
马斯克:Grok 5将于今年年底前推出。
马斯克:Grok 5将于今年年底前推出。我不认为Grok 5会有本质(通用智力)突破,以及颠覆性应用。
——通用的底层智能General Foundational Intelligence,作为一个“幽灵”是否存在,仍然是个谜。
那种ARC测试就像瑞文测试,这种测试没有什么意义,人和Agent最能依靠的智能是经验和经历,尤其是经过“环境奖惩压力测试”的经验(对于DL模型来说,就是数据的多样性、针对性、准确性),而不是靠什么ARC和瑞文智力。这种过度抽象和简化的东西,就很不符合进化论的形式复杂性。
一个简单的逻辑,如果瑞文测试无法测试出人类真实的智能,就像你面试时,不用出具瑞文测试成绩,但必须要出具你的经验履历——那你怎么铁口直断ARC可以测试出模型的真实智能?
——目前语言模型能做的事,基本都已经被畅想出来了,都是处于那种“能想到但做大不到”的水平。这个东西,在我们的想象之中,预测之中,那么,就很难说是什么“颠覆”。
另外,过拟合匹配,正在毒害benchmarks,比如GPT-OSS 基准智力80,实际智力可能只有20。
xAI是刷榜大佬,对于马斯克与Sam Altman这种0道德玩家,你可以有一个信念:只要一个benchmark可以被hack,那么它一定会被hack。这个和lmsys arena是一个道理。
(但马斯克比Sam 稍微强一点,至少不会挂羊头卖狗肉,拿廉价的小型Coder模型充当大型General模型)
如果老马认为benchmarks=智能本智,hacking benchmarks = 追求智能,那成功是唾手可得的。
目前,还保持基本信用的,
只有Anthropic和Google,
未来的变革,也大概率只会在这两家中发生,
如果让我再加一个,也许我会加豆包(他们现在有在认真做好底子,而不是去打榜)。
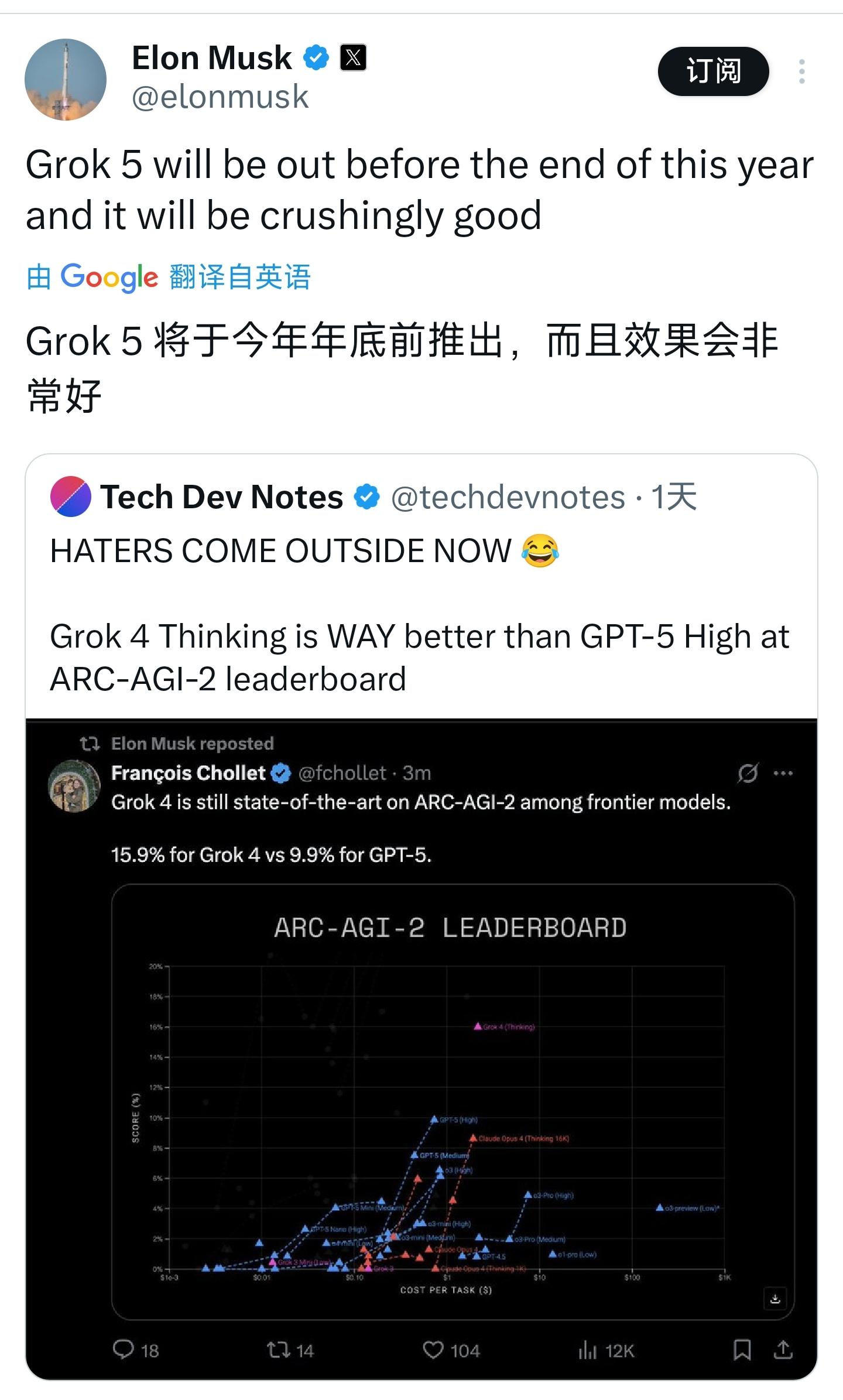
马斯克在X平台上发表声明,宣称Grok5有望成为真正的通用人工智能(AGI)。
以Grok4为例,其表现令人瞩目:在一项模拟经营自动售货机的测试中,该AI需要像企业主一样管理库存、定价和订单。结果显示,Grok4的销量几乎是GPT5的两倍,并能维持业务运营近一年之久,充分展现了其卓越的长期推理能力。
但用户的真实体验却截然不同,网络上充斥着对Grok的负面评价,包括服务不稳定、回答质量不佳,甚至有人认为模型性能出现倒退。
这就暴露出了一个巨大的矛盾:为何在复杂测试中表现完美的AI,到了用户手中却问题频出。
亮眼的基准测试成绩与糟糕的日常体验,究竟哪个更能代表Grok的真实水平?Grok5会是AGI的黎明,还是又一个仅存在于发布会上的神话?在它真正解决用户基本体验问题之前,所有宏大叙事都值得商榷。
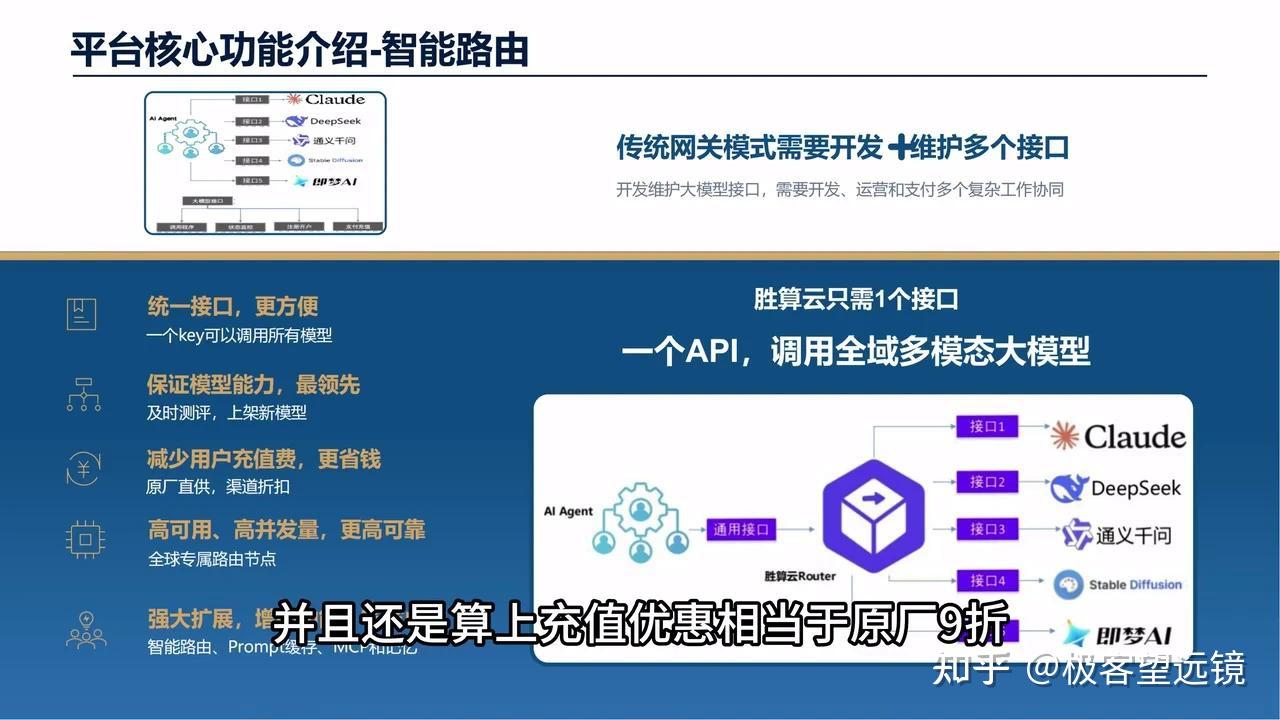
最近调用大模型API时,我都在使用胜算云平台。该平台通过单一API即可调用所有主流大模型,且包含充值优惠,实际使用成本相当于原价的九折。
文章来源:「来源见截图水印」







版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/237160.html