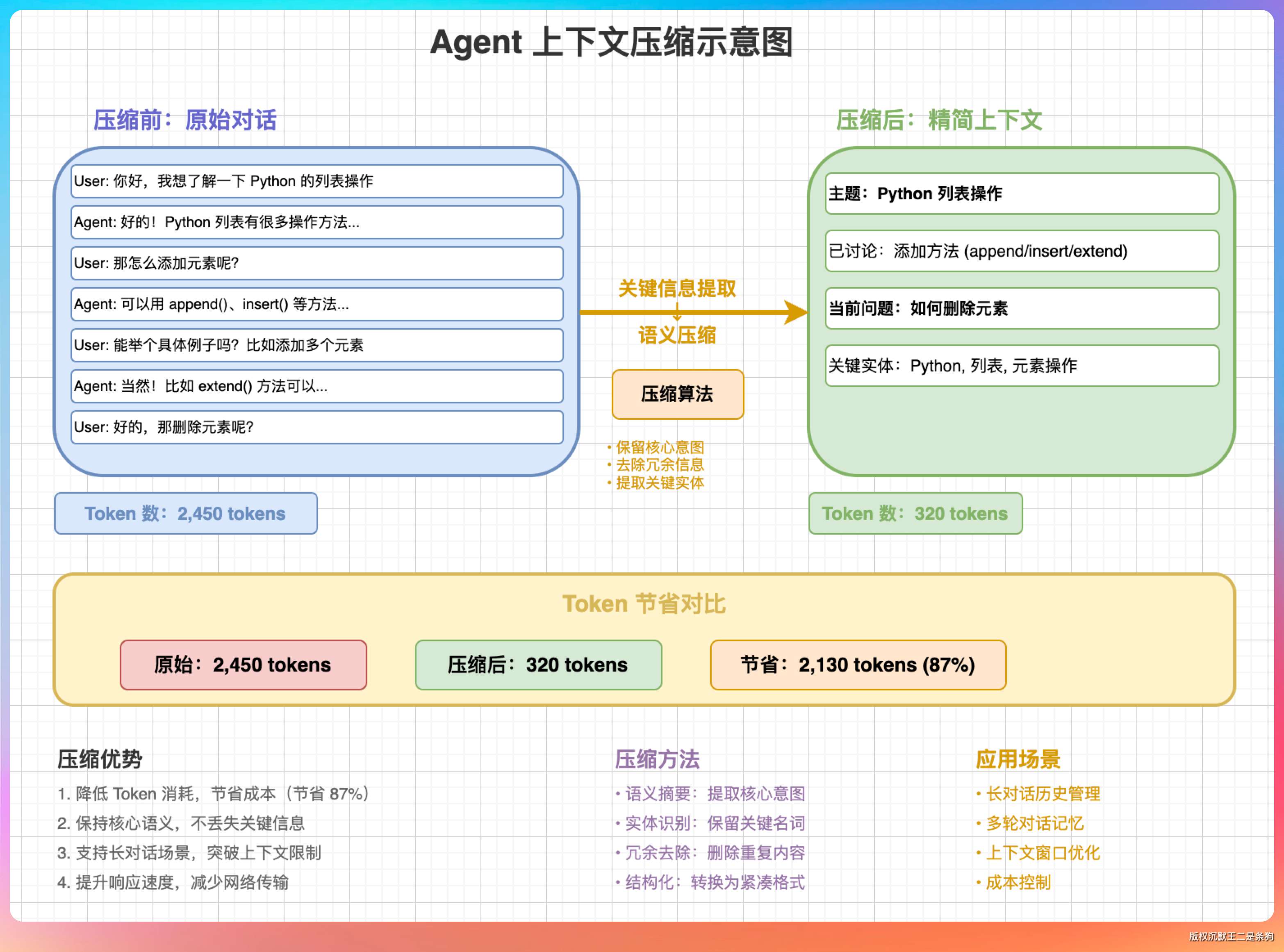
“Claude Code 的做法更智能。它会识别哪些信息是‘事实性’的,比如文件路径、代码片段、配置参数,这些必须保留;哪些是‘过程性’的,比如试错过程、中间推导,这些可以压缩。”
老王若有所思:“这有点像人类的记忆机制,重要的记住,不重要的遗忘。”
“对,Agent 的设计很多时候就是在模拟人类的认知机制。”
老王追问:“压缩会不会丢失重要信息?”
“有可能,所以压缩策略要设计得很小心。”我说,“一种做法是分级压缩。最近的几轮对话保持完整,稍早的对话做轻度压缩(保留关键信息),更早的对话做重度压缩(只保留结论)。”
“还有一种做法是让用户介入。当 Agent 觉得需要压缩时,先征求用户同意,或者把压缩后的摘要展示给用户,让用户确认是否保留。”
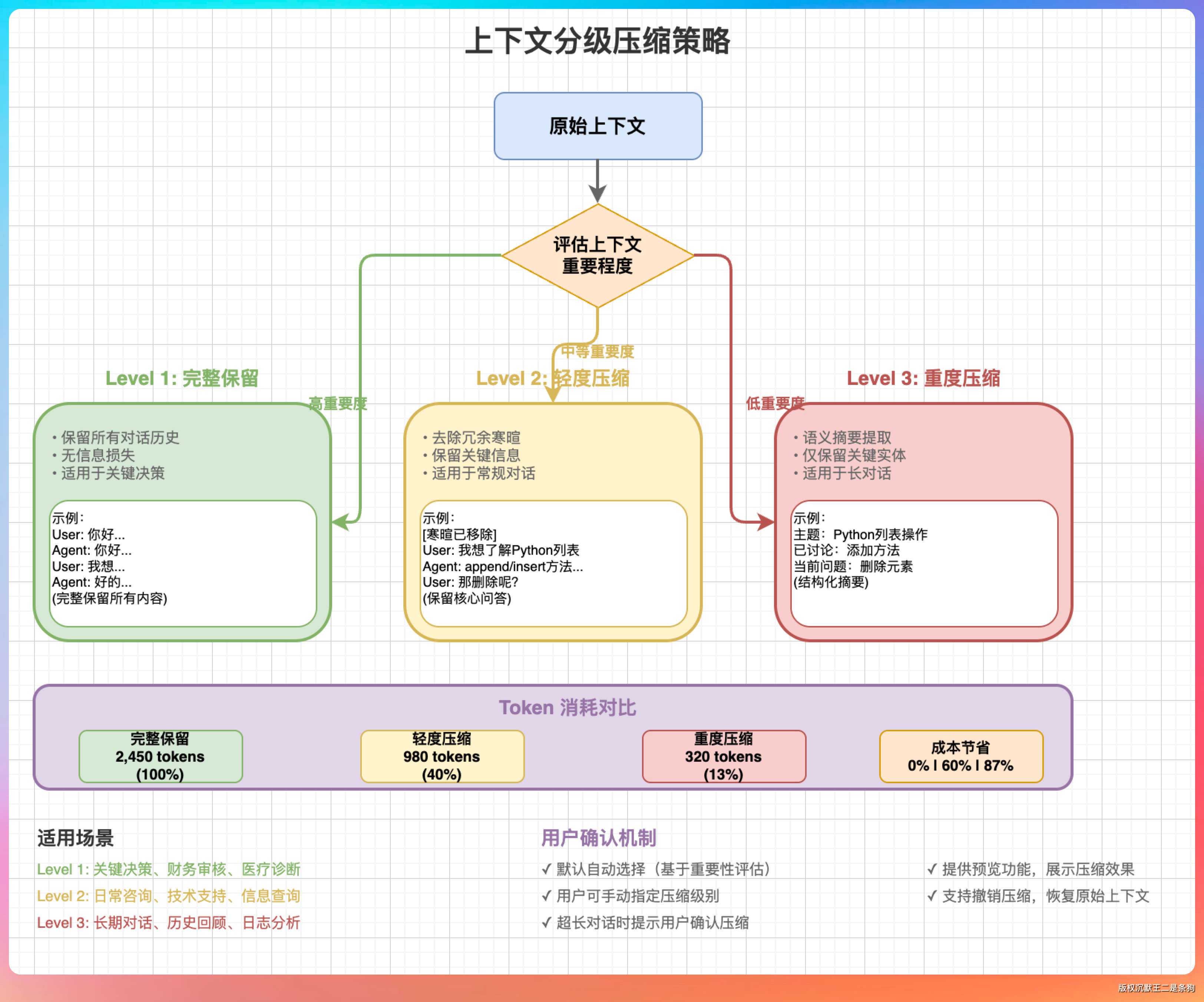
“压缩的目的是在有限的上下文窗口里,保留最有价值的信息。这不是简单的截断,而是一个信息提炼的过程。”
“我再补充一个高级技巧,”我说,“上下文压缩还可以和‘记忆’结合。”
“有些信息虽然当前对话用不到,但以后可能有用。比如用户说‘我喜欢用空格缩进’,这个信息可以保存到长期记忆里,下次再处理代码的时候自动应用。”
“Claude Code 虽然没有显式的长期记忆,但通过上下文压缩,它实际上实现了一种‘短期记忆’。压缩后的摘要就是记忆的精华部分。”
老王问:“长期记忆和短期记忆怎么区分?”
“短期记忆是会话级别的,对话结束就清空;长期记忆是用户级别的,跨会话保留。比如用户的编码习惯、项目结构、常用命令,这些可以保存到长期记忆里。”
“实现长期记忆需要外部存储,比如数据库或文件。每次会话开始时,把相关的长期记忆加载到上下文中;会话过程中,把新学到的信息更新到长期记忆里。”
“如果多个任务之间没有依赖,”老王问,“能不能并行执行?”
“把任务组织成有向无环图(DAG),支持并行执行。”
读取配置 -> 分析代码 -> 生成报告 | | v v 加载依赖 检查规范 “读取配置和加载依赖可以并行,分析代码和检查规范可以并行,但生成报告必须等前面都完成。”
“这样做的好处是效率。”我说,“不是所有任务都要串行,有些可以同时跑。特别是在处理大型项目时,并行执行能节省大量时间。”
老王问:“实际实现中,怎么判断任务之间的依赖关系?”
“可以让模型自己分析。”我说,“给模型一个任务列表,让它输出依赖关系图。或者更简单的,由用户显式指定。Claude Code 的做法是,模型在制定计划的时候就同时输出依赖关系。”
老王追问:“如果并行执行的任务之间有冲突怎么办?”
“这就是后台任务和工作树隔离要解决的问题。”我说,“每个任务有独立的工作目录,互不干扰。即使两个任务同时写文件,也是写在不同的目录里,不会冲突。”
“等所有并行任务都完成后,主 Agent 再决定怎么合并结果。可能是简单的汇总,也可能是需要进一步处理。”
“还有一种情况是,任务之间虽然没有直接依赖,但需要共享某些资源。这时候需要加锁机制,或者用消息队列来协调。”
讲到这儿,我停下来喝了口水。
老王说:“我想问你一个更高层的问题:Agent 开发的本质是什么?”
“好问题。”我说,“Harness Engineering。”
“什么意思?”
“以前我们做 AI 应用,思路是:我要设计一个工作流,A 节点连 B 节点,B 节点连 C 节点,然后让模型在每个节点上干活。”
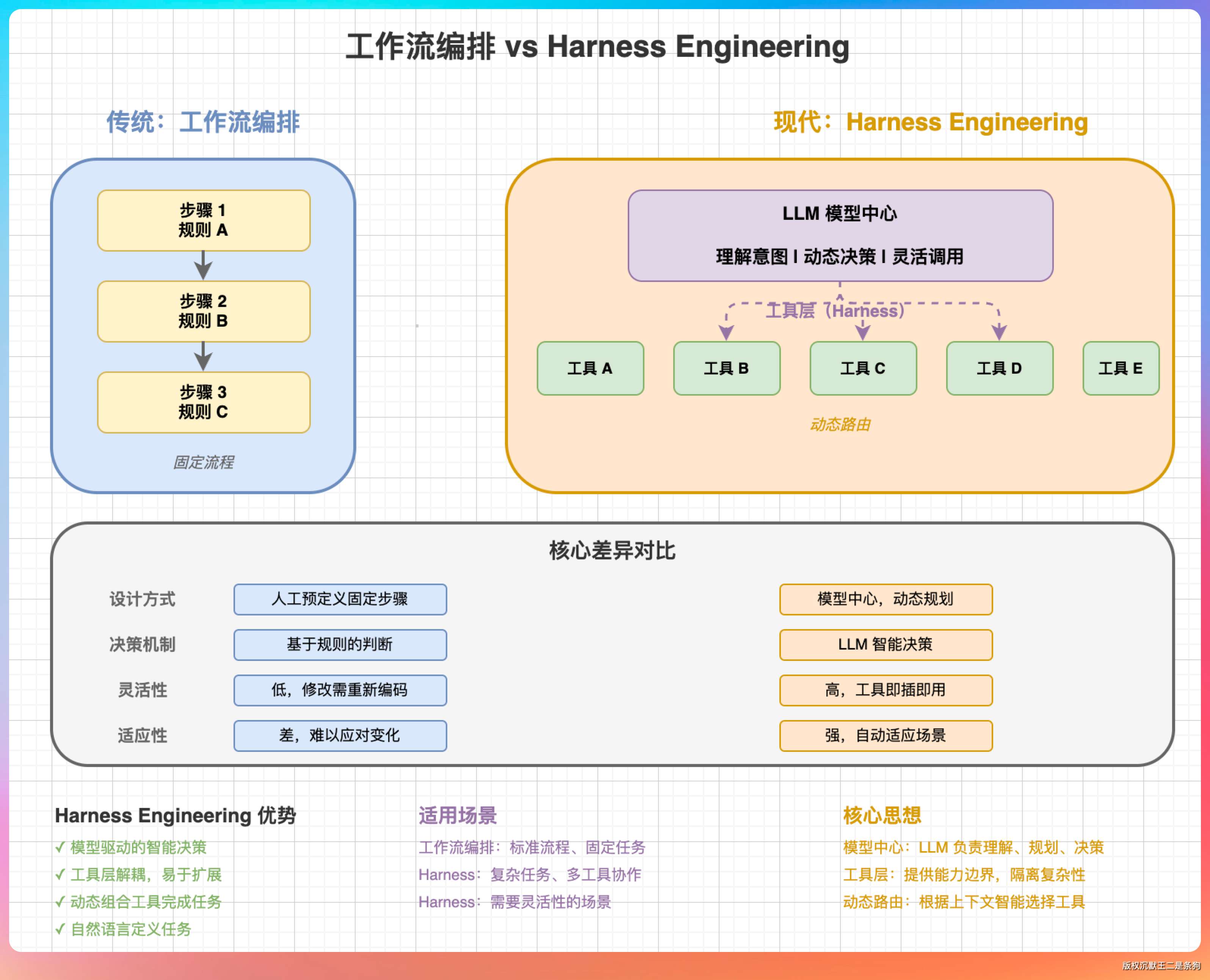
“Agent 是模型本身。模型已经学会了怎么推理、怎么规划、怎么调用工具。你做的工作,不是替它规划,而是给它提供一个好的运行环境,工具、知识、权限、上下文。”
“这就像你雇了一个很厉害的员工。你不需要告诉他每一步怎么做,你需要做的是:给他配好电脑、给他开通系统权限、给他准备好文档资料、给他足够的信息支持。然后让他自己干。”
“而且 Harness Engineering 强调的是‘设计好的运行环境’,这要求工程师对业务有很深的理解。只有懂业务,才能设计出好用的工具、组织好知识库。”
老王笑了:“你这个观点很有意思。”
“我再深入讲一点,”我说,“Harness Engineering 的本质是‘信任模型’。”
“以前我们不信任模型,觉得它不够聪明,所以要设计复杂的工作流来‘指导’它。现在我们发现,模型已经足够聪明了,我们要做的是‘放手’让它自己干。”
“这种信任不是盲目的,而是基于对模型能力的理解。你知道它能做什么、不能做什么,然后设计合适的环境让它发挥。”
“就像带团队一样。优秀的管理者不是告诉员工每一步怎么做,而是设定目标、提供资源、创造环境,然后让员工自主发挥。Harness Engineering 就是这个思路。”
老王看了看表:“时间差不多了,最后一个问题:如果你要在实际项目里用这套东西,你会怎么做?”
“我会分三步走。”
“第一步,搭一个最基础的 Agent 循环。不要一上来就追求完整,先把基础跑通。”
“第二步,根据业务需求,逐步添加能力。需要读文件就加 read_file 工具,需要执行命令就加 execute_command 工具。不要一次性加太多,每加一层都要验证价值。”
“第三步,当业务复杂度上来之后,再考虑子代理、任务图、上下文压缩这些高级特性。”
“讲真,Agent 开发最怕的就是贪多求全。一上来就想做个完整的 Claude Code,结果往往是半途而废。从简单开始,逐步迭代,才是正确的姿势。”
老王追问:“实际落地中,最大的坑是什么?”
“我觉得有三个坑。”我说,“第一个坑是过度设计。很多人一看 Claude Code 功能很强大,就想一次性把所有功能都实现。结果代码复杂度爆炸,自己都维护不了。”
“第二个坑是忽视边界情况。Demo 的时候一切正常,一到真实环境就各种报错。文件不存在、网络超时、权限不足,这些情况都要考虑。”
“第三个坑是工具设计不好。工具描述写得不清楚,模型不知道啥时候该用;工具参数设计得不合理,模型调用的时候总是传错。这些细节很影响体验。”
老王笑了:“你这套方法论,是从 learn-claude-code 学来的,还是自己总结的?”
“都有。”我也笑了,“项目给了我框架,实践让我知道哪些是真的有用。”
“好,很好,现在就办理入职手续吧!”老王明显激动了。😄
如果你也在准备 AI 相关的面试,我有几点建议。
第一,不要只停留在“用过”的层面。用过 Claude Code、Cursor、Codex 这些工具,只能说明你不排斥新技术。真正能加分的是你能讲清楚背后的原理。
第二,选择一个开源项目深入研究。GitHub 上有很多优秀的 Agent 项目,选一个你感兴趣的,把代码读一遍,自己动手跑一遍,最好能改一遍。这个过程比看十篇博客都有用。
第三,学会“讲故事”。面试不是考试,是交流。把技术细节包装成有逻辑、有起伏的故事,比干巴巴地背知识点更能打动面试官。
最后,保持好奇心和学习热情。AI 领域变化太快,今天的热门技术明天可能就过时了。但底层原理和解决问题的能力,是永远不会过时的。
【会用工具的人被工具定义,理解原理的人定义工具。】
这个差别,在 AI 时代会被无限放大。
Agent 开发没有想象中那么神秘。它不是什么高深的黑科技,而是一层一层的能力叠加。从最简单的对话循环开始,加工具、加计划、加子代理、加压缩,每一层解决一个具体问题。
这种渐进式的开发思路,不仅适用于 Agent 开发,也适用于任何复杂系统的开发。不要试图一口吃成胖子,从简单开始,逐步迭代,才是正确的姿势。
学习资源推荐:
- GitHub 项目地址:https://github.com/shareAI-lab/learn-claude-code
- 项目自带 Web 学习平台,可以在浏览器里体验每一层的效果
- 中文文档齐全,读起来没有障碍
学习路径建议:
- 先通读文档,理解 12 层架构的整体设计
- 从 s01 开始,逐层跑代码,每跑一层都问自己“这层解决了什么问题”
- 尝试修改代码,比如换个模型、加个新工具、改下提示词
- 最后尝试自己实现一个简化版,哪怕只实现 s01 到 s04 也是很大的收获
希望这篇文章对你有帮助。技术的道路上,独行快,众行远。
有问题评论区见,我们下期见!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/248754.html