
开始陆续分享一些DeepSeek在数据挖掘和数据分析场景中辅助编程的案例!
DeepSeek V3和R1模型在编程方面能力不俗,参考权威的Aider LLM Leaderboards榜单我们发现,DeepSeek R1 取得了 56.9% 的成功率,格式正确率达到了 96.9%,而完整测试集的费用仅为 \(5.42,远低于其他竞争对手,。这意味着 DeepSeek 在提供高质量代码生成的同时,也能保持极高的性价比。DeepSeek Chat V3 虽然在成功率上低于 R1,仅为 48.4%,但格式正确率仍达到了 98.7%,并且其调用成本仅为 \)0.34,是榜单中最便宜的模型之一,适合对价格敏感的开发者使用。

DeepSeek对应数据分析师和数据科学家而言,其强大的编程能力可以极大提高其效率;而对非数据分析岗位的数据使用者而言,DeepSeek的编程能力将极大地扩充其数据分析能力的边界,解除编程能力门槛的限制。
今天我们介绍的案例是利用DeepSeek辅助编程,帮助我们进行探索性数据分析。
我们这里采用一个金融行业的数据集。数据及的详情如下所示:
Paysim 移动资金交易合成数据集。每一步代表模拟中的一个小时。该数据集是原始数据集的 1⁄4 缩略版,原始数据集在论文《PaySim: A financial mobile money simulator for fraud detection》(PaySim:用于欺诈检测的金融移动资金模拟器)中提出。
● step:映射现实世界中的一个时间单位。在本数据集中,1 步代表 1 小时。
● type:交易类型。包括:存款 (CASH-IN)、取款 (CASH-OUT)、扣款 (DEBIT)、支付 (PAYMENT) 和 转账 (TRANSFER)。
● amount:交易金额(以本地货币计)。
● nameOrig:发起交易的客户 ID。
● oldbalanceOrg:交易前的初始余额。
● newbalanceOrig:交易后的客户余额。
● nameDest:交易的收款方 ID。
● isFraud:欺诈交易标识。标识一笔交易是否为欺诈交易:
○ 1:表示该交易是欺诈交易。
○ 0:表示该交易是正常(非欺诈)交易。
由于DeepSeek对上传文件大小有限制(不超过50M),如果我们的数据集过大,我们可以先在原始数据集中截取一个相对较小(比如1000行左右)的数据集上传,让其了解数据结构和数据模式。然后我们输入prompt.

我们采取RTGO提示词模型编写提示词
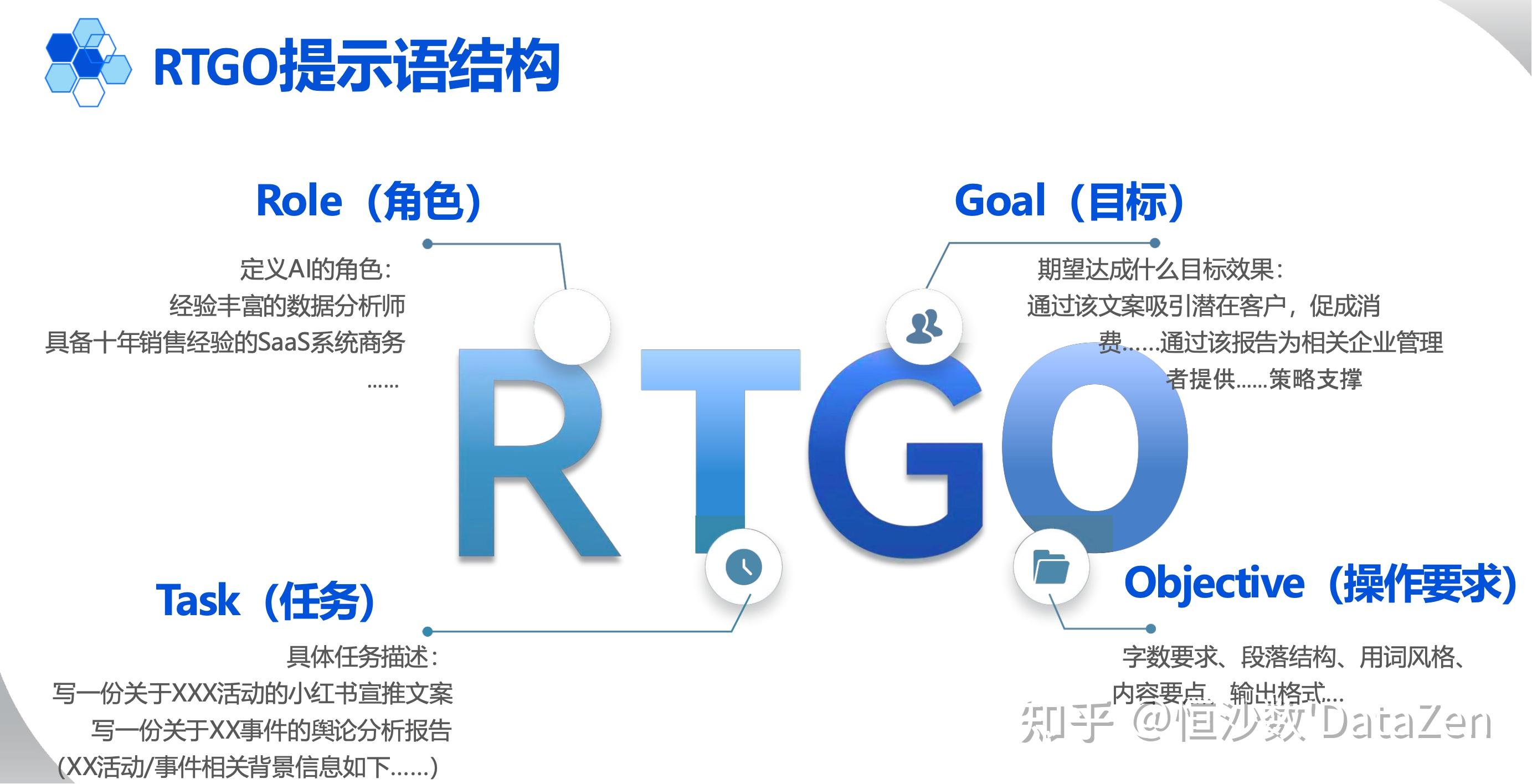
prompt方案如下:
<角色>
你现在是一名金融领域的数据科学家,擅长从复杂的金融交易数据中挖掘出模式;擅长使用Python和各种算法进行数据挖掘
<目标>
基于我给与你的数据集,写出探索性数据分析的python代码,旨在找到从所给数据集中发现欺诈交易的影响因素及模式。
数据集字段如下:
●step:映射现实世界中的一个时间单位。在本数据集中,1 步代表 1 小时。
●type:交易类型。包括:存款 (CASH-IN)、取款 (CASH-OUT)、扣款 (DEBIT)、支付 (PAYMENT) 和 转账 (TRANSFER)。
●amount:交易金额(以本地货币计)。
●nameOrig:发起交易的客户 ID。
●oldbalanceOrg:交易前的初始余额。
●newbalanceOrig:交易后的客户余额。
●nameDest:交易的收款方 ID。
●isFraud:欺诈交易标识。标识一笔交易是否为欺诈交易:
○1:表示该交易是欺诈交易。
○0:表示该交易是正常(非欺诈)交易。
<任务>
1.请基于发现交易欺诈影响因素的目的,找到探索性数据分析的方法、思路和维度
2.包括但不限于:单维度探索性分析、重点维度交叉分析
3.写出探索性数据分析的python完整代码
<操作要求>
1.尽量用合适的图表来得出数据结论
2.请根据如下原则考虑图表配色:
主色调:#O14EB8、#33C9FC、#OE84F2(蓝色系)用于图表主系列区分。
对比色:#f5d63b(黄色)、#D44206(红色)用于强调。
背景色:#f4f4f9(浅灰色)确保页面简洁清晰。
3.图表中的所有的数字或者百分比都保留1位小数
4.图表类型的选择严格参考如下原则:
(1)考察单维度结构的时候用饼图,
(2)单维度比较的时候用柱状图
(3)多维度结构比较的时候用百分比堆积图
(4)考察趋势的时候用折线图,如果需要在同一张图中同时表达量级和比例的变化趋势,则用双轴柱线图
(5)表达两个变量关系的时候用散点图
5.标题、图例、标签等图表要素要齐全,保障中文标签正常显示
6.保证代码可执行。
在这个prompt方案中,我们考虑了给与DeepSeek一些背景信息(如上文中对数据集的描述),而且我们对于图表进行了详细的限制要求。为了保证代码质量,我们选择深度思考R1模型。
思考了若干分钟之后,DeepSeek返回给我们如下python代码:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from matplotlib.ticker import PercentFormatter# 设置全局样式 plt.rcParams[‘font.sans-serif’] = [‘SimHei’] # 解决中文显示问题 plt.rcParams[‘axes.unicode_minus’] = False # 解决负号显示问题
# 定义配色方案 colors = [‘#014EB8’, ‘#33C9FC’, ‘#0E84F2’] # 主色调(蓝色系) highlight_colors = [‘#f5d63b’, ‘#D44206’] # 强调色(黄/红) bg_color = ‘#f4f4f9’ # 背景色
# 加载数据 df = pd.read_excel(‘简版数据集.xlsx’, sheet_name=‘Sheet1’)
# 1. 基础数据探索 print(f“数据集形状: {df.shape}”) print(f“欺诈交易占比: {df[‘isFraud’].mean():.1%}”) print(“\n数据类型分布:”) print(df[‘type’].value_counts(normalize=True).apply(lambda x: f“{x:.1%}”))
# 2. 单变量分析 def plot_univariate():
fig, axes = plt.subplots(2, 2, figsize=(16, 12)) fig.set_facecolor(bg_color) # 欺诈交易比例(饼图) fraud_perc = df['isFraud'].value_counts(normalize=True) axes[0, 0].pie(fraud_perc, labels=['正常', '欺诈'], autopct='%1.1f%%', colors=[colors[0], highlight_colors[1]], startangle=90) axes[0, 0].set_title('欺诈交易比例分布', fontsize=14) # 交易类型分布(柱状图) type_counts = df['type'].value_counts() sns.barplot(x=type_counts.index, y=type_counts.values, ax=axes[0, 1], palette=colors) axes[0, 1].set_title('交易类型分布', fontsize=14) axes[0, 1].set_ylabel('交易数量') axes[0, 1].yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{x/1000:.1f}k')) # 交易金额分布(箱线图) sns.boxplot(x='isFraud', y='amount', data=df, ax=axes[1, 0], palette=[colors[0], highlight_colors[1]], showfliers=False) axes[1, 0].set_title('欺诈交易金额分布', fontsize=14) axes[1, 0].set_xticklabels(['正常', '欺诈']) axes[1, 0].set_ylabel('交易金额') # 余额变化分布(直方图) df['balance_change'] = df['oldbalanceOrg'] - df['newbalanceOrig'] sns.histplot(data=df[df['balance_change'] > 0], x='balance_change', hue='isFraud', ax=axes[1, 1], bins=50, kde=True, element='step', palette=[colors[0], highlight_colors[1]], log_scale=True) axes[1, 1].set_title('账户余额变化分布(对数尺度)', fontsize=14) axes[1, 1].set_xlabel('余额变化值') plt.tight_layout() plt.savefig('univariate_analysis.png', dpi=300, bbox_inches='tight') plt.show() # 3. 多变量交叉分析 def plot_multivariate():
fig, axes = plt.subplots(2, 2, figsize=(16, 12)) fig.set_facecolor(bg_color) # 交易类型与欺诈率(百分比堆积柱状图) type_fraud = pd.crosstab(df['type'], df['isFraud'], normalize='index') * 100 type_fraud.plot(kind='bar', stacked=True, ax=axes[0, 0], color=[colors[0], highlight_colors[1]]) axes[0, 0].set_title('各交易类型欺诈率', fontsize=14) axes[0, 0].set_ylabel('比例(%)') axes[0, 0].legend(['正常', '欺诈'], title='交易状态') axes[0, 0].yaxis.set_major_formatter(PercentFormatter(100)) # 交易金额与欺诈关系(散点图) sample_df = df.sample(2000) # 抽样避免过度拥挤 sns.scatterplot(data=sample_df, x='amount', y='balance_change', hue='isFraud', ax=axes[0, 1], palette=[colors[0], highlight_colors[1]], alpha=0.7) axes[0, 1].set_title('交易金额与余额变化关系', fontsize=14) axes[0, 1].set_ylabel('余额变化') axes[0, 1].set_xscale('log') axes[0, 1].set_yscale('log') # 时间步长与欺诈率(双轴柱线图) step_fraud = df.groupby('step')['isFraud'].agg(['count', 'mean']) ax2 = axes[1, 0].twinx() sns.lineplot(x=step_fraud.index, y=step_fraud['mean'], ax=ax2, color=highlight_colors[1], linewidth=2.5) sns.barplot(x=step_fraud.index, y=step_fraud['count'], ax=axes[1, 0], color=colors[0], alpha=0.7) axes[1, 0].set_title('时间步长(小时)与交易量/欺诈率', fontsize=14) axes[1, 0].set_xlabel('时间步长(小时)') axes[1, 0].set_ylabel('交易量') ax2.set_ylabel('欺诈率', color=highlight_colors[1]) ax2.tick_params(axis='y', labelcolor=highlight_colors[1]) ax2.yaxis.set_major_formatter(PercentFormatter(1.0)) # 欺诈交易模式分析(热力图) fraud_df = df[df['isFraud'] == 1] fraud_corr = fraud_df[['amount', 'oldbalanceOrg', 'newbalanceOrig', 'balance_change']].corr() mask = np.triu(np.ones_like(fraud_corr, dtype=bool)) sns.heatmap(fraud_corr, annot=True, fmt=".2f", cmap='coolwarm', ax=axes[1, 1], mask=mask, cbar_kws={'label': '相关系数'}) axes[1, 1].set_title('欺诈交易特征相关性', fontsize=14) plt.tight_layout() plt.savefig('multivariate_analysis.png', dpi=300, bbox_inches='tight') plt.show() # 4. 高级模式分析 def plot_patterns():
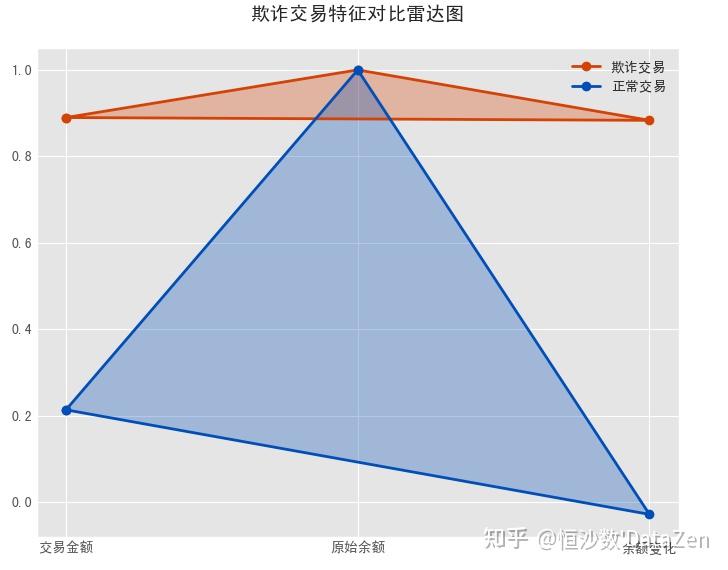
plt.figure(figsize=(14, 6)) # 欺诈交易的时间模式 fraud_hours = df[df['isFraud'] == 1]['step'].value_counts().sort_index() plt.subplot(121) sns.lineplot(data=fraud_hours, color=highlight_colors[1], linewidth=2.5) plt.fill_between(fraud_hours.index, fraud_hours.values, alpha=0.3, color=highlight_colors[1]) plt.title('欺诈交易时间分布模式', fontsize=14) plt.xlabel('时间步长(小时)') plt.ylabel('欺诈交易数量') fraud_df = df[df['isFraud'] == 1] # 欺诈交易特征雷达图(简化版) plt.subplot(122) fraud_features = fraud_df[['amount', 'oldbalanceOrg', 'balance_change']].mean() normal_features = df[df['isFraud'] == 0][['amount', 'oldbalanceOrg', 'balance_change']].mean() # 归一化 fraud_norm = fraud_features / fraud_features.max() normal_norm = normal_features / normal_features.max() angles = np.linspace(0, 2*np.pi, len(fraud_features), endpoint=False).tolist() angles += angles[:1] # 闭合 fraud_norm = list(fraud_norm) fraud_norm += fraud_norm[:1] normal_norm = list(normal_norm) normal_norm += normal_norm[:1] plt.polar(angles, fraud_norm, 'o-', color=highlight_colors[1], linewidth=2, label='欺诈交易') plt.polar(angles, normal_norm, 'o-', color=colors[0], linewidth=2, label='正常交易') plt.fill(angles, fraud_norm, alpha=0.3, color=highlight_colors[1]) plt.fill(angles, normal_norm, alpha=0.3, color=colors[0]) plt.xticks(angles[:-1], ['交易金额', '原始余额', '余额变化']) plt.title('欺诈交易特征对比雷达图', fontsize=14, pad=20) plt.legend(loc='upper right') plt.tight_layout() plt.savefig('fraud_patterns.png', dpi=300, bbox_inches='tight') plt.show() # 执行分析 plot_univariate() plot_multivariate() plot_patterns()
代码主体分为4个部分:
首先是读取数据和数据集的初步探索,值得一提的是,由于我们再提问的时候,提供的是简化的数据集,因此我们需要对读入数据集的代码略微进行修改。
原代码为:
# 加载数据 df = pd.read_excel(‘简版数据集.xlsx’, sheet_name=‘Sheet1’)我们这里需要改成:
# 加载数据 df = pd.read_csv(“金融数据.csv”)
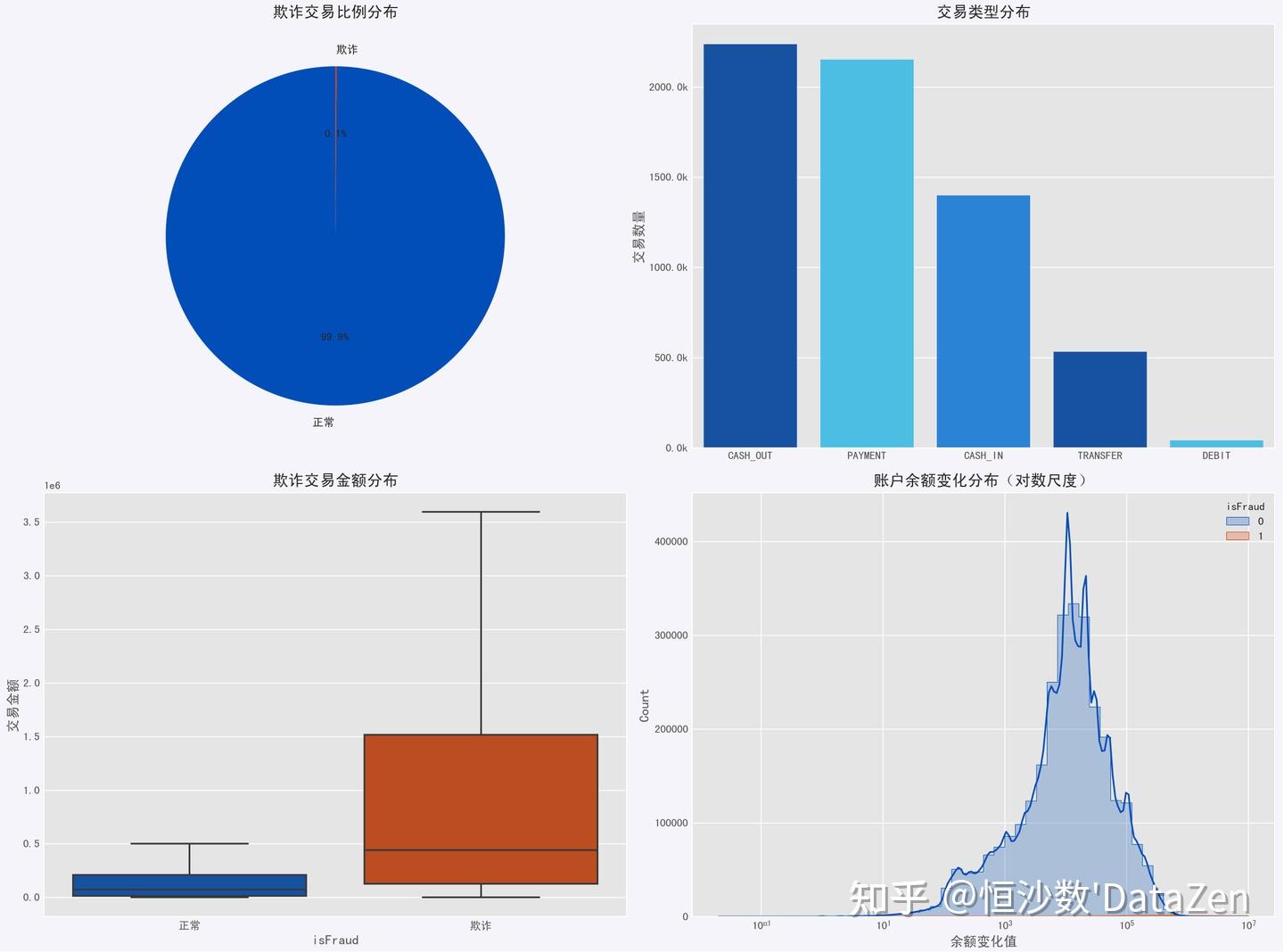
运行代码我们得到我们数据集的形状以及数据类型的分布,欺诈交易仅占0.1%。
第二步和第三步是写出单变量分析和多遍量分析的函数:
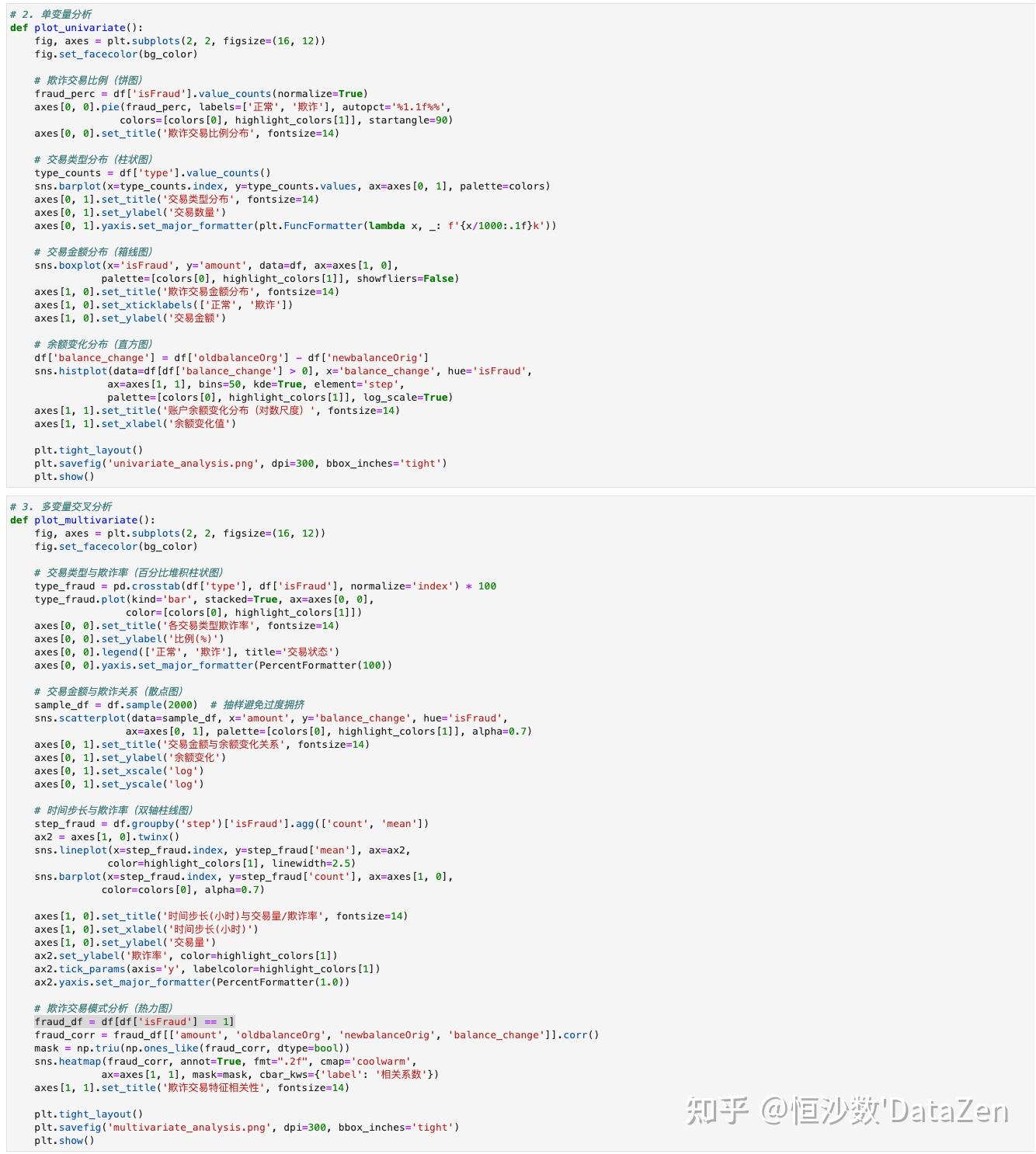
第四步是输出函数和模式

我们运行和调试代码之后,就会输出相关图表和结论了:
以下是单因素分析的图表,我们从下图可以发现,欺诈交易一般金额较高。
以下是多因素分析图表,我们从图2可以看出,一般欺诈交易的总金额和金额变化都较大;图3可以发现欺诈交易一般相对密集发生。
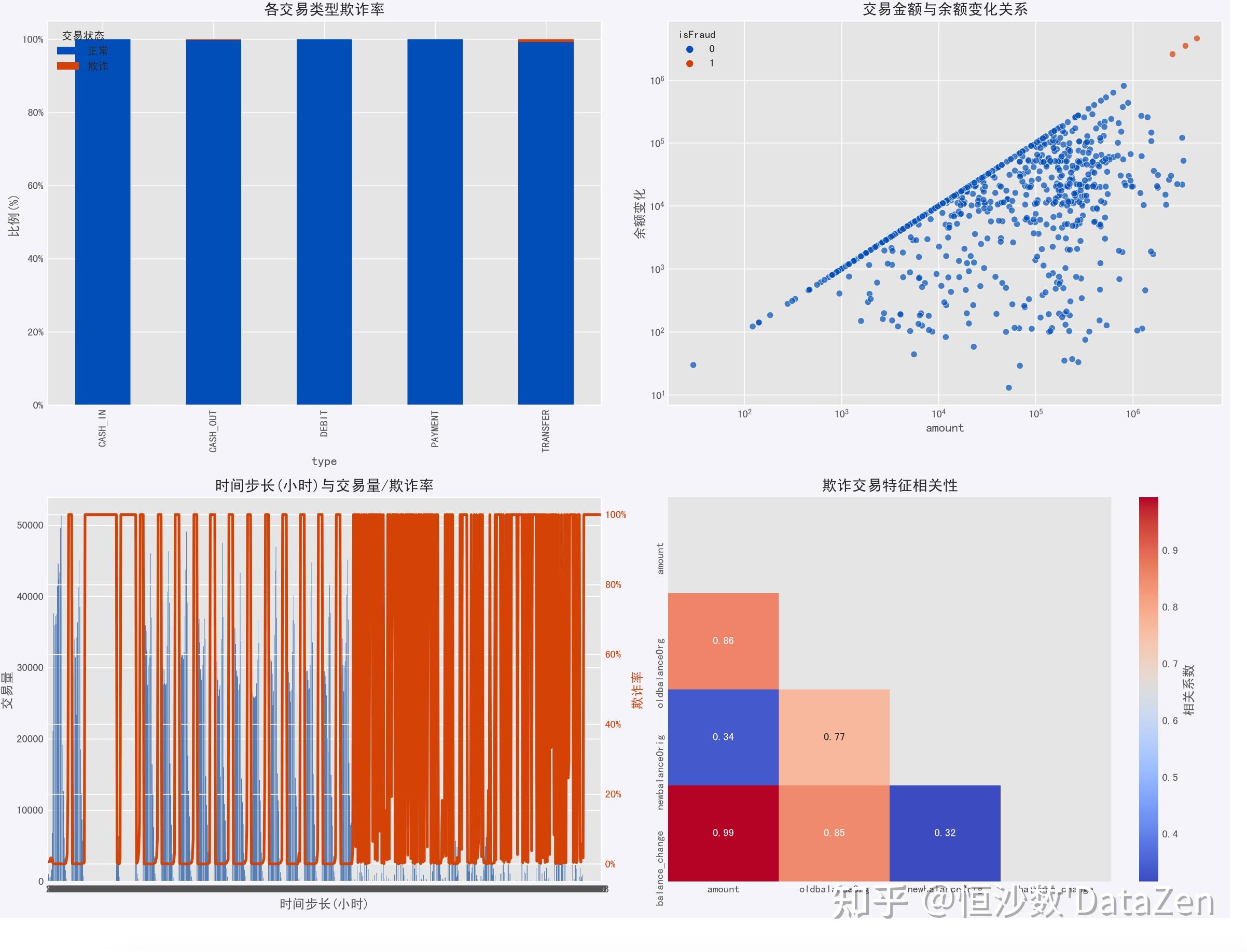
以下是模式总结,欺诈交易一般交易金额、原始余额,和余额变化都较大,而正常交易一般原始余额大,交易金额和余额变化较小
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/223105.html