
视频地址:
平台 api 教程 评分 百度 https://ai.baidu.com/tech/speech 【ESP32S3 Sense接入百度在线语音识别】 7分 讯飞 https://console.xfyun.cn/services/iat 【ESP32S3接入讯飞在线语音识别】 8分

要学习本教程,您需要1个 ESP32S3 开发板。
目前这是我使用的ESP32S3官方硬件👍👍👍(小小的身材有大大的力量)只需要35元加摄像头麦克风79元,后期我会整理相关专栏进行Arduino系统学习😘😘😘。有需要可以购买xiao开发板💕💕💕
- SeeedXIAO ESP32S3 Sense硬件购买地址:https://s.click.taobao.com/lekazrt

- ESP32-S3-CAM 核心开发板 N16R8 wifi蓝牙模块 OV2640摄像头硬件购买地址:https://s.click.taobao.com/1PTagos
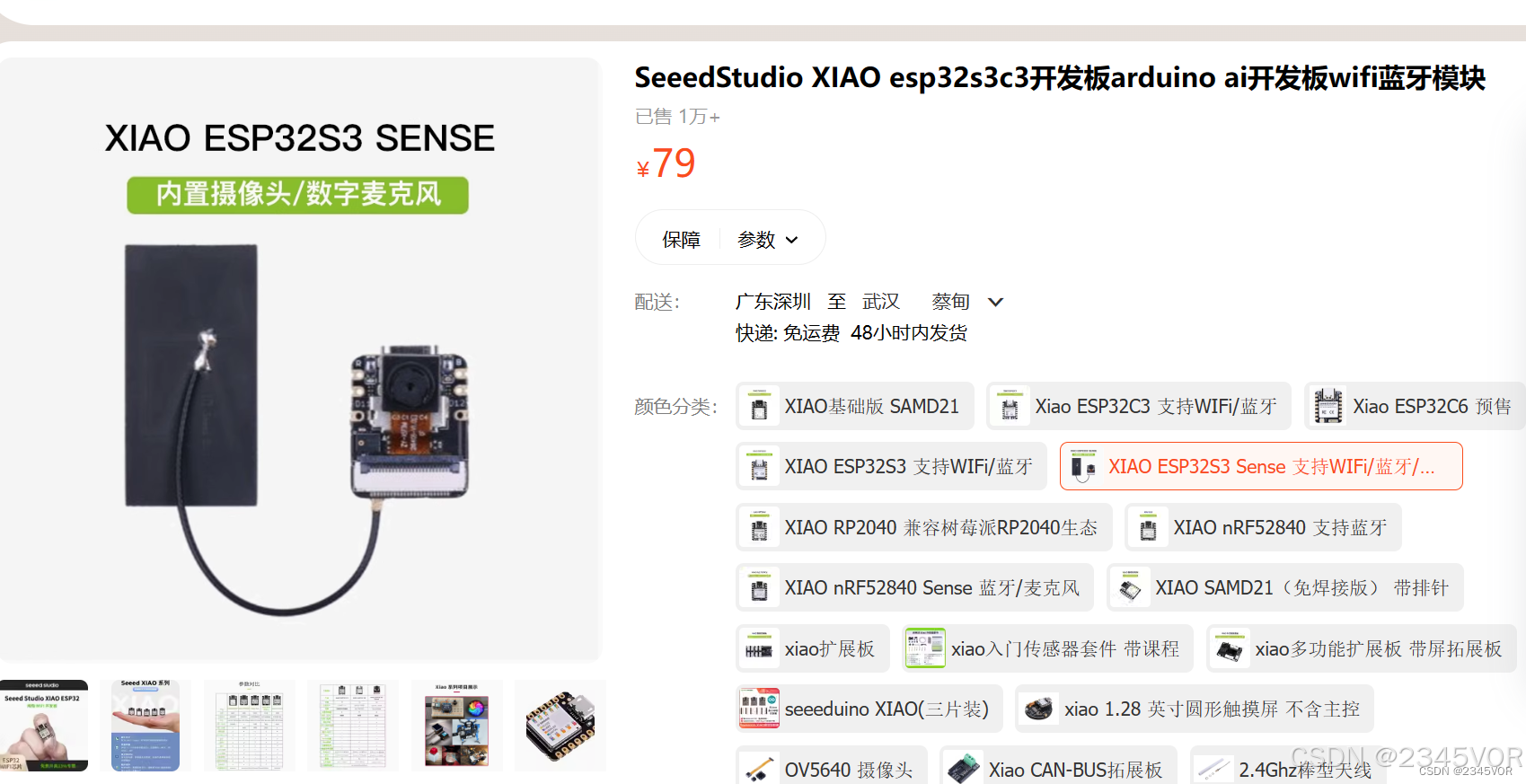

参考下面接线
INMP441 ESP32S3 I2S_WS GPIO17 I2S_SD GPIO3 I2S_SCK GPIO18 VCC 5V GND GND
语音听写(流式版)WebAPI 文档:https://www.xfyun.cn/doc/asr/voicedictation/API.html
语音听写流式接口,用于1分钟内的即时语音转文字技术,支持实时返回识别结果,达到一边上传音频一边获得识别文本的效果。
这里采用Platfromio框架接入,arduino IED也是可以的
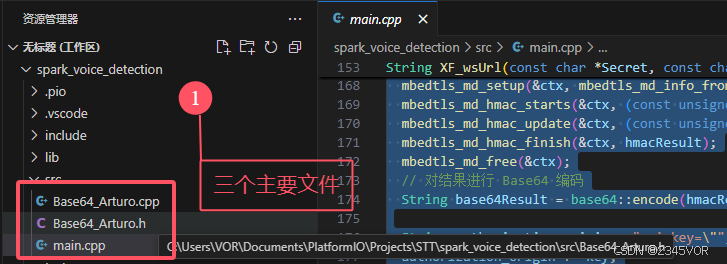
需要自己替换wifi和api参数
以下是该代码的简要功能介绍:
1. 核心功能
这是一个基于ESP32-S3的语音识别系统,主要实现:
- 通过麦克风录制音频(I2S接口)
- 连接讯飞开放平台进行语音转文字(STT)
- 网络时间同步(NTP)
- WS2812 LED状态指示
- 串口交互控制
2. 主要模块
- 硬件配置:
- WS2812 LED(GPIO48)
- I2S麦克风(GPIO17,3,18)
- WiFi网络连接
- 音频处理:
- 使用I2S接口采集音频数据
- 支持16kHz采样率、16位深PCM格式
- 可录制3秒音频(可调)
- 语音识别:
- 通过WebSocket连接讯飞语音识别服务
- 支持实时分段传输音频数据
- 采用Base64编码和HMAC-SHA256加密
- 网络服务:
- WiFi连接(2.4GHz)
- NTP网络时间同步
- HTTPS/WebSocket通信
- 交互控制:
- 通过串口发送’1’触发录音
- 实时返回识别结果到串口
- LED状态指示(当前未实现具体逻辑)
3. 工作流程
- 上电后连接WiFi和NTP服务器
- 初始化音频采集系统
- 等待串口输入’1’触发录音
- 录制3秒音频存入PSRAM
- 分段发送音频到讯飞云服务
- 接收识别结果并拼接成完整文本
- 通过串口输出识别结果
4. 典型应用场景
- 语音控制智能设备
- 语音备忘录系统
- 实时语音转文字设备
- IoT设备的语音交互接口
5. 关键技术点
- 低延迟音频采集:使用I2S DMA传输
- 大内存管理:采用PSRAM存储音频数据
- 安全通信:HMAC-SHA256签名验证
- 实时协议:WebSocket双向通信
- 语音分段处理:支持多数据包传输
6. 待完善功能
- LED状态指示逻辑
- 错误处理机制
- 本地音频缓存管理
- 离线语音识别支持
该代码实现了从硬件音频采集到云端语音识别的完整链路,可作为语音交互类IoT设备的基础框架。
参考以下烧录配置,
串口输入字符“1”文本,没有结束符点击按回车键,然后有3s录音时间。等待百度在线语音识别返回,在上一步的代码中实现了接收数据,这里列一下返回的数据。
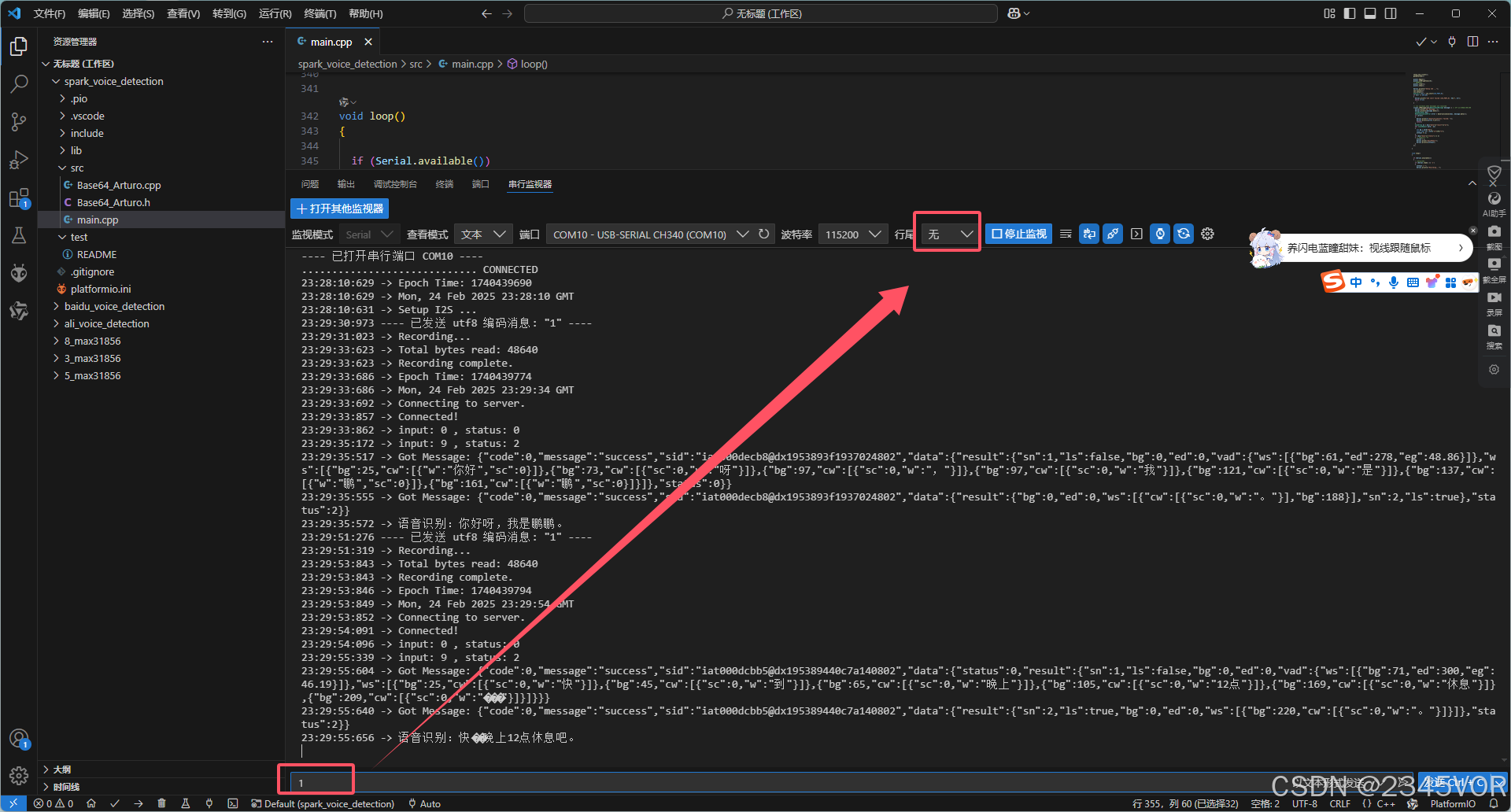
响应速度超级棒2s,数据发送成功则会返回正确的识别数据,当然声音信号不好时返回的语音识别也会不准确。
本文使用ESP32S3开发板接入讯飞实现在线语音识别。自带麦克风模块用做语音输入,通过串口发送字符“1”来控制数据的采集和上传。从而实现对外部世界进行感知,充分认识这个有机与无机的环境,科学地合理地进行创作和发挥效益,然后为人类社会发展贡献一点微薄之力。🤣🤣🤣
- 我会持续更新对应专栏博客,非常期待你的三连!!!🎉🎉🎉
- 如果鹏鹏有哪里说的不妥,还请大佬多多评论指教!!!👍👍👍
- 下面有我的🐧🐧🐧群推广,欢迎志同道合的朋友们加入,期待与你的思维碰撞😘😘😘
参考文献:ESP32直接对话大语言模型人工智能语音助手
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/223162.html