
自从DeepSeek火遍大江南北,人人都在使用大模型,也有很多同志在像晓智同学一样,开始私有化部署。
当然选择私有化部署使用最多的是ollama部署,但是对于并发相对高的场景,vllm是非常不错的选择。现就将晓智同学一步步部署并成功上线实施的方案分享如下:

1、安装ubuntu24.04操作系统,并安装对应的基础软件,比如输入法等(可以不安装)。
2、安装显卡驱动
- 检查显卡驱动是否已经识别,如果已经识别,则不需要安装:以下表示已经识别
root@admin-Legion-Y9000P-IRX9:/home/admin/下载# lspci | grep -i nvidia01:00.0 VGA compatible controller: NVIDIA Corporation AD107M GeForce RTX 4060 Max-Q / Mobile01:00.1 Audio device: NVIDIA Corporation Device 22be (rev a1)- buntu 24.04可能默认使用开源驱动(
nouveau),需手动安装闭源驱动:
sudo apt updatesudo ubuntu-drivers autoinstall # 自动安装推荐驱动- 禁用开源驱动(nouveau)
sudo nano /etc/modprobe.d/blacklist-nouveau.conf添加以下内容
blacklist nouveauoptions nouveau modeset=0- 更新initramfs并重启:
sudo update-initramfs -usudo reboot- 验证GPU工作状态(已正常工作)
admin@admin-Legion-Y9000P-IRX9:/桌面$ nvidia-smiTue Apr 1 13:31:53 2025 +—————————————————————————————–+| NVIDIA-SMI 550.120 Driver Version: 550.120 CUDA Version: 12.4 ||—————————————–+————————+———————-+| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. || | | MIG M. ||=========================================+========================+======================|| 0 NVIDIA GeForce RTX 4060 … Off | 00000000:01:00.0 Off | N/A || N/A 37C P0 588W / 55W | 9MiB / 8188MiB | 0% Default || | | N/A |+—————————————–+————————+———————-+ +—————————————————————————————–+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=========================================================================================|| 0 N/A N/A 2471 G /usr/lib/xorg/Xorg 4MiB |+—————————————————————————————–+- 使用conda环境隔离安装部署
1、下载并安装conda环境
- 下载 Miniconda 安装脚本:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh admin@admin-Legion-Y9000P-IRX9:/桌面\( wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh--2025-05-01 13:47:13-- https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh正在解析主机 repo.anaconda.com (repo.anaconda.com)... 104.16.191.158, 104.16.32.241, 2606:4700::6810:20f1, ...正在连接 repo.anaconda.com (repo.anaconda.com)|104.16.191.158|:443... 已连接。已发出 HTTP 请求,正在等待回应... 200 OK长度: (147M) [application/octet-stream]正在保存至: ‘Miniconda3-latest-Linux-x86_64.sh’- 运行安装脚本:
bash Miniconda3-latest-Linux-x86_64.sh- 按照提示完成安装,然后重新打开终端,Conda 就可以正常使用了
2、创建一个新的 conda 环境
以后所有的模型相关操作都将在该conda(myenv)环境中运行。
conda create -n myenv python=3.10 -y- 根据提示,进行conda升级(可选)
(base) admin@admin-Legion-Y9000P-IRX9:~\) conda update -n base -c defaults condaChannels: - defaultsPlatform: linux-64Collecting package metadata (repodata.json): doneSolving environment: done- 激活虚拟环境
conda activate myenv- 安装带有 CUDA 12.1 的 vLLM
pip install vllm
1、模型下载
下载 DeepSeek 模型,此处下载deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 模型
- 模型地址: DeepSeek-R1-Distill-Qwen-7B
- 安装 ModelScope 包: ModelScope 是一个模型中心,我们使用它来下载模型。在终端或命令提示符中执行以下命令安装 ModelScope Python 包:
pip install modelscope- 下载模型: 使用
modelscope download命令下载模型。
modelscope download –model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B –local_dir /home/xhq/deepseek-7b–model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B: 指定要下载的模型为 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B。
- –local_dir your_local_path: 指定模型下载后保存的本地路径。请将 your_local_path 替换为您电脑上实际想要保存模型的路径。 例如,如果您想将模型保存在 /home/user/models/deepseek-7b 目录下,则命令应为:
- 关于 ModelScope: ModelScope 是一个模型即服务的开源社区,您可以在上面找到各种预训练模型。您可能需要注册 ModelScope 账号才能下载某些模型,但 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 模型目前是公开的,可以直接下载。
2、模型运行
在conda环境(myenv) admin@admin-Legion-Y9000P-IRX9:~中,进入模型所在的目录,运行以下命令vllm serve DeepSeek-R1-Distill-Qwen-1.5B \ –max-model-len 4096 \ –gpu-memory-utilization 0.7 \ –max-num-batched-tokens 1024 \ –max-num-seqs 4 \ –port 8000 \ –tensor-parallel-size 1 \ –trust-remote-code
/path/to/De
- epSeek-R1-Distill-Qwen-7B:替换为实际的模型路径。
- –max-model-len:设置
- 模型的最大输入长度。
- –port:设置API的端口号。
- –tensor-parallel-size:设置张量并行的GPU数量。
- –trust-remote-code:信任远程代码,用于加载模型。
3、调用 vLLM 推理服务
- 以下是postman调用示vllm推理服务示例:
url:http://localhost:8000/v/completionsheaders: Content-Type:application/jsonbody:{ “model”: “DeepSeek-R1-Distill-Qwen-1.5B”, “prompt”: “你是谁”, “max_tokens”: 1024, “temperature”: 0.7, “stream”:true}到这里整个过程就完成了,可以通过dify等应用构建平台对接本地大模型并编排应用。
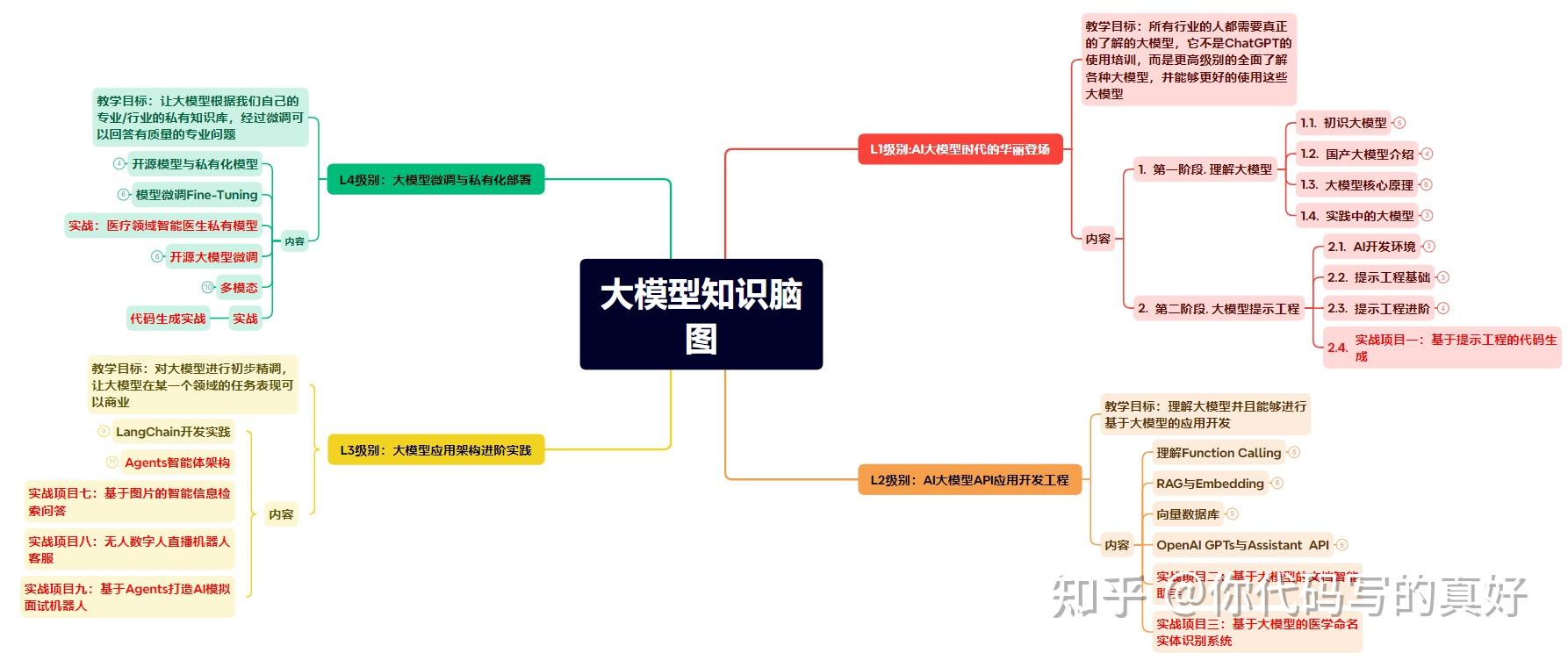
为了帮助开发者打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料。这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
yyds!全网独一份的AI大模型学习教程资源!!为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- ….
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- ….
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- ….
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/219362.html