
今天看到蛮有价值的一篇论文。这里跟大家分享一下。就是AI圈子总是不缺新消息,deepseek-ocr
原论文地址:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
通过要是网络不顺畅也能够从这里下载:https://pan.quark.cn/s/fbccae
模型的思路:把文字拍成照片,再用 AI 把照片压成极小的‘视觉令牌’,最后几乎原样地把文字还原回来。一句话:用看图的办法给文字瘦身,还能读得准。
(模型输入输出都是要token化,所以这里直接输入少了90%同样可以保持基础的精度的话,那就相当有价值了,一方面省算力,另一方面基于之前“压缩即智能”的理念,或许模型会产生新的质变。)
核心套路分三步:
- 拍照压缩:用他们自研的 DeepEncoder 把高清图片压成极少的视觉令牌。
- 小模型解码:用 3B 的 MoE 语言模型当“读图识字机”,把令牌变回文字。
- 海量训练:灌了 3000 万页 PDF、1000 万图表、几何题、化学式等五花八门的图,让模型啥都能认。
结果:
- 一页普通文档,别人要花 6000 个tokens,它 100 个就搞定,错误率还更低。
- 一天能“扫”20 万页书,生成大模型预训练材料。
- 还能顺手识别 100 种语言、图表、公式、几何图,堪称“全能扫描王”。
一句话总结:以后大模型看长文,不用逐字啃,先“拍照压缩”再读,又快又省脑。
按人类直觉,一段文字存成 只有几 KB,存成 动辄几百 KB,怎么看都是“图片更胖”。但这里的关键是:
我们关心的不是硬盘容量,而是“模型大脑”里的注意力开销。
在 Transformer 大模型里,
- 文字要一个字(token)一个字地过注意力,1000 字就是 1000 个位置,计算量随长度平方增长。
- 图片先被视觉编码器压成“视觉令牌”,DeepSeek-OCR 能把一整页 1000 字压成 50~100 个视觉令牌,再交给模型。计算量瞬间降了一个量级。
或许这就是中国古话里边提到的“一图胜千言”。
这项技能为处理超长文本献出了新思路:
- 可以模拟人类的“记忆遗忘”机制
- 近期的信息保持高清,久远的信息逐渐压缩
- 为AI处理海量内容开辟了新路径
:就是人脑的记忆曲线本来就
- 刚发生的事,细节纤毫毕现(高分辨率图片);
- 越久以前的事,越只剩模糊轮廓(低分辨率缩略图甚至只剩文字标签)。
DeepSeek 的玩法恰好能对上这条曲线:
- 把对话历史按时间切片成一页页“图片”。
- 新的图片保持高清,视觉令牌多,细节全;
- 越久远的图片越缩越小,令牌指数级减少,信息自然模糊;
- 再久一点直接缩到 0 令牌,等于“遗忘”。
这样模型随时能处理“理论上无限长”的上下文,却只占常数级的显存和计算——显存不再随对话轮数爆炸,而是随“遗忘系数”衰减。
通过DeepSeek-OCR这篇论文提到的方案,能够实现给AI装上了一双“过目不忘”的眼睛,既能高效压缩信息,又能准确还原内容,同时还可以根据需要进行合理压缩,在文档处理和长文本理解方面有着巨大潜力。
其实这篇文章对我个人还有一个很大的启发,不要顺着思维定式去思考问题,或许从模型的角度来去思考解决问题的新思路,可以发现很多之前忽略的本质。
文中提到的几张图,可以拎出来专门看看。
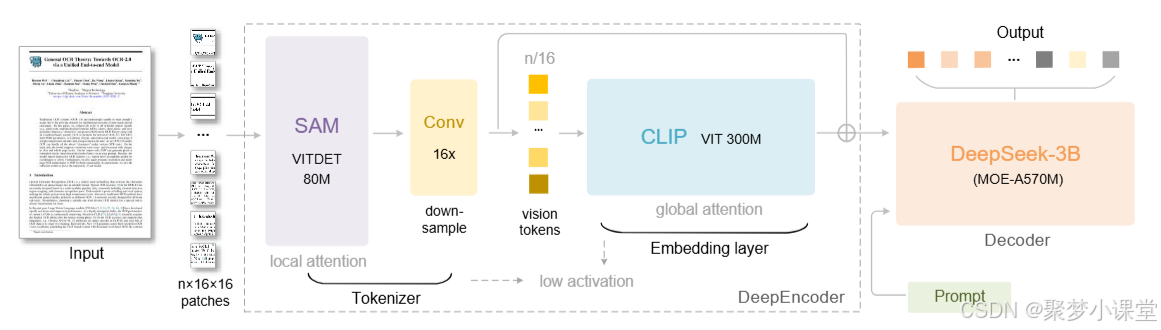
DeepSeek-OCR 的架构。DeepSeek-OCR 由 DeepEncoder(编码器,中间虚线框里边的结构)和 DeepSeek-3B-MoE 解码器两部分组成。
其中,DeepEncoder 是 DeepSeek-OCR 的核心,包含三个组件:一是用于以窗口注意力(window attention)为主导的感知任务的 SAM 模型 ;二是用于具备密集全局注意力(dense global attention)的知识提取任务的 CLIP 模型 ;三是连接前两者的 16 倍 token 压缩器(16× token compressor)。

对于书籍和文章,深度解析模式能够为文档中的自然图像输出密集描述。只需一个提示词,该模型就能自动识别图像类型,并输出所需结果。(其实这个很方便就可以生成大量的训练素材集。)

处于深度解析模式下的 DeepSeek-OCR,还能识别化学类文档中的化学公式,并将其转换为 SMILES 格式。未来,OCR 1.0+2.0 手艺或许会在 STEM 领域(科学、技能、工程、数学领域)的视觉语言模型(VLM)与大语言模型(LLM)发展中发挥要紧作用。

这个模型保留了 DeepSeek-OCR 的通用视觉理解能力,首要包括图像描述、目标检测、视觉定位(grounding)等。同时,由于训练数据中包括纯文本资料,DeepSeek-OCR 的语言能力也得以保留。需注意,由于我们未纳入 SFT(有监督微调,Supervised Fine-Tuning)阶段,该模型并非聊天机器人,部分能力需通过补全提示词(completion prompts)才能激活。
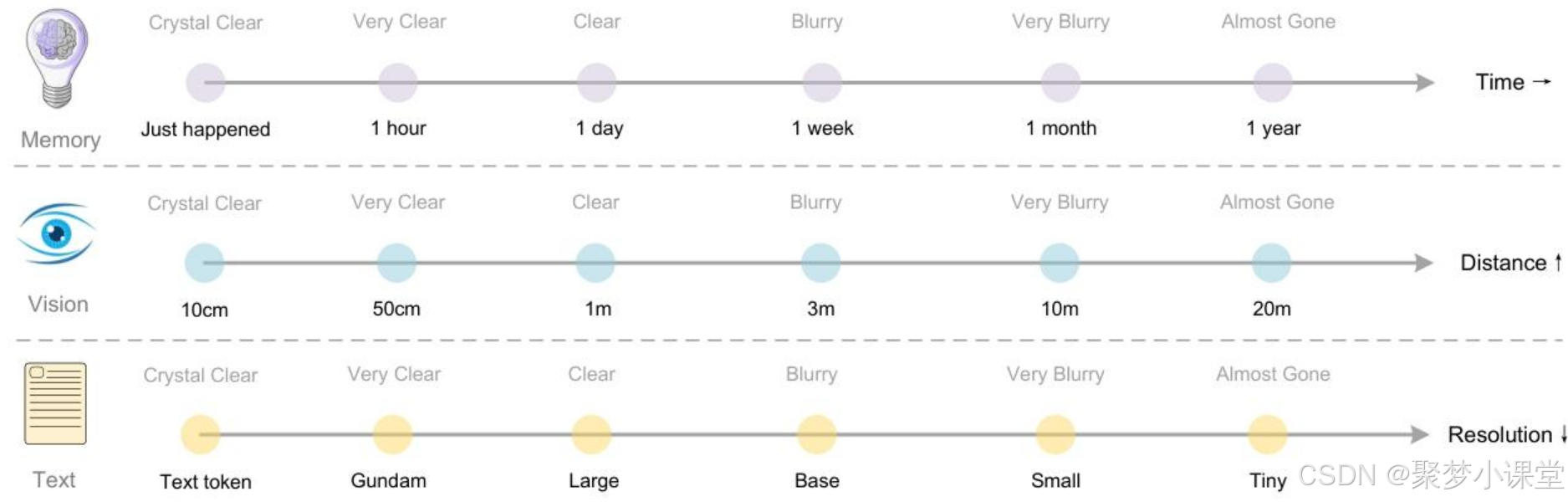
遗忘机制是人类记忆最基本的特征之一。上下文光学压缩技巧可依据以下方式模拟该机制:先将前几轮的历史文本渲染到图像上进行初始压缩,再逐步调整旧图像的尺寸以实现多级压缩—— 在此过程中,token 数量会逐渐减少,文本也会变得越来越模糊,进而实现文本遗忘。
遗忘会不会全部忘干净呢?
这篇论文给的答案是:压缩的本质是 “语义优先的信息蒸馏”
DeepSeek-OCR 的压缩并非轻松的 “图片压缩算法”,而是通过注意力机制 + 结构化训练 + 动态策略,搭建了 “关键信息(结构>细节,语义>像素)的选择性保留”。其核心逻辑与人类视觉类似:读报纸时,我们先捕捉标题和段落结构,再关注具体文字 ——DeepSeek-OCR 通过架构设计,将此种 “语义优先” 的直觉转化为可量化的模型能力,从而在低 token 下保留对 LLM 最有用的信息。
前一段时间有人提出的理念是:自然语言就是一切,围绕自然语言深入下去就可以实现真正的通用智能,也就是AGI,搞世界模型什么的思路都错了…我不否认自然语言是人类进化过程中非常重要的发明,也是因为自然语言的重视才有了transformer和今天的模型生态,但人类好像没有自然语言的话也能正常生活,正常理解该物理世界,也是允许产生智能的,所以ocr的这个思路,或许可以开启将视觉信息重新更高效利用的新篇章。
emm,人类的一切发明,都是来源于仿生。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/225716.html