
在开始之前,首先要进入平台的控制台中创建一个应用,获取到apppid、appkey等。
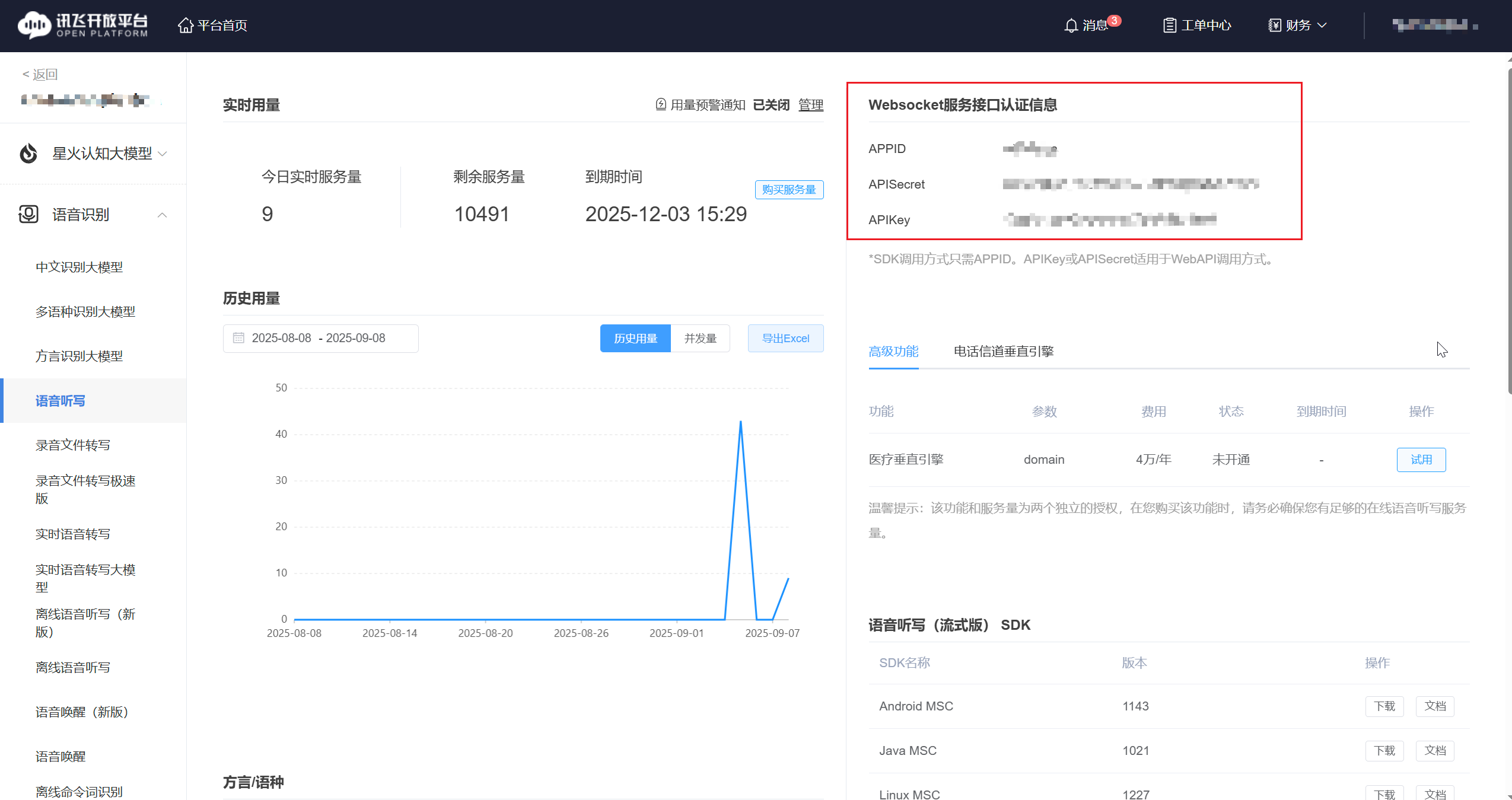
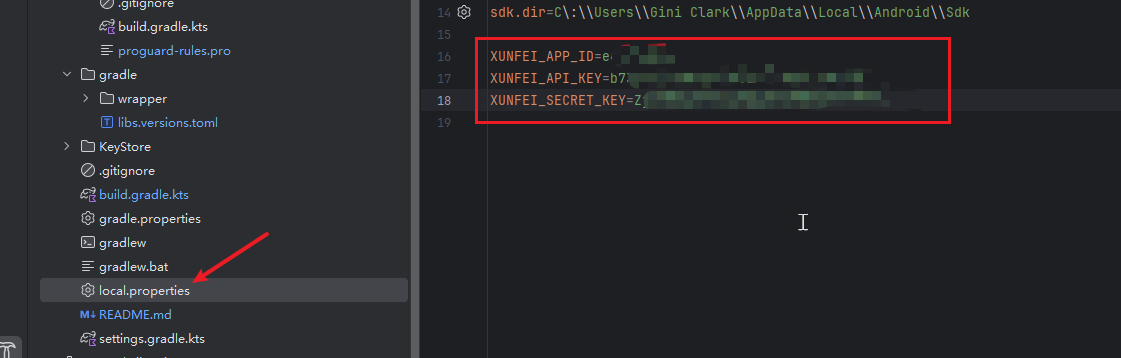
我是将对应的密钥放到了local.properties文件中,你们也可以放入到这里。
也可以不放在local.properties文件中,直接放置在对应的的方法中,可以省略这一步骤。
在app目录下的build.gradle文件中也进行配置

在其他文件中就可以通过BuildConfig中进行引用了
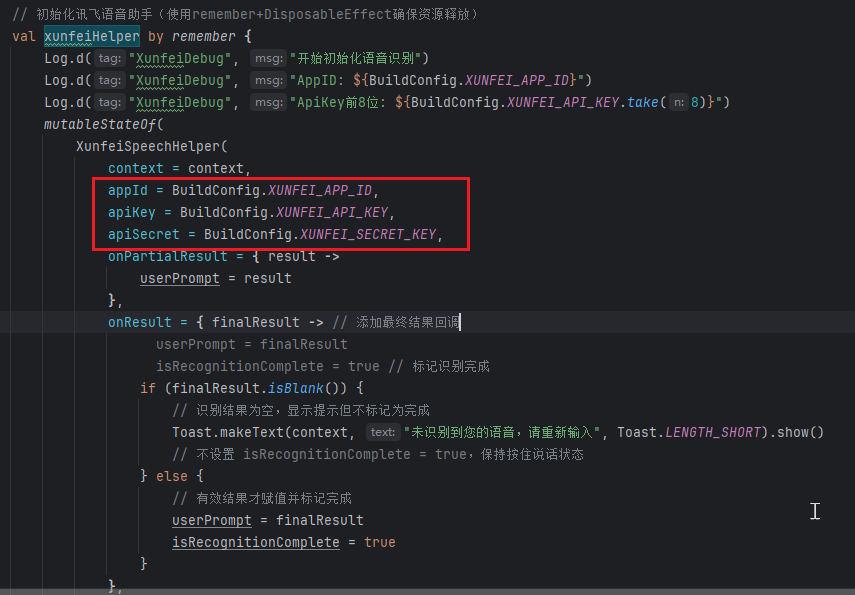
注意,若无法通过BuildConfig获取到配置,记得查看是否构建完成,可以在BuildConfig文件中进行查看
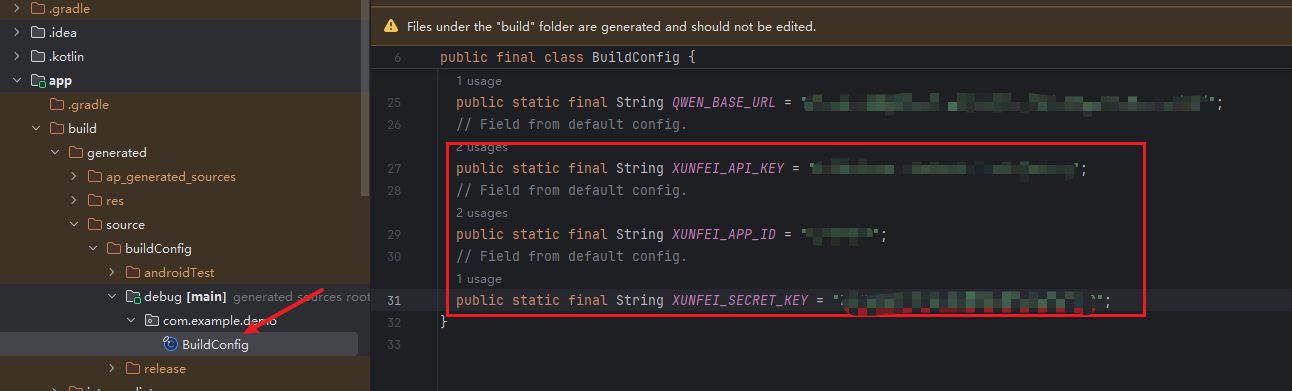
密钥配置完成后。
进入讯飞开放平台文档中心,然后点击SDK下载
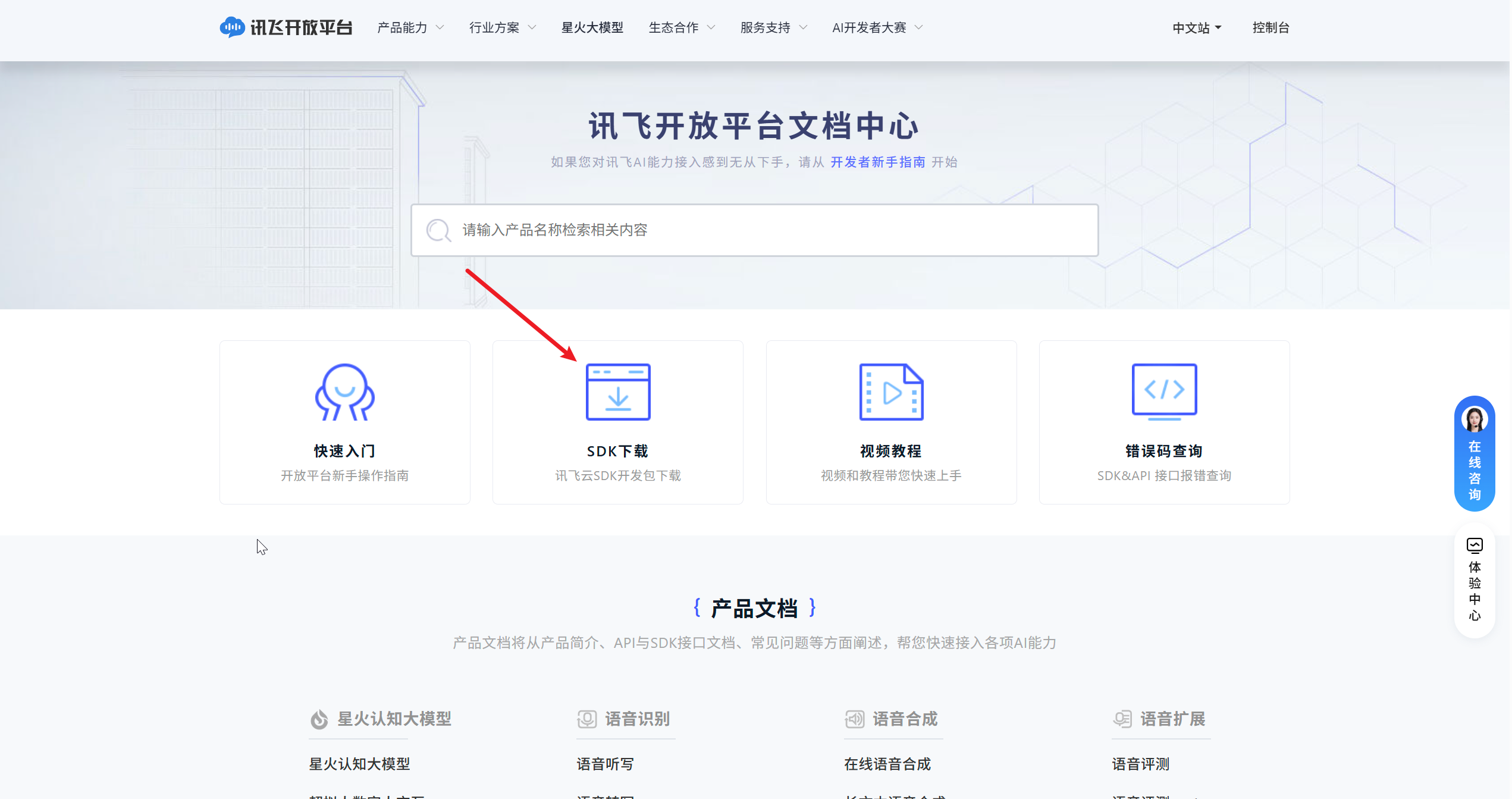
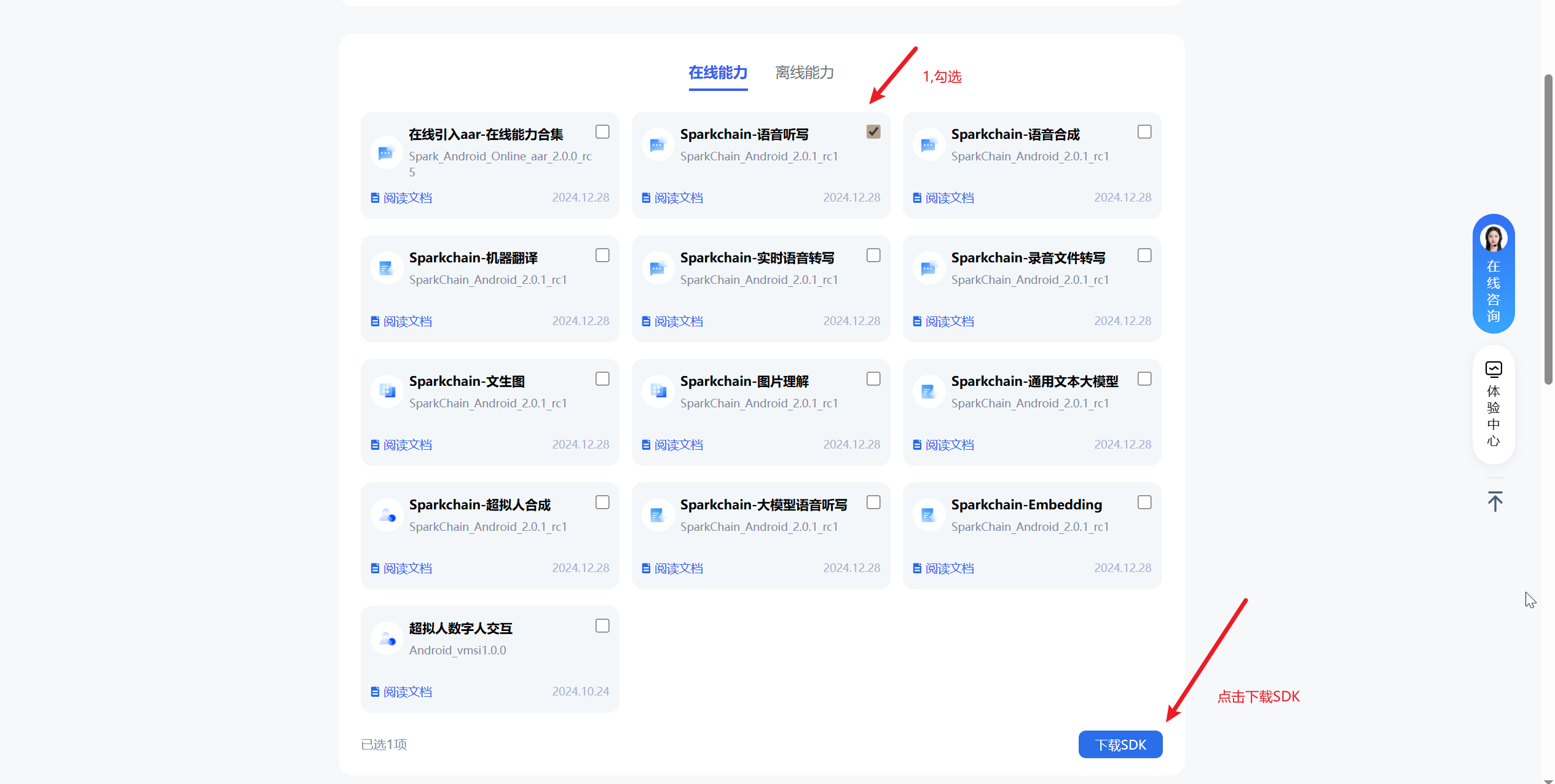
因为我只需要在我的软件中接入语音识别功能,所以我勾选的是语音听写,然后点击下载该SDK。
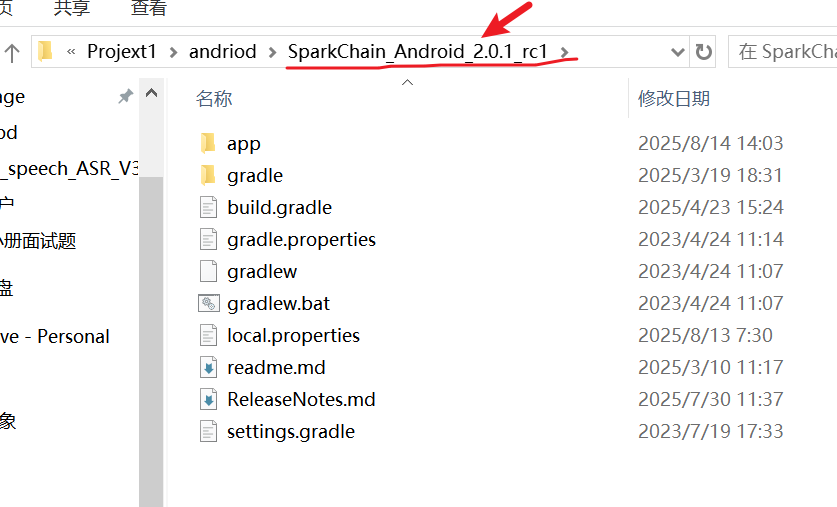
下载完成后,直接解压,你就会得到以下文件。
4.1 导入SDK库
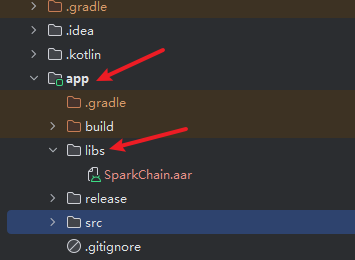
然后在主Module的build.gradle文件中,增加如下配置:
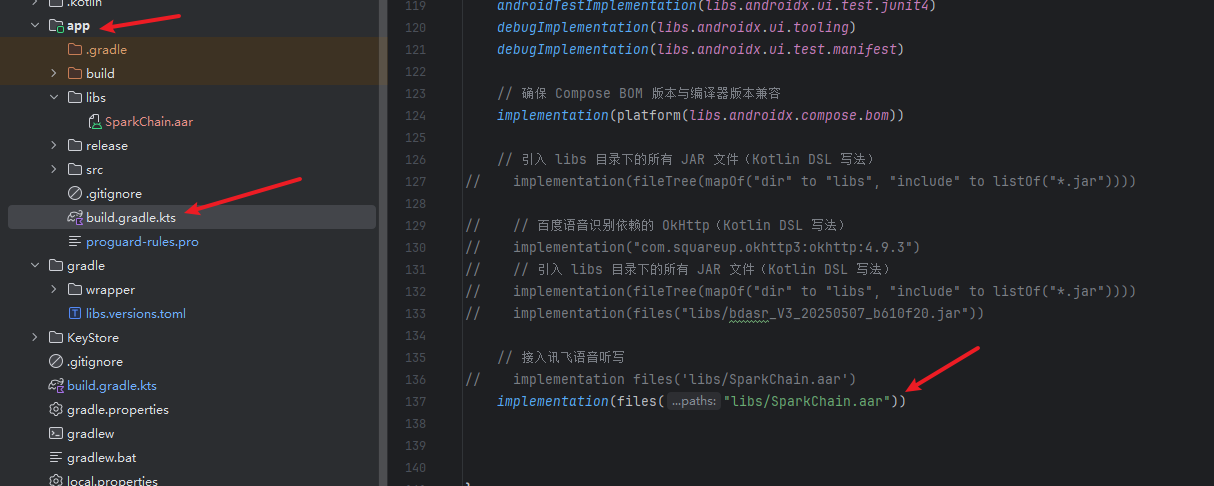
注意:是在app目录下的build.gradle文件。
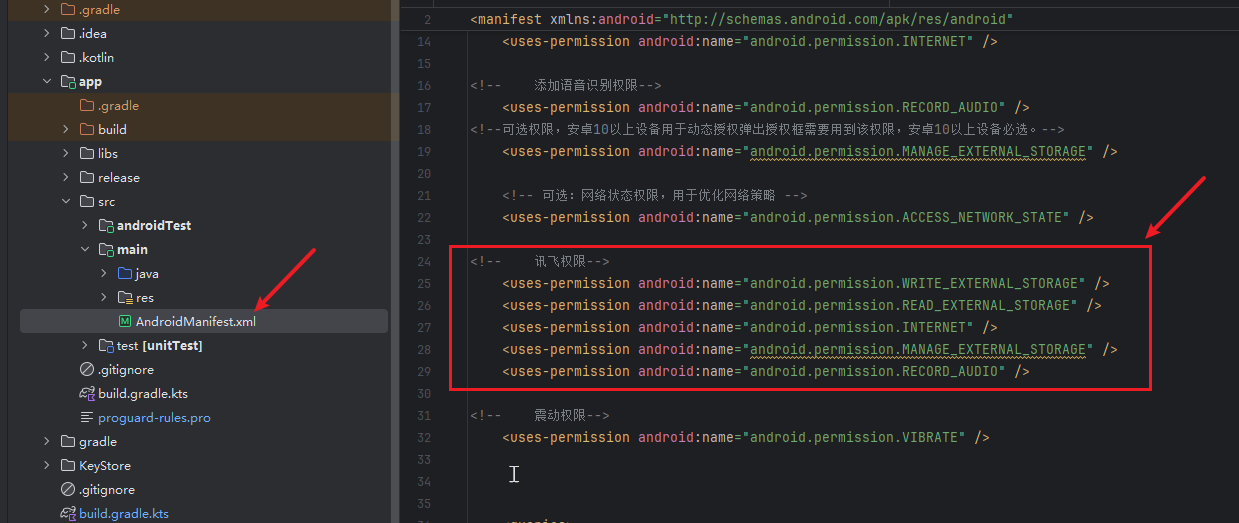
4.2 配置权限
外部使用时需要配置以下权限:
在app/src/main文件夹下的AndroidManifest.xml文件中进行权限配置。
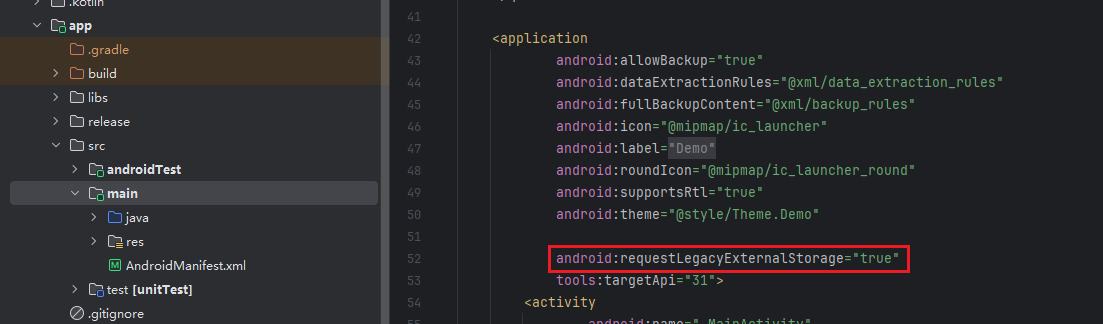
如果部分权限不需要,可通过如下配置去除,去除示例如下:
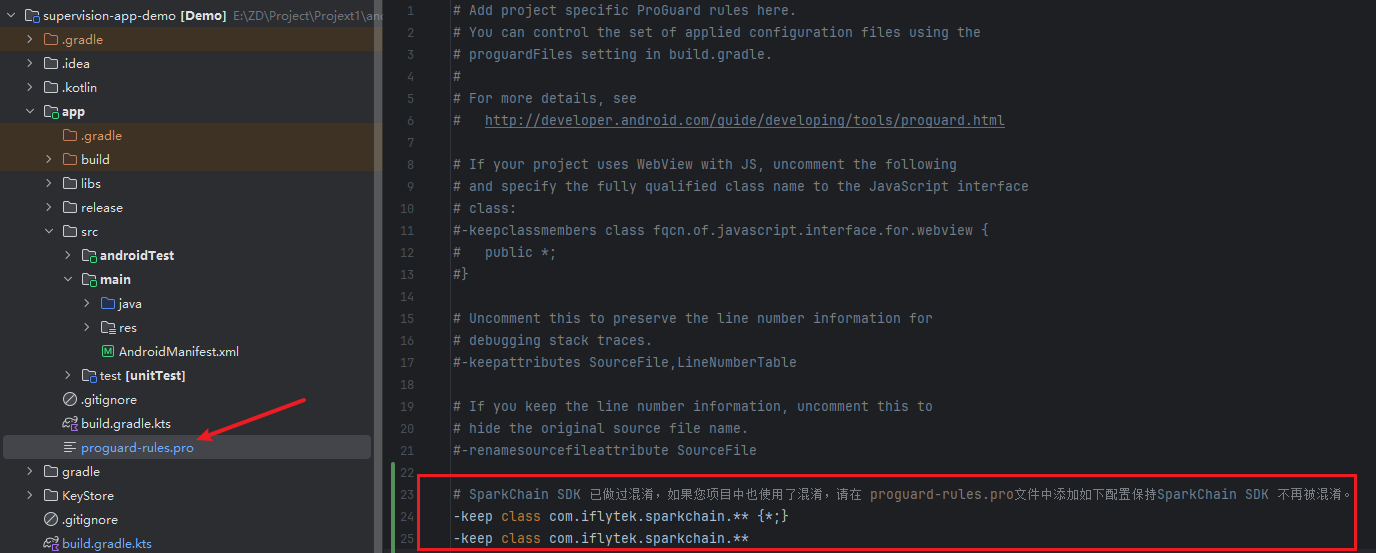
4.3 混淆配置
SparkChain SDK 已做过混淆,如果您项目中也使用了混淆,请在 proguard-rules.pro文件中添加如下配置保持SparkChain SDK 不再被混淆。
配置完成了,接下来就可以正式开始代码编写了,我是写了两个工具类。
为了便于在项目中使用讯飞语音识别功能,我创建了两个核心工具类。
分别是音频录制管理器 - AudioRecorderManager和讯飞语音识别助手 - XunfeiSpeechHelper
5.1 音频录制管理器 - AudioRecorderManager
5.1.1 类定义和导包
首先创建AudioRecorderManager类,用于处理录音功能:
这里我们定义了音频录制的关键参数:
- sampleRateInHz: 采样率设为16000Hz,这是讯飞语音识别推荐的采样率
- audioFormat: 使用16位PCM编码,保证音频质量
- channels: 单声道录音,减少数据量并满足语音识别需求
5.1.2 单例模式实现
采用线程安全的懒加载单例模式:
- @Volatile: 确保instance变量在多线程环境下的可见性
- 双重检查锁定: 避免重复创建实例,提升性能
- 单例优势: 全局唯一录音管理器,避免资源冲突
5.1.3 核心成员变量
变量说明:
- bufferSize: 根据系统推荐计算得出的**缓冲区大小
- isStart: 使用AtomicBoolean保证多线程安全的状态管理
- recordThread: 独立线程处理录音,避免阻塞主线程
5.1.4 初始化代码块
初始化流程:
- 计算缓冲区大小: 使用系统API获取**缓冲区大小
- 创建AudioRecord: 配置音频录制参数
- 异常处理: 捕获创建失败的情况并记录日志
5.1.5 核心录音方法
启动录音方法:
停止录音方法:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/220621.html