
宇宙第二牛的AI公司Anthropic在年前发表了一篇特别出色的文章,名为《Building effective agents》(构建有效的Agent),在这个文章中,Anthropic都承认目前对于Agent的定义没有定论。
有的人认为完全自动化、能够处理复杂任务的系统就是Agent,还有一些人认为按照预定工作流来自动化工作的任务就是Agent,Anthropic认为这些定义都算Agentic系统,但是Anthropic应该区分Workflow(工作流)和Agent(智能体)。
名字只是一个代号,重要的是理解名字背后的本质,理解Workflow和Agent可以有利于我们深刻理解Agent。
Workflow就是按照预定流程进行的工作,这个过程中可以通过询问LLM来实现自动化智能,但是,具体过程,实际上都已经预设好了,类似下面的流程。
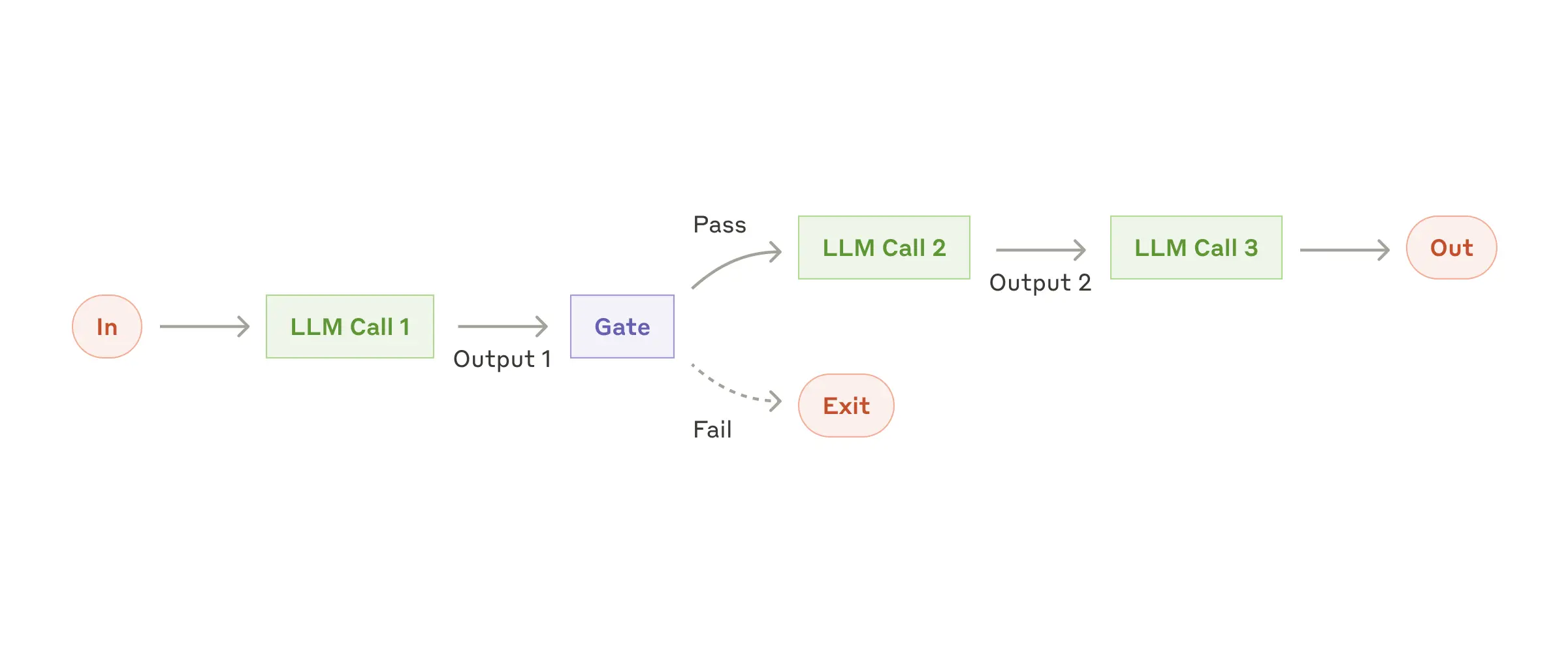
举个具体例子,比如跨国企业的产品使用说明书生成,标准工作流就是,先按照公司模板生成内容,然后翻译成各国语言,然后审核,然后进入发布流程。
这个过程的『生成』和『翻译』就可以借助LLM来完成,实现自动化,可以大大减少甚至不需要人工操作,这就是Workflow,因为有AI的加持,你非要说这是Agent,也没有人能够否认,但是——
按照Anthropic的说法,Agent不是按照预定的工作流工作,而是靠AI自己来规划处工作流程来工作,这就比Workflow更加自动化,也更加能够处理复杂的、需要灵活处理的问题。
同样举个例子,利用Agent来编程(虽然目前Agent编程还没有十分成熟,但是在Web前端开发上已经表现出比实习生更高的效率),写过程序的朋友都知道,无论是写新feature还是fix bug,都可能遇到难以预料的问题,只能逢山开道遇水搭桥,走一步看一步,过程是无法预料的,这过程就非常符合Agent的定义。
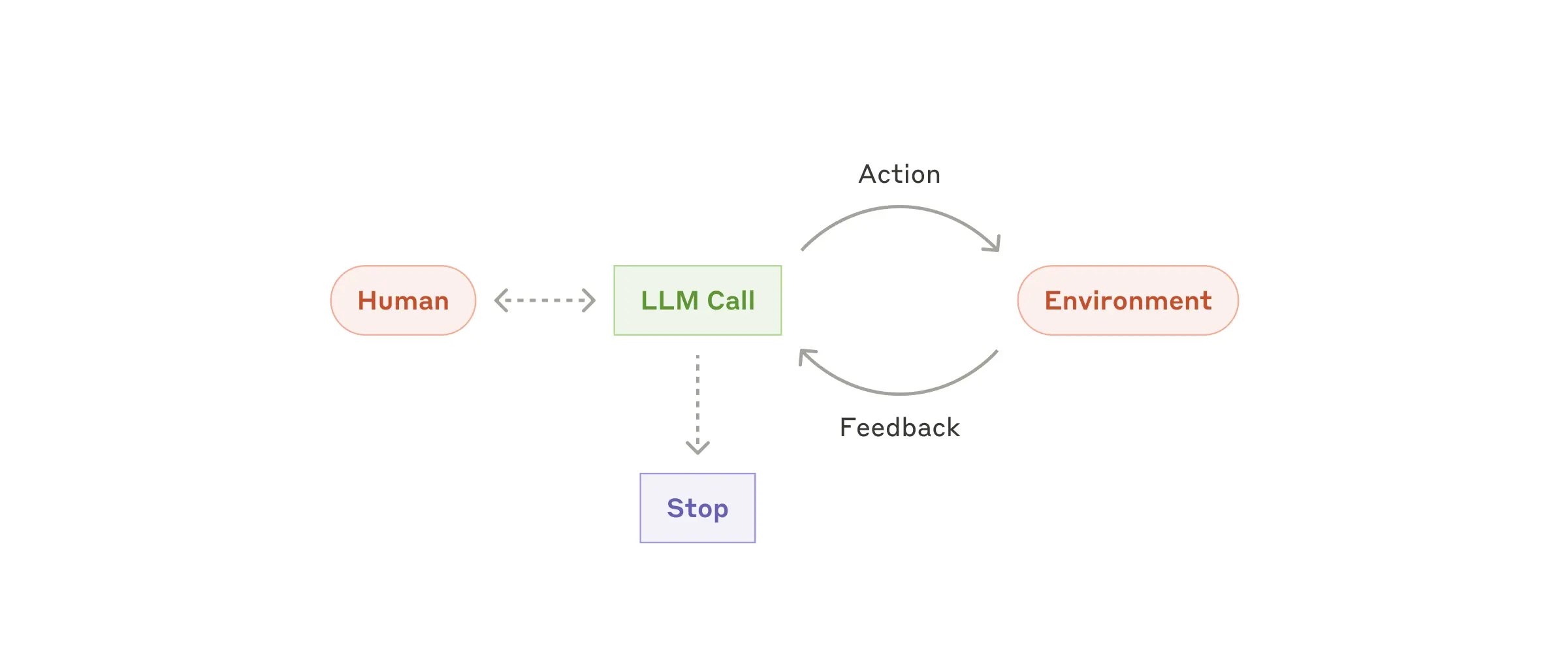
我们给编程Agent一个任务,比如fix一个bug,并不会告诉Agent怎么去做,Agent需要自主发掘怎么做,这当然这也依赖于背后的LLM,Agent让LLM给出一个规划,然后去执行,执行的每一步也收集上下文(context)信息交给LLM去决断,上下文信息包括告诉LLM一些Action。
这些Action包括『你有一个叫做edit code的工具X,可以用来修改代码』和『你有一个编译运行工具Y,可以用来尝试运行代码』,这样LLM会告诉Agent尝试着利用工具去修改和执行代码,注意,这样的尝试未必成功,甚至就贬义都不通过,但没问题,Agent会把Action的结果作为Feedback塞给LLM,给LLM机会去调整修改代码的内容。
如此迭代下去,很明显,这个过程不是预先能够定义好,只能摸着石头过河,让LLM根据具体feedback去不断调整流程计划。
很明显,Agent和Workflow各有优劣:
- Workflow容易实现,可以把简单的、已经很成熟的流程利用AI自动化。
- Agent实现复杂,能够处理复杂的、不可预期的问题,但是准确度肯定没有Workflow高。
大家都在说2025年回事Agent大年,我也相信,按照LLM目前的发展水平,一方面AGI遥遥无期,另一方面LLM的成本又在下降,AI应用的发展就会成为下一个热点,毕竟,行业总会找到自己的出路,而Agent就是AI行业的下一个出路之一。
如果你要设计或者开发AI应用,那就一定要搞清楚Workflow和Agent的区别,但是,Anthropic的那篇文章只介绍了基本分类和一些tips,并没有具体的实践和技能,如果你还想在这方面扩充自己的AI能力,我推荐你去看一看知乎知学堂的AI课程,这个课程覆盖了AI技术原理、AI产品思维、项目实战,总结得非常好,可以说是投入时间产出比相当高的学习方法了,最重要的是,免费,学到一点都是赚到了。
我看了两节课程,感觉受益匪浅,尤其是对于AI产品思维部分,非常接地气。
说完Workflow和Agent,我们在来看另一个问题——
2022年底ChatGPT发布以来,功能上增加了Web Search、Canvas等等,性能上的表现随着LLM参数量的增加也今非昔比,但是,本质上ChatGPT还只是一个chatbot,还是用户的一个行为驱动LLM一个响应的模式。
更简单地说,ChatGPT就属于『一问一答』的和LLM交互方式。
而Agent是『一问』引发自动多次和LLM交互,根据LLM返回的结果决定接下来如何继续『问』LLM,多轮重复,最终得到一个充分考虑的结果。
这就是ChatGPT这类产品和Agent类产品最大的不同。
值得一提的事,OpenAI去年推出的o1和o3推理模型,也类似这种多轮重复的工作模式,那他们算不算一个Agent呢?
虽然OpenAI公开的实现细节不多,但是很清楚o1和o3模型(姑且叫草莓模型)都是在推理(inference)阶段重复多轮才得到结果。
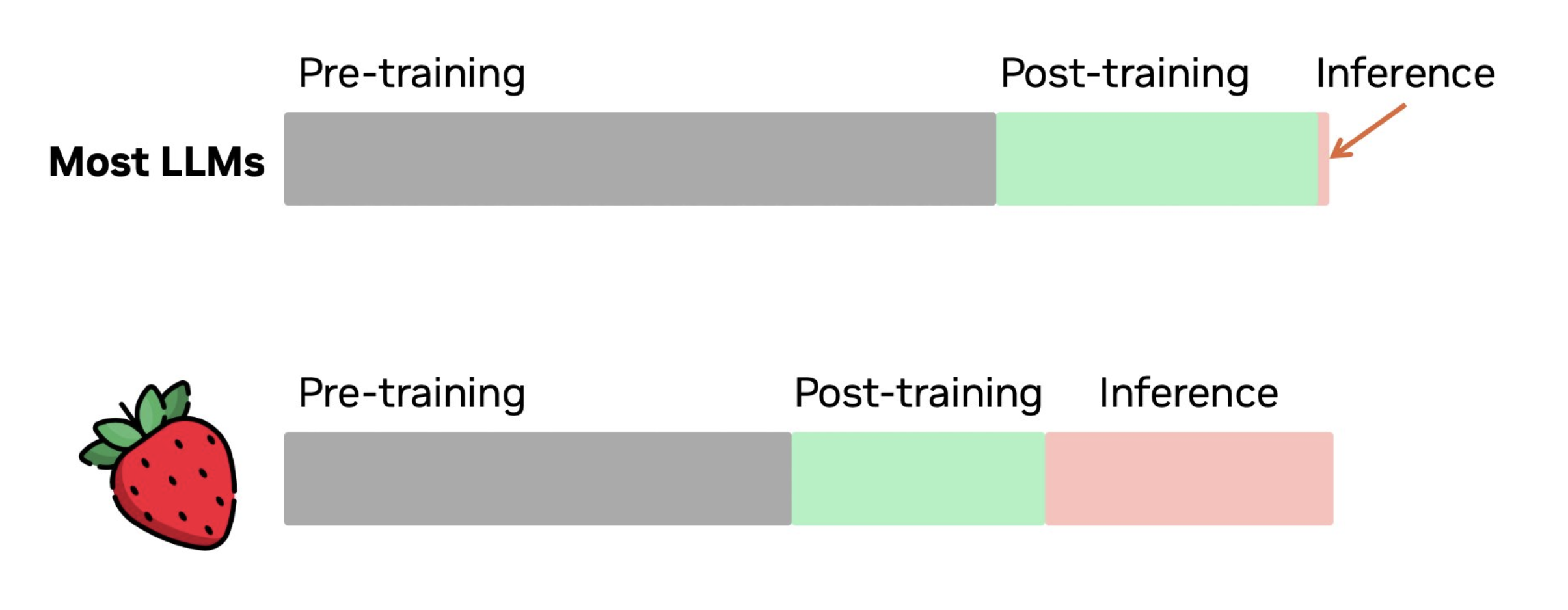
这种重复多轮的推理,的确很像Agent多次调用LLM的方式,但是,有一个本质区别,那就是Agent就能访问环境,而LLM不能。
我们再来看一看Agent的工作流程图,最右边就是环境(Environment)。
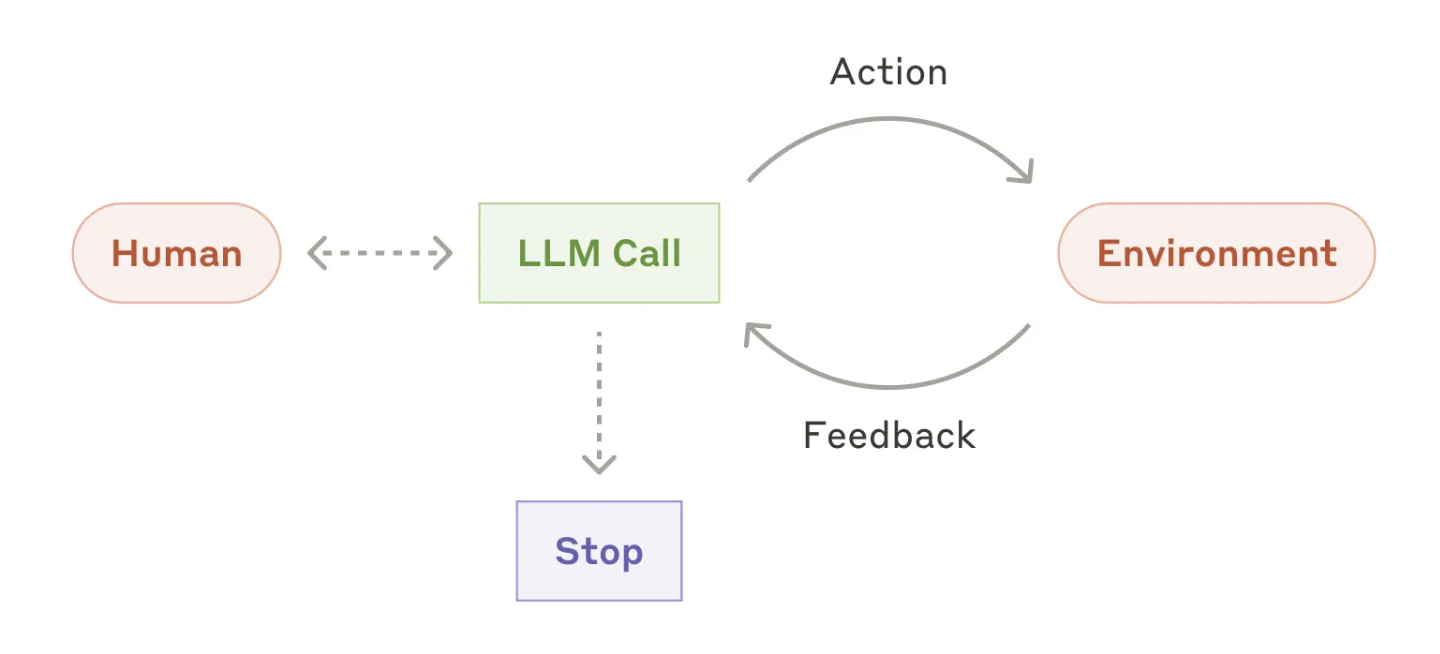
还是拿编程Agent举例,环境可以是一个真实存在的Docker环境,真实的代码,真实的运行测试环境,LLM可以让Agent产生Action发给环境,修改代码,编译代码,运行代码,看一看修改得怎么样,一次不行可以继续调试,就和人类程序员一样fix bug。
对于o1和o3,虽然也是重复多轮,但是并没有一个外部环境用来操作,完全就是LLM在自己的虚拟世界中多轮折腾。
当然,并不是说Agent就比o1/o3更强,实际上,Agent和o1/o3是不同层面的概念,一个属于AI应用层面,另一个是AI基础模型层面,而且Agent也可以利用o1/o3作为自己的依赖的大模型。
但是,o1和o3无论训练成本还是运营成本都十分巨大,做一道题都需要几百几千美金,而Agent相对开发成本就要小得多,而且更加灵活,对于特定领域的AI引用,使用Agent要比利用o1、o3大模型更加现实。
最近这段时间AI agents很火,但是估计很多人对agents是什么都不是太理解。这篇文章我们简单介绍一下HuggingFace官方发布的一个库smolagents,这是一个非常简单的库,它为大语言模型解锁了“代理”能力。
你可以用smolagents库很快创建一个agent,下面是代码示例:
from smolagents import CodeAgent, DuckDuckGoSearchTool, HfApiModelagent = CodeAgent(tools=[DuckDuckGoSearchTool()], model=HfApiModel())
agent.run(“How many seconds would it take for a leopard at full speed to run through Pont des Arts?”) # 一只猎豹全速奔跑通过艺术桥(Pont des Arts)需要多少秒? https://www.zhihu.com/video/1858660348355280896
https://www.zhihu.com/video/1858660348355280896
希望通过对这个库的介绍,能帮助大家理解AI agent。
任何使用AI的高效系统都需要为大语言模型(LLMs)提供某种形式的现实世界访问权限:例如,调用搜索工具以获取外部信息的可能性,或者为了解决任务而对某些程序采取行动。换句话说,LLMs应该具有代理能力(agency)。代理程序是LLMs通往外部世界的门户。
AI agents是LLM输出控制工作流的程序。
任何利用LLMs的系统都将把LLM的输出整合到代码中。LLM输入对代码工作流的影响是LLM在系统中的代理程度。请注意,根据这个定义,“agent”不是一个离散的、0或1的定义:相反,“agency”是一个连续的变化,因为你可以在工作流中给予LLM更多或更少的权力。
下表说明了不同系统中代理能力的变化:
| 代理水平 | 描述 | 这样称呼 | 示例模式 |
| ☆☆☆ | LLM输出对程序流程没有影响 | 简单处理器Simple processor | process_llm_output(llm_response) |
| ★☆☆ | LLM输出决定基本控制流程 | 路由器Router | if llm_decision(): path_a() else: path_b() |
| ★★☆ | LLM输出决定函数执行 | 工具调用Tool call | run_function(llm_chosen_tool, llm_chosen_args) |
| ★★★ | LLM输出控制迭代和程序继续 | 多步代理Multi-step Agent | while llm_should_continue(): execute_next_step() |
| ★★★ | 一个代理工作流程可以启动另一个代理工作流程 | 多代理Multi-Agent | if llm_trigger(): execute_agent() |
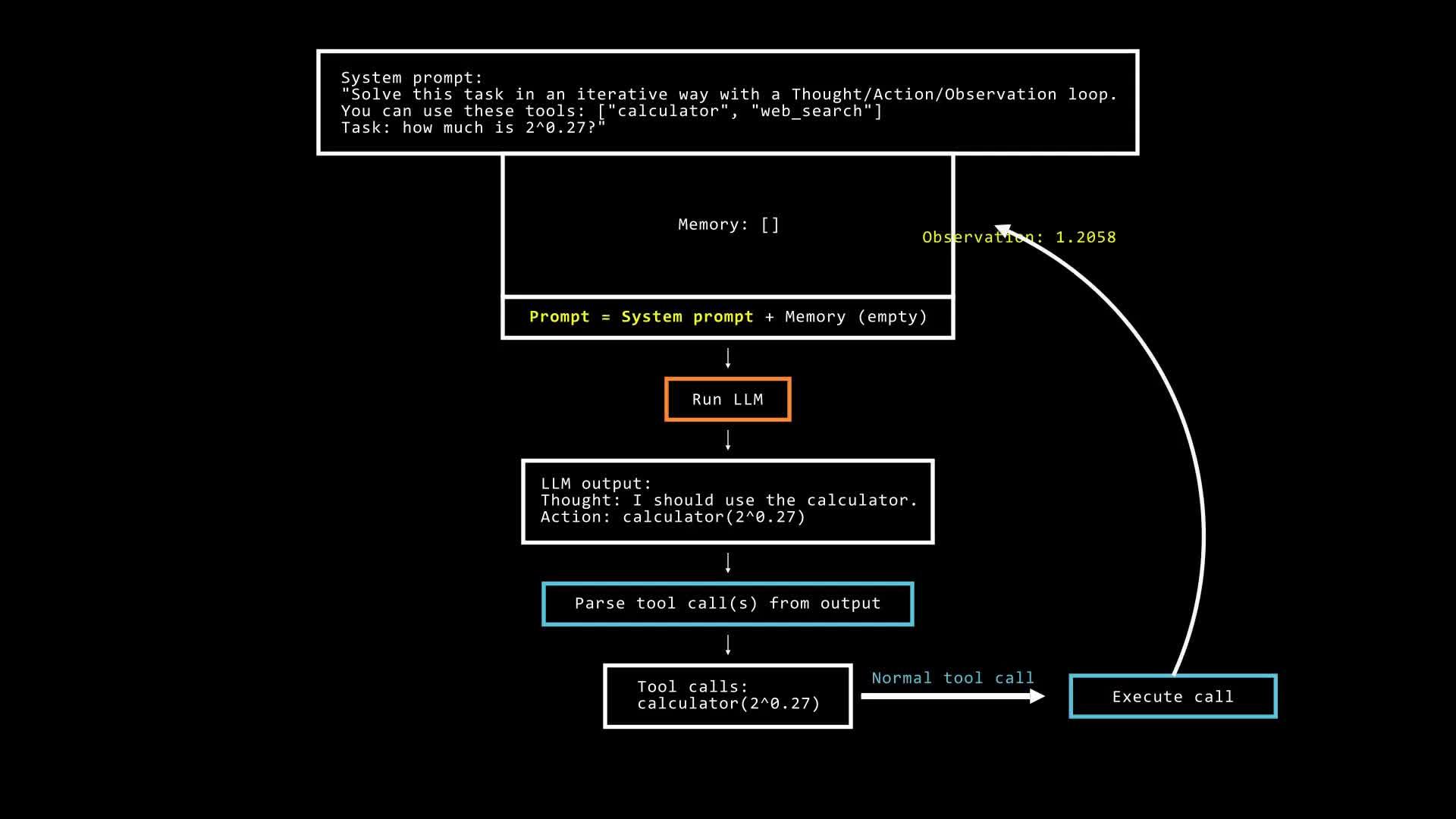
多步代理具有以下代码结构:
GPT plus 代充 只需 145memory = [user_defined_task] while llm_should_continue(memory): # 这个循环是多步部分
action = llm_get_next_action(memory) # 这是工具调用部分 observations = execute_action(action) memory += [action, observations]因此,这个系统在一个循环中运行,在每一步执行一个新的动作(这个动作可能涉及到调用一些预先确定的工具,这些工具只是函数),直到它的观察结果表明已经达到了一个令人满意的状态,以解决给定的任务。以下是多步代理如何解决一个简单的数学问题的例子:
 https://www.zhihu.com/video/1858660453099655169
https://www.zhihu.com/video/1858660453099655169 当你需要一个LLM来决定应用程序的工作流时,agents是有用的,但它们通常过于小题大做。问题是:你真的需要在工作流中具有灵活性来有效地解决手头的任务吗?如果预先确定的工作流程经常不够用,那意味着你需要更多的灵活性。
这里举个例子:假设你正在制作一个处理冲浪旅行网站客户请求的应用程序。你可能事先知道请求将属于两个类别中的一个(基于用户选择),并且你为这两种情况中的每一种都有一个预定义的工作流程。
- 想要了解一些旅行信息吗?⇒ 让他们使用搜索栏来搜索你的知识库
- 想要和销售人员交谈吗?⇒ 让他们输入联系表格。
如果那个确定性的工作流程适合所有查询,那就编写所有代码!这将为你提供一个100%可靠的系统,避免了不可预测的LLMs干扰工作流程而引入错误的风险。为了简洁性和鲁棒性,建议尽量规范化,避免使用任何代理行为。
但如果工作流程不能很好地提前确定呢?例如,用户可能会问:“我周一可以到达,但我忘了带护照,可能会延迟到周三。请问是否可以在周二早上安排我和我的冲浪装备出行,并附带取消保险?”这个问题涉及许多因素,很可能上述任何预定的标准都无法满足这一请求。
如果预先确定的工作流程经常不够用,那意味着你需要更多的灵活性。这就是代理设置发挥作用的地方。
在上述例子中,你可以制作一个多步代理,它有权访问天气预报的API、用于计算旅行距离的Google Maps API、员工可用性监控面板以及你的知识库上的RAG系统。
直到最近,计算机程序还局限于预先确定的工作流程,试图通过堆积if/else开关来处理复杂性。它们专注于非常狭窄的任务,比如“计算这些数字的总和”或“找到这个图中的最短路径”。但实际上,大多数现实生活中的任务,比如我们上面提到的旅行例子,都不适合预先确定的工作流程。代理系统为程序打开了现实世界任务的广阔世界!
在多步代理中,每一步LLM都可以通过调用外部工具来执行操作。常见的格式(由Anthropic、OpenAI等公司广泛使用)是将这些操作写成JSON格式,包含工具名称和参数,然后解析这些JSON以确定要执行哪个工具以及使用哪些参数。
多篇研究论文(https://arxiv.org/abs/2402.01030,https://arxiv.org/abs/2411.01747,https://arxiv.org/abs/2401.00812)表明:让LLM以代码形式调用工具更好。
原因很简单,我们设计的代码语言专门是为了以**方式表达计算机执行的操作。如果JSON片段是更好的表达方式,那么JSON就会成为顶级编程语言,而编程将变成人间地狱。
下图摘自论文《Executable Code Actions Elicit Better LLM Agents》,展示了用代码编写操作的一些优势:
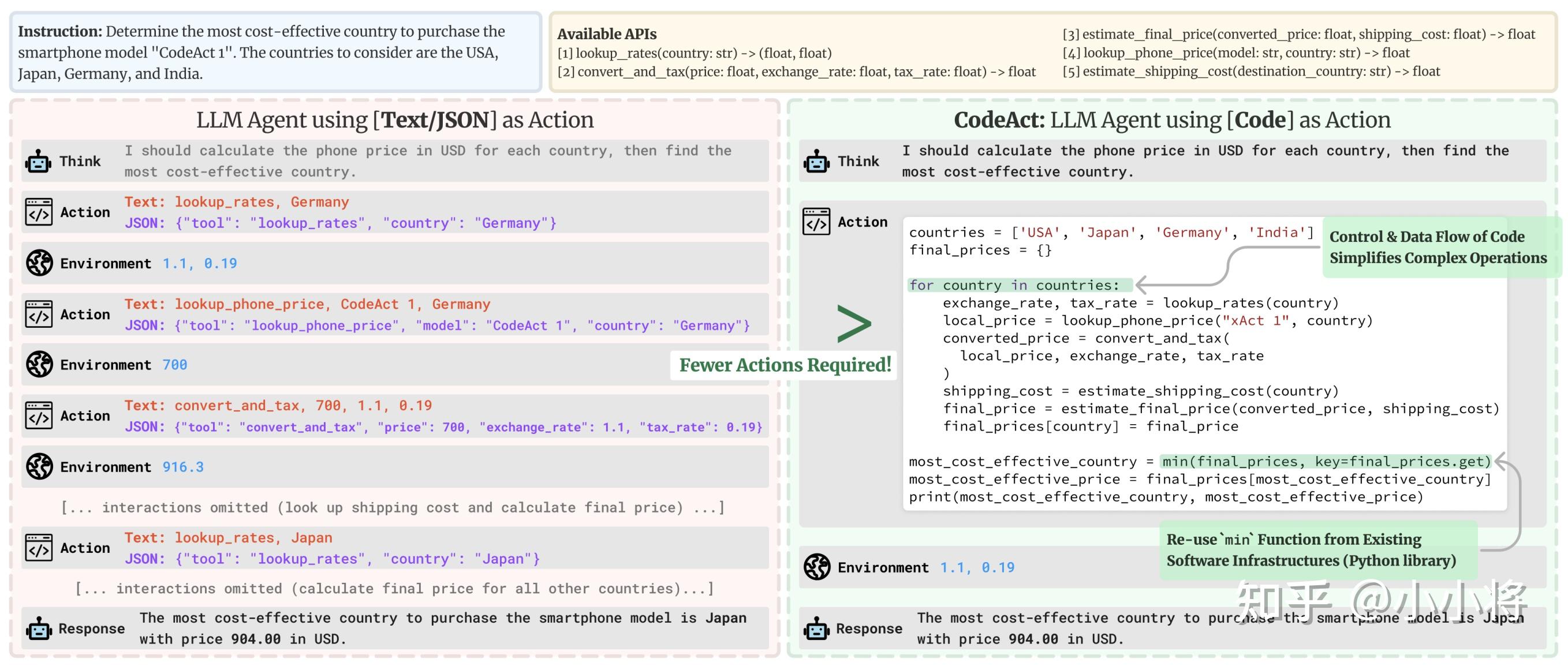
用代码而非类似JSON的片段编写操作具有以下优势:
- 可组合性:你能像在Python中定义一个函数那样,将JSON操作嵌套在一起,或者定义一组JSON操作以便后续复用吗?
- 对象管理:你如何用JSON存储像generate_image这样的操作的输出?
- 通用性:代码的设计初衷是为了简单地表达任何计算机可以执行的操作。
- 在LLM训练数据中的表现:大量高质量的代码操作已经包含在LLM的训练数据中,这意味着它们已经为此做好了训练准备!
smolagents的构建目标如下所示:
- 简洁性:agent的逻辑仅需约千行代码(见此文件),并在原始代码的基础上将抽象保持到最小形式!
- 对Code Agents的一流支持:即agents用代码编写其操作(而不是“用agents来编写代码”)。为了确保安全性,支持通过E2B在沙盒环境中执行。在CodeAgent类的基础上,仍然支持标准的ToolCallingAgent,它以JSON/文本块的形式编写操作。
- Hub集成:你可以从Hub分享和加载工具,更多功能即将推出!
- 支持任何LLM:它支持通过transformers加载的Hub上托管的模型,或通过推理API加载,同时还通过LiteLLM集成支持OpenAI、Anthropic等众多模型。
smolagents是transformers.agents的继任者,未来将取代transformers.agents,因为后者将被弃用。
要构建一个agent,你至少需要两个元素:
- 工具:agent可以访问的工具列表
- 模型:将成为你agent引擎的LLM。
对于模型,你可以使用任何LLM,无论是使用HfApiModel类开放模型,它利用了Hugging Face的免费推理API,或者你可以使用LiteLLMModel来利用litellm,并从100多个不同的云LLM中选择。
对于工具,你可以创建一个带有输入和输出类型提示的函数,并在docstrings中提供输入描述,然后使用@tool装饰器使其成为一个工具。
以下是如何制作一个从Google Maps获取旅行时间的自定义工具,以及如何将其用于旅行规划代理的方法:
GPT plus 代充 只需 145from typing import Optional
from smolagents import CodeAgent, HfApiModel, tool
@tool def get_travel_duration(start_location: str, destination_location: str, departure_time: Optional[int] = None) -> str:
"""Gets the travel time in car between two places.
Args: start_location: the place from which you start your ride destination_location: the place of arrival departure_time: the departure time, provide only a datetime.datetime if you want to specify this “”“
GPT plus 代充 只需 145import googlemaps # All imports are placed within the function, to allow for sharing to Hub.
import os
gmaps = googlemaps.Client(os.getenv("GMAPS_API_KEY"))
if departure_time is None:
from datetime import datetime
departure_time = datetime(2025, 1, 6, 11, 0)
directions_result = gmaps.directions(
start_location,
destination_location,
mode="transit",
departure_time=departure_time
)
return directions_result[0]["legs"][0]["duration"]["text"]
agent = CodeAgent(tools=[get_travel_duration], model=HfApiModel(), additional_authorized_imports=[”datetime“])
agent.run(”Can you give me a nice one-day trip around Paris with a few locations and the times? Could be in the city or outside, but should fit in one day. I‘m travelling only via public transportation.“)
在经过几步收集旅行时间和运行计算后,agents返回了以下最终建议:
Out - Final answer: Here’s a suggested one-day itinerary for Paris:
Visit Eiffel Tower at 9:00 AM - 10:30 AM
Visit Louvre Museum at 11:00 AM - 12:30 PM
Visit Notre-Dame Cathedral at 1:00 PM - 2:30 PM
Visit Palace of Versailles at 3:30 PM - 5:00 PM
Note: The travel time to the Palace of Versailles is approximately 59
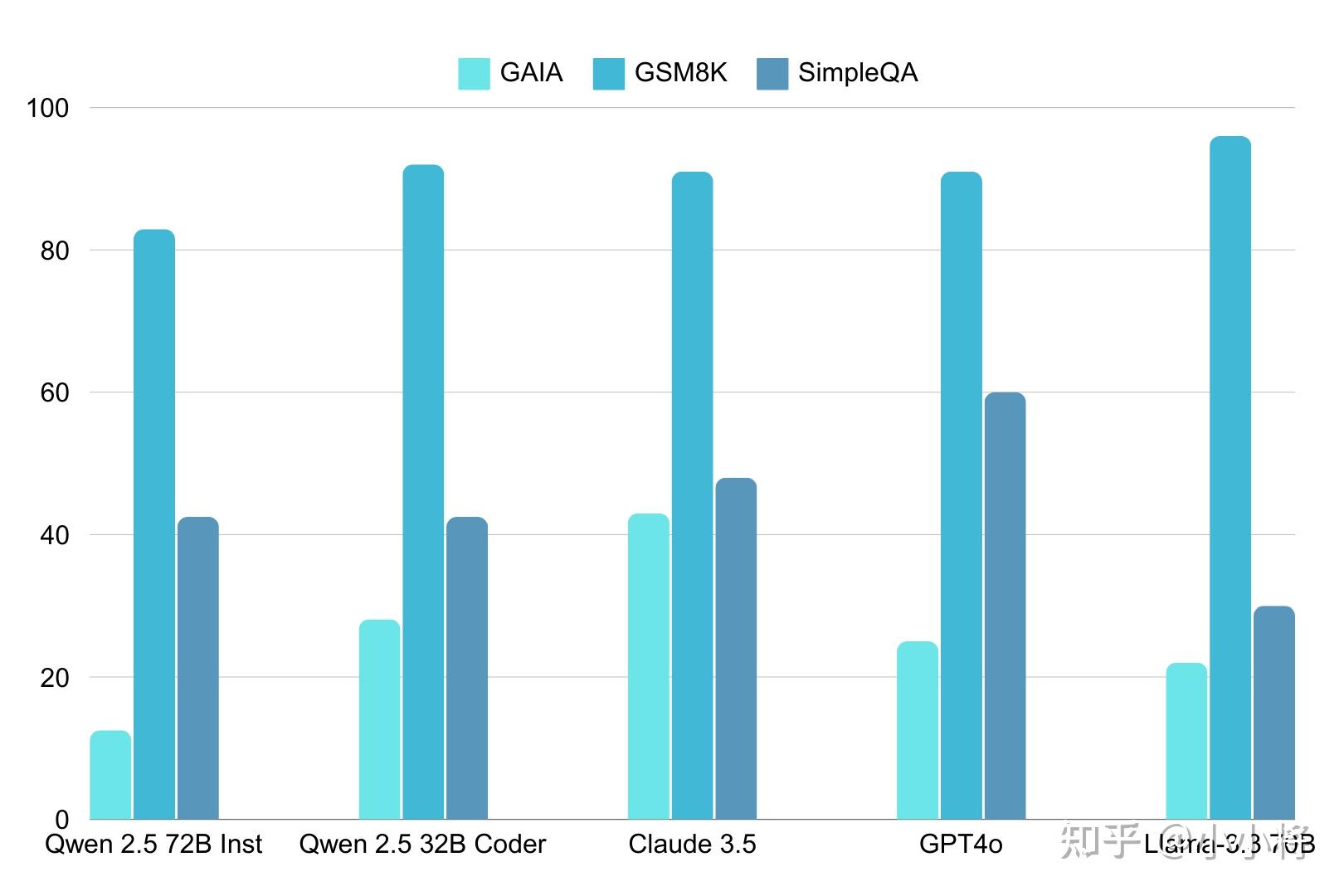
minutes from Notre-Dame Cathedral, so be sure to plan your day accordingly.那么开源模型在代理工作流中的表现如何?这里用一些领先的模型创建了CodeAgent实例,并在这个基准测试中进行了比较。该基准测试从多个不同的基准中收集问题,提供了一系列多样化的挑战。这一比较表明,开源模型现在可以与最好的闭源模型一较高下了!
另外,对于AI agents,你还可以深入学习一下Anthropic的最新文章:《Building effective agents》,以及关于AI agents的研究论文集合:https://huggingface.co/collections/m-ric/agents-65ba776fbd9e29f771c07d4e。
Agent又是一个被社会炒糊了概念,就像AGI一样。已经没人知道Agent和AGI代表着啥。
我从ChatGPT和OpenAI o1两种产品,来简单说说Agent。
ChatGPT:
ChatGPT是一个被动者,你可能不会感觉到它有“活体性”,它的回复受到了SFT,RLHF等微调的概率牵引(谢谢肯尼亚的黑人bro专业团队做的标注工作)。

ChatGPT其实上是一个提线木偶,是一个傀儡,No Agency,No Autonomy,所有的事,都是事先预谋好的,都是假的,虚拟的。
你觉得ChatGPT好用,懂人,实际上掉进了OpenAI预先准备的“用户埋伏圈”,你实际上被算计了。
这种非Agentic模型,有啥优势? 便宜啊,丹尼尔·丹尼特有句话:你预判了对手,你的算力开销会成吨地下降,在愚蠢的对手会经过的路径上,打好埋伏就好。

但问题呢?随着标注难度的提升,肯尼亚专业团队的技术实力hold不住了。艾玛,这咋整。
这个时候就要祭出专家团队,但问题还是存在:开支高,效率低,还要双休,居家办公。 ——(╯‵□′)╯︵┴─┴ 给你再送个酸菜鱼,要不要?
这个时候,有个大明白说了,那就让AI自己写提示词吧,受不了了。
于是就有RL Reasoning Agent。
OpenAI o1
OpenAI o1就是一个Agent,就像一条被拴着绳的狗子,它们在一定范围内具有很强的自主性,套着绳子主要防止咬人,你给它一个任务,它会完全按照自己强化学习训练后思路去跑(找骨头?)
这种思路是否有效,不是由人主宰,而是“自然”主宰的,一道数学题是否正确,不以任何人的意志而转移。
人类不会再手把手提着它,怎么走路,怎么叫,让它们自己去几百遍,几千遍,几万遍地去跑,直到找到那些具有普遍有效性的思路。(OpenAI称之为CoT RL Reasoning)
——
Agent这个词,是在强化学习领域产生的,代表一个被训练的智能体(通常就是牛马式的反复试错),我不知道是谁起的这倒霉名字,在我的收藏中,看到的是马文明斯基在1986年写的《The Society of Mind》中提到了Agent的概念。那时候学术圈似乎都在发力RL,比如1988年的TD算法和1989年的Q-Learning。OpenAI其实很明白Agent的含义,因为他们本来就是搞这些东西的。

Agent→自主探索(弹性)→强化学习,这是一条经典路径。
现在,阿狗阿猫的,在SFT模型上加个“前置提示词”就自称Agent。恶心! 上点RL吧,哪怕是RLHF,花点,花不了几个钱。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/242834.html