
对中文文本进行分词,词频统计,实体分析,数据可视化等统计
通过主程序统一调用,使用方便
核心库:jieba(cut/lcut函数),pandas(数据统计与存储),matplotlib/pyecharts(饼图,柱状图,词云,关系图),jieba.analyse/LAC(人名,地点,武器名提取)
测试数据:三国演义全文提取地名
测试结果
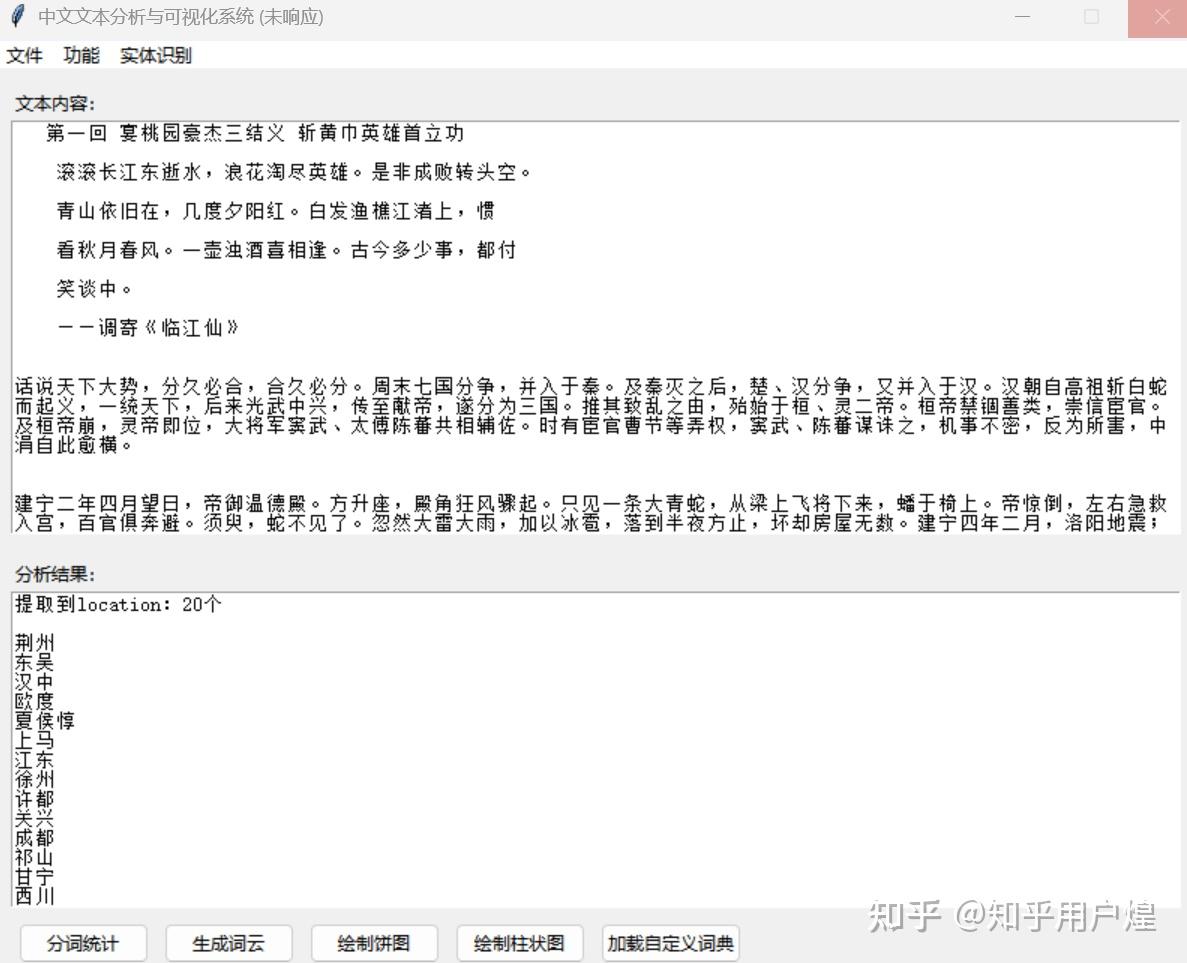
以下是代码
import tkinter as tk from tkinter import filedialog, messagebox, ttk import jieba import jieba.analyse from collections import Counter import matplotlib.pyplot as plt from wordcloud import WordCloud import os解决中文显示问题
plt.rcParams[‘font.sans-serif’] = [‘SimHei’] plt.rcParams[‘axes.unicode_minus’] = False
class NLPTextAnalyzer:
def __init__(self, root): self.root = root self.root.title("中文文本分析与可视化系统") self.root.geometry("800x600") # 全局变量 self.current_text = "" self.current_words = [] self.word_freq = Counter() self.file_path = "" # 创建界面组件 self.create_widgets() def create_widgets(self): # 顶部菜单栏 menubar = tk.Menu(self.root) filemenu = tk.Menu(menubar, tearoff=0) filemenu.add_command(label="打开文件", command=self.load_file) filemenu.add_command(label="保存结果", command=self.save_results) filemenu.add_separator() filemenu.add_command(label="退出", command=self.root.quit) menubar.add_cascade(label="文件", menu=filemenu) funcmenu = tk.Menu(menubar, tearoff=0) funcmenu.add_command(label="分词统计", command=self.tokenize_and_count) funcmenu.add_command(label="生成词云", command=self.generate_wordcloud) funcmenu.add_command(label="绘制饼图", command=self.plot_pie_chart) funcmenu.add_command(label="绘制柱状图", command=self.plot_bar_chart) menubar.add_cascade(label="功能", menu=funcmenu) entitymenu = tk.Menu(menubar, tearoff=0) entitymenu.add_command(label="提取人名", command=lambda: self.extract_entity("person")) entitymenu.add_command(label="提取地名", command=lambda: self.extract_entity("location")) entitymenu.add_command(label="提取武器名", command=lambda: self.extract_entity("weapon")) menubar.add_cascade(label="实体识别", menu=entitymenu) self.root.config(menu=menubar) # 主文本框 self.text_frame = tk.Frame(self.root) self.text_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10) tk.Label(self.text_frame, text="文本内容:").pack(anchor=tk.W) self.text_area = tk.Text(self.text_frame, wrap=tk.WORD, height=15) self.text_area.pack(fill=tk.BOTH, expand=True) # 结果显示区域 self.result_frame = tk.Frame(self.root) self.result_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5) tk.Label(self.result_frame, text="分析结果:").pack(anchor=tk.W) self.result_area = tk.Text(self.result_frame, wrap=tk.WORD, height=10) self.result_area.pack(fill=tk.BOTH, expand=True) # 底部按钮区 self.btn_frame = tk.Frame(self.root) self.btn_frame.pack(fill=tk.X, padx=10, pady=5) ttk.Button(self.btn_frame, text="分词统计", command=self.tokenize_and_count).pack(side=tk.LEFT, padx=5) ttk.Button(self.btn_frame, text="生成词云", command=self.generate_wordcloud).pack(side=tk.LEFT, padx=5) ttk.Button(self.btn_frame, text="绘制饼图", command=self.plot_pie_chart).pack(side=tk.LEFT, padx=5) ttk.Button(self.btn_frame, text="绘制柱状图", command=self.plot_bar_chart).pack(side=tk.LEFT, padx=5) ttk.Button(self.btn_frame, text="加载自定义词典", command=self.load_custom_dict).pack(side=tk.LEFT, padx=5) # 1. 加载文本文件 def load_file(self): self.file_path = filedialog.askopenfilename( title="选择文本文件", filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")] ) if not self.file_path: return try: with open(self.file_path, "r", encoding="utf-8") as f: self.current_text = f.read() self.text_area.delete(1.0, tk.END) self.text_area.insert(tk.END, self.current_text) messagebox.showinfo("成功", "文件加载完成!") except Exception as e: messagebox.showerror("错误", f"加载文件失败:{str(e)}") # 2. 加载自定义词典 def load_custom_dict(self): dict_path = filedialog.askopenfilename( title="选择自定义词典", filetypes=[("词典文件", "*.txt"), ("所有文件", "*.*")] ) if dict_path: try: jieba.load_userdict(dict_path) messagebox.showinfo("成功", "自定义词典加载完成!") except Exception as e: messagebox.showerror("错误", f"加载词典失败:{str(e)}") # 3. 分词与词频统计 def tokenize_and_count(self): self.current_text = self.text_area.get(1.0, tk.END).strip() if not self.current_text: messagebox.showwarning("提示", "请先加载或输入文本!") return # 分词(过滤空白字符) self.current_words = [w for w in jieba.lcut(self.current_text) if w.strip()] # 词频统计 self.word_freq = Counter(self.current_words) # 显示结果 self.result_area.delete(1.0, tk.END) self.result_area.insert(tk.END, f"分词总数:{len(self.current_words)}\n") self.result_area.insert(tk.END, f"词汇数:{len(self.word_freq)}\n\n") self.result_area.insert(tk.END, "Top 20 高频词:\n") for word, cnt in self.word_freq.most_common(20): self.result_area.insert(tk.END, f"{word}\t{cnt}\n") # 保存词频到文件 with open("word_freq.txt", "w", encoding="utf-8") as f: for word, cnt in self.word_freq.most_common(): f.write(f"{word}\t{cnt}\n") messagebox.showinfo("完成", "分词统计完成,结果已保存至 word_freq.txt") # 4. 生成词云 def generate_wordcloud(self): if not self.word_freq: messagebox.showwarning("提示", "请先进行分词统计!") return try: wc = WordCloud( font_path="simhei.ttf", # 需确保系统有该字体,或替换为其他中文字体路径 background_color="white", width=800, height=600 ).generate_from_frequencies(self.word_freq) plt.figure(figsize=(10, 8)) plt.imshow(wc, interpolation="bilinear") plt.axis("off") plt.title("文本词云") plt.savefig("wordcloud.png", dpi=300, bbox_inches="tight") plt.close() messagebox.showinfo("完成", "词云已保存至 wordcloud.png") except Exception as e: messagebox.showerror("错误", f"生成词云失败:{str(e)}") # 5. 绘制饼图(Top 10 高频词) def plot_pie_chart(self): if not self.word_freq: messagebox.showwarning("提示", "请先进行分词统计!") return top10 = self.word_freq.most_common(10) labels = [x[0] for x in top10] sizes = [x[1] for x in top10] plt.figure(figsize=(8, 8)) plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90) plt.title("Top 10 高频词占比") plt.savefig("pie_chart.png", dpi=300, bbox_inches="tight") plt.close() messagebox.showinfo("完成", "饼图已保存至 pie_chart.png") # 6. 绘制柱状图(Top 20 高频词) def plot_bar_chart(self): if not self.word_freq: messagebox.showwarning("提示", "请先进行分词统计!") return top20 = self.word_freq.most_common(20) words = [x[0] for x in top20] counts = [x[1] for x in top20] plt.figure(figsize=(12, 6)) plt.bar(words, counts, color="#4CAF50") plt.xticks(rotation=45, ha="right") plt.title("Top 20 高频词统计") plt.xlabel("词汇") plt.ylabel("频次") plt.tight_layout() plt.savefig("bar_chart.png", dpi=300) plt.close() messagebox.showinfo("完成", "柱状图已保存至 bar_chart.png") # 7. 实体识别(人名/地名/武器名) def extract_entity(self, entity_type): self.current_text = self.text_area.get(1.0, tk.END).strip() if not self.current_text: messagebox.showwarning("提示", "请先加载或输入文本!") return entities = [] if entity_type == "person": entities = jieba.analyse.extract_tags(self.current_text, allowPOS=['nr']) save_path = "person_names.txt" elif entity_type == "location": entities = jieba.analyse.extract_tags(self.current_text, allowPOS=['ns']) save_path = "locations.txt" elif entity_type == "weapon": # 武器名可通过关键词匹配或自定义词典实现,这里用示例逻辑 weapon_keywords = ["刀", "剑", "枪", "炮", "箭", "戟", "斧", "钺", "钩", "叉", "棍", "棒", "鞭", "锏", "锤", "挝", "拐子", "流星", "匕首", "手枪", "步枪", "机枪", "火炮", "导弹"] entities = [w for w in self.current_words if any(k in w for k in weapon_keywords)] save_path = "weapons.txt" # 显示并保存结果 self.result_area.delete(1.0, tk.END) self.result_area.insert(tk.END, f"提取到{entity_type}:{len(entities)}个\n\n") self.result_area.insert(tk.END, "\n".join(entities)) with open(save_path, "w", encoding="utf-8") as f: f.write("\n".join(entities)) messagebox.showinfo("完成", f"{entity_type}提取完成,结果已保存至 {save_path}") # 8. 保存所有结果 def save_results(self): if not self.word_freq: messagebox.showwarning("提示", "请先进行分析!") return messagebox.showinfo("提示", "所有分析结果已自动保存至当前目录下的对应文件") if name == “main”:
root = tk.Tk() app = NLPTextAnalyzer(root) root.mainloop()第二题
OpenClaw龙虾保姆级使用教程|从安装到实战,轻松玩转AI代理
OpenClaw龙虾保姆级使用教程|从安装到实战,轻松玩转AI代理
最近OpenClaw(俗称“龙虾”)这款开源自主AI代理火遍科技圈,凭借免费开源、功能强大、易上手的特点,成为打工人、学生党、技术爱好者的效率神器。它能帮我们完成文件整理、代码编写、文本处理、定时任务等一系列操作,堪称“AI打工人”。
这篇教程从零开始,手把手教你OpenClaw的安装部署、基础使用、进阶玩法、实战案例,全程无门槛,新手也能轻松学会,赶紧收藏起来慢慢看!
一、OpenClaw(龙虾)是什么?
OpenClaw是一款免费开源的自主AI代理工具,由Peter Steinberger开发,支持本地部署、云端运行,可通过指令、Web界面、终端TUI等多种方式交互,能根据用户需求自动执行各类任务,无需人工反复操作。
它支持接入OpenAI、Anthropic等主流AI模型,还能安装各类技能插件,拓展文件管理、办公自动化、代码开发等能力,适配Windows、macOS、Linux、安卓多平台,个人使用完全免费,性价比拉满。
二、安装前准备:必备依赖
OpenClaw安装前,需先配置基础依赖,不同平台依赖略有差异,提前安装可避免后续报错:
- 通用依赖:Node.js、Git,用于下载源码和运行环境
- Windows系统:需安装Python 3.8+、PowerShell,开启开发者模式
- macOS系统:安装Homebrew,方便一键部署
- Linux系统:配置好用户权限,安装curl工具
- 安卓手机:安卓7.0及以上系统,开启未知来源安装权限
依赖安装命令:
| Bash# Node.js安装(官网下载:https://nodejs.org/)# Git安装(官网下载:https://git-scm.com/)# macOS一键安装Homebrew/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" |
|---|
三、多平台安装部署教程
(一)本地一键安装(新手首选,Windows/macOS/Linux)
适合个人电脑本地使用,操作最简单,几分钟即可完成部署。
- macOS/Linux系统
打开终端,复制粘贴一键安装脚本,等待自动部署完成:
| Bash# 官方一键安装脚本curl -fsSL https://get.openclaw.ai | bash# macOS也可通过Homebrew安装brew install openclaw |
|---|
- Windows系统
打开PowerShell(管理员模式),执行以下命令:
| Bashirm https://get.openclaw.ai | iex |
|---|
- 验证安装
终端输入openclaw --version,显示版本号即安装成功。
(二)Docker部署(生产/稳定运行)
适合需要长期稳定运行、避免环境冲突的场景,操作如下:
- 新建docker-compose.yml文件,复制以下配置:
| YAMLversion: '3.8'services: openclaw: image: openclaw/openclaw:latest container_name: openclaw restart: unless-stopped ports: - "8000:8000" volumes: - ./openclaw_data:/root/.openclaw environment: # 填入你的AI模型API Key - OPENAI_API_KEY=your-api-key - ANTHROPIC_API_KEY=your-api-key |
|---|
- 终端进入文件目录,执行启动命令:
| Bashdocker-compose up -d |
|---|
- 访问http://localhost:8000即可进入Web界面。
(三)安卓手机安装
- 打开OpenClaw官方社区,下载最新版APK安装包(认准官方,拒绝第三方不明安装包)
- 手机设置中开启未知来源安装,点击APK完成安装
- 进入手机设置→应用管理→OpenClaw,仅开启存储、网络权限,关闭其他隐私权限,避免信息泄露
- 打开APP,完成初始化,设置登录密码即可使用
四、基础使用:三种交互方式,新手必学
OpenClaw支持三种交互模式,可根据使用习惯选择,操作都超简单。
- Web控制台(可视化,最友好)
适合新手,界面直观,无需记命令:
- 终端输入启动命令:
| Bashopenclaw dashboard |
|---|
- 浏览器自动打开http://127.0.0.1:18789,进入Web界面
- 直接输入指令,查看任务进度、历史记录,管理技能插件,全程可视化操作
2. 终端TUI模式(极客专属)
适合喜欢命令行操作的用户,全屏界面更高效:
- 终端输入命令进入TUI模式:
| Bashopenclaw tui |
|---|
- 界面分为聊天记录区、状态栏、输入框,支持快捷斜杠命令:
- /status:查看龙虾运行状态
- /session:切换任务会话
- /model:切换AI模型
- /skills:管理技能插件
3. 终端CLI命令行(批量任务)
适合执行自动化、批量任务,直接输入指令即可:
| Bash# 示例:执行文件整理任务openclaw tools execute file-organizer -- --source ~/Desktop --strategy category |
|---|
五、核心功能与进阶玩法
1. 技能插件安装(拓展能力)
OpenClaw支持安装各类技能插件,解锁更多功能,官方插件安全无风险:
- 进入Web控制台→Skills板块
- 搜索需要的插件(文件整理、代码检查、办公自动化、文本总结等)
- 点击启用,无需重启,立即生效
国内实用插件推荐:微信公众号排版、淘宝订单导出、本地文件管理、长文本总结。
2. 个性化调教(让龙虾更懂你)
刚安装的龙虾需要简单调教,后续执行任务更贴合需求:
- 录入偏好:输入“记住我是职场白领,文件默认存D盘,用飞书沟通,每天9点提醒工作”
- 设置模型:输入“切换为通义千问模型”,适配国内使用
- 限定规则:输入“整理文件时跳过大于1GB的文件,避免卡顿”
3. 定时任务设置(解放双手)
无需手动触发,让龙虾自动完成任务:
| Bash# 示例:每天早上9点,整理昨日桌面文件并发送到邮箱openclaw schedule add "0 9 * * *" "整理桌面文件,按文档、图片分类,生成汇总表发送至" |
|---|
4. 多模型切换
根据任务需求切换AI模型,提升执行效果:
| Bash# 切换为GPT-4openclaw model set openai/gpt-4# 切换为Claude 3openclaw model set anthropic/claude-3-sonnet |
|---|
六、实战案例:3个高频场景,直接套用
案例1:办公文件批量整理
需求:桌面文件杂乱,需按图片、文档、安装包分类,生成整理报告
指令:
| Plain Text帮我整理桌面所有文件,按图片(jpg/png)、文档(pdf/docx)、安装包(exe/zip)分类到对应文件夹,跳过大于2GB的文件,最后生成一份整理报告保存到桌面 |
|---|
执行效果:几分钟完成分类,自动生成报告,桌面瞬间整洁。
案例2:代码BUG检查与优化
需求:检查Python爬虫代码,修复BUG并给出优化方案
指令:
| Plain Text帮我检查这段Python爬虫代码,找出运行报错的BUG,修复后优化代码性能,添加注释,保存为新文件到桌面 |
|---|
执行效果:自动分析代码,定位问题,输出优化后的完整代码。
案例3:长文本总结与内容提炼
需求:读取多篇PDF文档,提炼核心观点,生成汇总总结
指令:
| Plain Text读取桌面“工作文档”文件夹里的所有PDF,总结每份文档的核心内容,提取关键数据,生成一份汇总总结文档,保存为Word格式 |
|---|
执行效果:快速精读文档,自动生成精简总结,省去手动阅读时间。
七、新手避坑指南
- 权限问题:Windows/macOS需开启完全磁盘访问权限,否则无法读取本地文件
- API Key配置:未配置API Key仅能使用基础功能,需在环境变量或配置文件中填入有效密钥
- 插件风险:不安装未知第三方插件,避免病毒入侵和软件崩溃
- 任务指令:指令要清晰明确,不说模糊话术,复杂任务拆分成小步骤下达
- 性能优化:大文件/批量任务先小范围测试,合理设置批次大小,避免系统卡顿
- 隐私安全:本地运行更安全,敏感文件不要上传云端,仅开启必要权限
八、总结
OpenClaw龙虾作为一款开源免费的AI代理,上手难度低,功能实用性拉满,无论是办公、学习还是开发,都能大幅提升效率,真正实现“让AI替你打工”。
按照这份教程操作,从安装到实战全程无压力,新手也能快速玩转。赶紧动手部署一只属于自己的“龙虾”,解锁更多高效玩法吧!
如果安装或使用过程中遇到问题,欢迎在评论区留言,我会一一解答~
第三题
教育领域,医疗健康领域,政务与公共服务领域,金融领域,工业与企业办公领域
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/229705.html