
OpenClaw 是一个本地智能体平台,可以运行在用户自己的设备上,比如笔记本电脑、一台云服务器、机柜里的 Mac Mini,或者一个云容器,甚至树莓派等轻设备。
它把 大模型和各种工具集成到智能体中,并支持连接到日常用的聊天 App,例如,WhatsApp、Telegram、飞书、钉钉等等。
而 OpenClaw 更像是给 AI 搭了一整套操作系统,一应俱全,有会话管理、有记忆系统、有工具权限控制、有消息路由。

GPT plus 代充 只需 145
它采用调度中心架构,就像一个信息调度中心,所有消息都经过一个中央塔台(Gateway 网关),由它分配到正确的通道(Agent)。其关键设计思想是: 把消息通信、接口层和AI 怎么思考和执行(Agent)彻底分开。
核心就两大模块:
- 网关(Gateway): WebSocket 服务器,连接各种聊天平台和控制界面,把收到的消息派发给 Agent 运行器处理。
- 智能体(Agent) :真正执行的核心引擎,组装上下文、调用 AI 模型、执行工具操作(比如浏览网页、操作文件、定时任务等)、保存状态。
OpenClaw 的整体工作结构可以抽象为一条清晰的控制与执行链路:
讯享网 │ ▼
┌───────────────────────────┐ │ Gateway 网关 │ ws://127.0.0.1:18789(仅 loopback) │ (统一入口) │ │ │ http://<gateway-host>:18793 │ │ /openclaw/canvas/(Canvas 主机) └───────────┬───────────────┘
│ ├─ Pi 智能体(RPC) ├─ CLI(电脑指令) ├─ 聊天 UI(SwiftUI) ├─ macOS 应用(OpenClaw.app) ├─ iOS 节点(Gateway WS + 配对) └─ Android 节点(Gateway WS + 配对)</code></pre></div><p data-pid="psY46WUA">所有消息首先进入 Gateway 网关,由其统一完成如下任务:</p><ul><li data-pid="5-0hwfEp">渠道协议适配</li><li data-pid="cA8ENChb">会话与上下文管理</li><li data-pid="D7C4qouO">RPC 调度至 Pi 智能体</li><li data-pid="ZW9LyCMM">响应回传</li></ul><p data-pid="BjpG0Au-">Gateway 是系统中的<b>单一事实源(Single Source of Truth)</b>。</p><figure data-size="normal"><img src="https://pic2.zhimg.com/v2-9029cddbb46cd1982f019b2ba39dfdcb_r.jpg" data-rawwidth="1473" data-rawheight="1151" data-size="normal" data-caption="" data-original-token="v2-83db11e6acd8a876b30569b51826e804" class="origin_image zh-lightbox-thumb" width="1473" data-original="https://pic2.zhimg.com/v2-9029cddbb46cd1982f019b2ba39dfdcb_r.jpg"/></figure><p data-pid="UZ6dS0o3">用户可以通过不同的IM软件(飞书、Whatsapp、Telegram等)发送消息给OpenClaw,其中每个IM软件都视为一个Channel。。</p><p data-pid="v0nvp-Ho">Channel中包含2个核心的组件:Monitor和Adapter。其中:</p><ul><li data-pid="nUY_5dIw">消息接收器Monitor:负责监听外部平台的Webhook或长轮询、校验请求权限(如 Line 的签名验证)、解析平台特定的消息格式、应用访问控制策略</li><li data-pid="dtracXde">消息发送器Adapter:负责将内部消息格式转换为平台特定格式、处理文本分块和媒体附件、发送失败重试和错误处理、执行平台特定操作(如 reactions、投票)</li></ul><p data-pid="M-GZmCSW">这两个组件在具体工作的时候,需要结合Gateway中的路由与消息总线来与Agent Runner通信:</p><ol><li data-pid="-b437B8w">Monitor 接收 Channel消息 → 解析平台消息 → 路由到 Agent Runner</li><li data-pid="eoxVRK89">Agent Runtime开始处理 → 生成回复 → 交给 Adapter</li><li data-pid="E8yDtUAo">Adapter 发送 → 转换格式 → 发送到Channel</li></ol><p data-pid="YNo5235M">Adapter并不是每个Channel只有一个单一的组件,它是一组Adapter分工来完成不同的事情,核心的Adapter有:</p><ul><li data-pid="soz_yEjh">ChannelOutboundAdapter - 处理出站消息发送,同时也负责将站内数据协议转换为Channel专属协议</li><li data-pid="dELACZLr">ChannelConfigAdapter - 管理平台配置</li><li data-pid="cGnQNJ5w">ChannelSecurityAdapter - 处理访问控制和安全策略</li><li data-pid="X4gGB9tF">ChannelGatewayAdapter - 管理与Gateway的集成</li><li data-pid="Ex-vDFut">ChannelMessagingAdapter - 处理目标地址规范化</li><li data-pid="oUlM8_Bi">ChannelThreadingAdapter - 处理消息回复和线程</li></ul><hr/><p data-pid="xsCyfRbe">Channel是基于不同IM的开放平台能力,让OpenClaw与不同的IM的开放平台服务通信。可以说Channel是针对不同的IM程序的适配器。相对的,Node则是针对iOS、Android、macOS这种操作系统的适配器。</p><p data-pid="6ttAeCG0">而Node则是一种实际运行在iOS、Android和macOS上的程序,并与运行在用户电脑上的OpenClaw主程序进行远程通信。用户将自己的设备的权限开放给Node,这样OpenClaw就可以通过Node来远程控制用户的设备,如执行任务,打开摄像头,屏幕截图,获取地理位置等。</p><blockquote data-pid="IxkYjiDT">接入不同IM的服务端,属于服务端到服务端的通信,安全且简单,但是OpenClaw与不同Node在公网上进行安全通信,就需要选择一些更复杂的技术。</blockquote><p data-pid="Nfba4Sry">此外还需要考虑Node与OpenClaw在建立连接时的注册问题。</p><p data-pid="X2bKtU_h">在Node的发现与注册方面,OpenClaw使用了如下技术:</p><ul><li data-pid="pRqL2UQI">mDNS/DNS-SD:一套服务发现的国际标准组合(RFC 6762/6763)。OpenClaw 利用其混合模式,在局域网(通过组播)或Tailnet 虚拟网(通过单播)中自动解析 Gateway 和 Node 的服务地址与端口,实现即插即用</li><li data-pid="69H4mQWN">Bonjour:苹果对mDNS和DNS-SD的打包实现</li><li data-pid="J6TDfduL">NsdManager:安卓对mDNS/DNS-SD的原生实现</li></ul><p data-pid="eTA6nzon">OpenClaw主要引入Tailnet来实现在局域网或者公网上进行安全访问校验:</p><ul><li data-pid="CNR-RZoW">Tailnet:一个去中心化传输的虚拟覆盖网络。OpenClaw基于此技术在公网环境中构建一个部署Gateway的主机与所有外围设备的私密的局域网,即便设备与Gateway在远程设备也能安全的互相通信。</li></ul><p data-pid="vvv2xRfv">基于上述的这些技术和方法,Gateway与Node之间的发现与链接的建立时序如下:</p><figure data-size="normal"><img src="https://pica.zhimg.com/v2-5fe282ef89a7012ea7f7bfbd27ffe86c_r.jpg" data-rawwidth="1080" data-rawheight="1152" data-size="normal" data-caption="" data-original-token="v2-930babc4366ed363eeae9df482cfda87" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pica.zhimg.com/v2-5fe282ef89a7012ea7f7bfbd27ffe86c_r.jpg"/></figure><p data-pid="mqbUrrjJ">Gateway WebSocket Server是一个绑定18789端口的,单进程的WebSocket Server,负责所有组件的调度与交互,管理不同的会话(Sessions),消息路由,定时任务管理,以及Agent调度。同时还要负责监控各Channel和Node的联通状况(health check)。</p><div class="highlight"><pre><code class="language-text"># 启动指令: openclaw gateway –port 18789
Gateway 是一个长期运行的守护进程。你启动一次,它就在那里待命。以下是你通过 Telegram 给你的机器人发消息时发生的事情:
- Gateway 维护着与 Telegram API 的持久连接。
- 一个事件进入。Gateway 检查配置:哪个 Agent 处理这个?它决定 SessionId:是旧对话的延续,还是新会话?
- Gateway 组装上下文:从 .jsonl 文件读取会话历史;从 Workspace 拉取 Bootstrap 文件;加入可用的技能。
- 整合好所有信息发送给 LLM。
- LLM 返回文本或工具调用(Tool Call)。
- 如果是工具调用,Gateway 则执行指令,将结果反馈给上下文,然后 LLM 进一步思考,可能进行文本生成生成或者再调用另一个工具。这个循环会一直流转(多次调大模型),直到得出最终答案。
- 响应流式传回 Telegram。整个交流被写入 .jsonl,同时更新 sessions.json。
OpenClaw Gateway使用HTTP 务器的升级机制来同时支持 HTTP和WebSocket。核心原理是:所有连接初始都是HTTP,通过upgrade事件将特定连接升级为WebSocket:
讯享网// Gateway 创建 HTTP 服务器并监听 upgrade 事件 const wss = new WebSocketServer({
noServer: true,
maxPayload: MAX_PAYLOAD_BYTES,
});
for (const server of httpServers) {
attachGatewayUpgradeHandler({ httpServer: server, wss, canvasHost });
}
- peer匹配 - 精确的DM/群组/频道ID
- guild匹配 - Discord服务器ID
- team匹配 - Slack团队ID
- account匹配 - 特定账户实例
- channel匹配 - 整个平台通配符
- default - 默认Agent
最终resolveAgentRoute会找到适合处理当前消息的Agent。
接下来则是寻找Session的环节。OpenClaw会调用buildAgentSessionKey方法来构建一个SessionKey,作为会话存储的唯一标识符,每个Key对应独立的对话历史和状态。
SessionKey的生成规则是:
agent:{agentId}:{channel}:{scope}:{identifier},下面是一些例子(假设agentId=Alex):讯享网
// DM “agent:Alex:whatsapp:dm:+”
// 群组 “agent:Alex:whatsapp:group:@g.us”
通过这个Key,就能找到对应的Session文件的存储位置:
// 存储位置
/.openclaw/agents/<agentId>/sessions/
├── sessions.json // Key -> SessionEntry 映射
└── <sessionId>.jsonl // 具体对话历史
这套系统的消息机制是典型的事件驱动架构。
消息从各个Channel进入时不会被同步阻塞,而是通过回调把事件推送进系统。Channel接入层只负责把“新消息、连接变化、错误”等信号变成统一的异步事件,再交给后续处理链路,从源头保证高并发和低耦合。
进入系统后,会话运行期采用订阅式事件流来驱动整体流程。一次回复会建立对会话事件的订阅,事件包含消息开始、增量更新、消息结束、工具执行状态等。订阅层把原始事件整理为内部状态,并对外提供三类输出:实时的部分回复、可发送的块级回复、以及生命周期事件。这里的核心是“事件驱动状态机”,通过严格的事件类型和状态更新规则,让异步事件在逻辑上保持一致性。
流式输出并不是简单地把每个增量直接发出去,而是通过“增量事件 + 分块策略 + 发送管道”实现。增量事件提供文本变化,分块策略决定何时切块(例如按段落或长度阈值),发送管道保证顺序与合并,并在超时或异常时进行保护性中止。这样即使事件顺序有抖动,用户仍能收到连续、稳定、可读的流式结果。
异步回调的延迟是必然现象,因此系统对“晚到回调”做了防护:一旦运行结束并进入空闲状态,后续回调不会再触发新的输入状态或重复发送。这保证了外部表现的一致性,也避免了在复杂异步场景下出现长时间“卡在输入中”的问题。
Gateway本身也是任务/会话协调器(task/session coordinator),它接收你的消息并将其传递给正确的会话。这是 OpenClaw 的核心。它处理多个重叠的请求。
为了让操作串行化(serialization),OpenClaw 使用基于 lane 的命令队列(lane-based command queue)。一个会话有自己专用的 lane,低风险的可并行化(parallelizable)任务可以在并行 lane 上运行(例如 cron 定时任务)。
这与常见的 async/await 乱麻式写法(“async/await spaghetti”)相对。过度并行会降低可靠性,并带来大量调试噩梦。如果你做过智能体系统,多半也体会过这一点。
默认串行(Serial),需要并行时再显式并行(Parallel explicitly)。
简单地为每个 agent 搞一套 async 并发,日志会变成一坨交错的垃圾,几乎不可读;如果它们共享状态(shared states),竞态条件(race conditions)会变成你开发中必须时刻担心的风险。
Lane 是对队列(queue)的抽象:默认就是“串行化架构”,而不是事后补丁。作为开发者,你手写业务逻辑,队列系统帮你处理竞态。
智能的心智模型会从:“我需要加什么锁?”(what do I need to lock?)变成:“哪些东西是安全可并行的?”(what‘s safe to parallelize?)
这样的设计方式强调了事件流化、非阻塞、顺序可控和可恢复性。通道输入、会话订阅、流式输出、工具回调都被纳入同一个异步事件模型中,各模块只关心自己的职责边界,系统整体依赖事件驱动来保持高性能与稳定性。
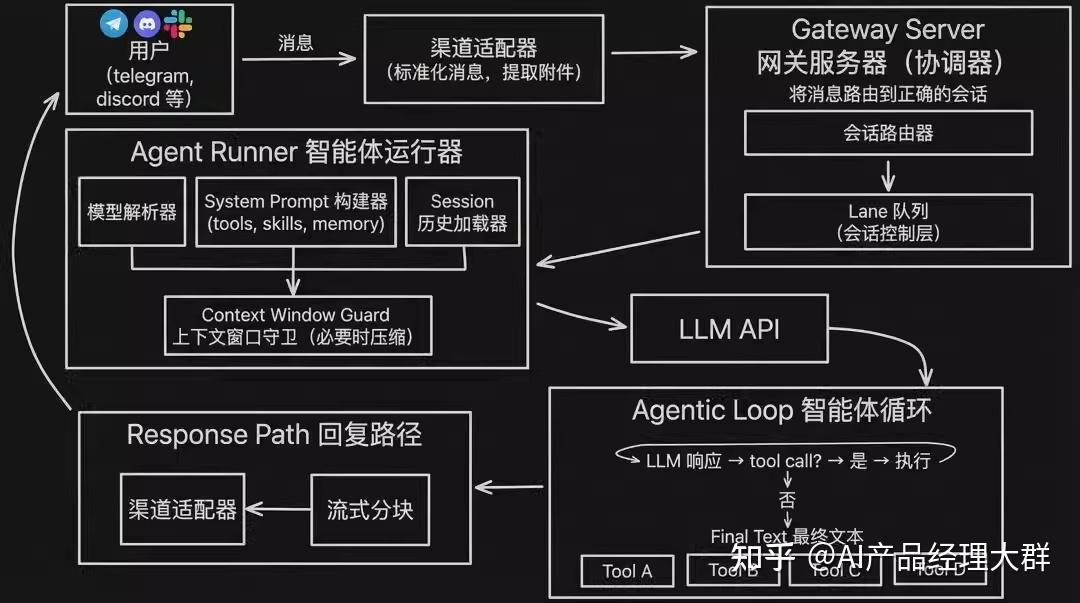
Agent Runner是基于Pi Agent Core(作者:Mario Zechner)这个Agent框架基础之上扩展而来的Agent执行引擎,负责协调所有Agent交互的模型推理、工具执行和会话管理。Agent Runner 会动态拼装 system prompt:包含可用工具(tools)、技能(skills)、记忆(memory),然后追加 session 历史(从 .jsonl 文件读取)。
openclaw支持多 Agent的创建和协作——一个 Gateway,控制无限的 Agent。可以让不同的聊天渠道/群组使用完全不同的 AI 助手实例,各自独立。
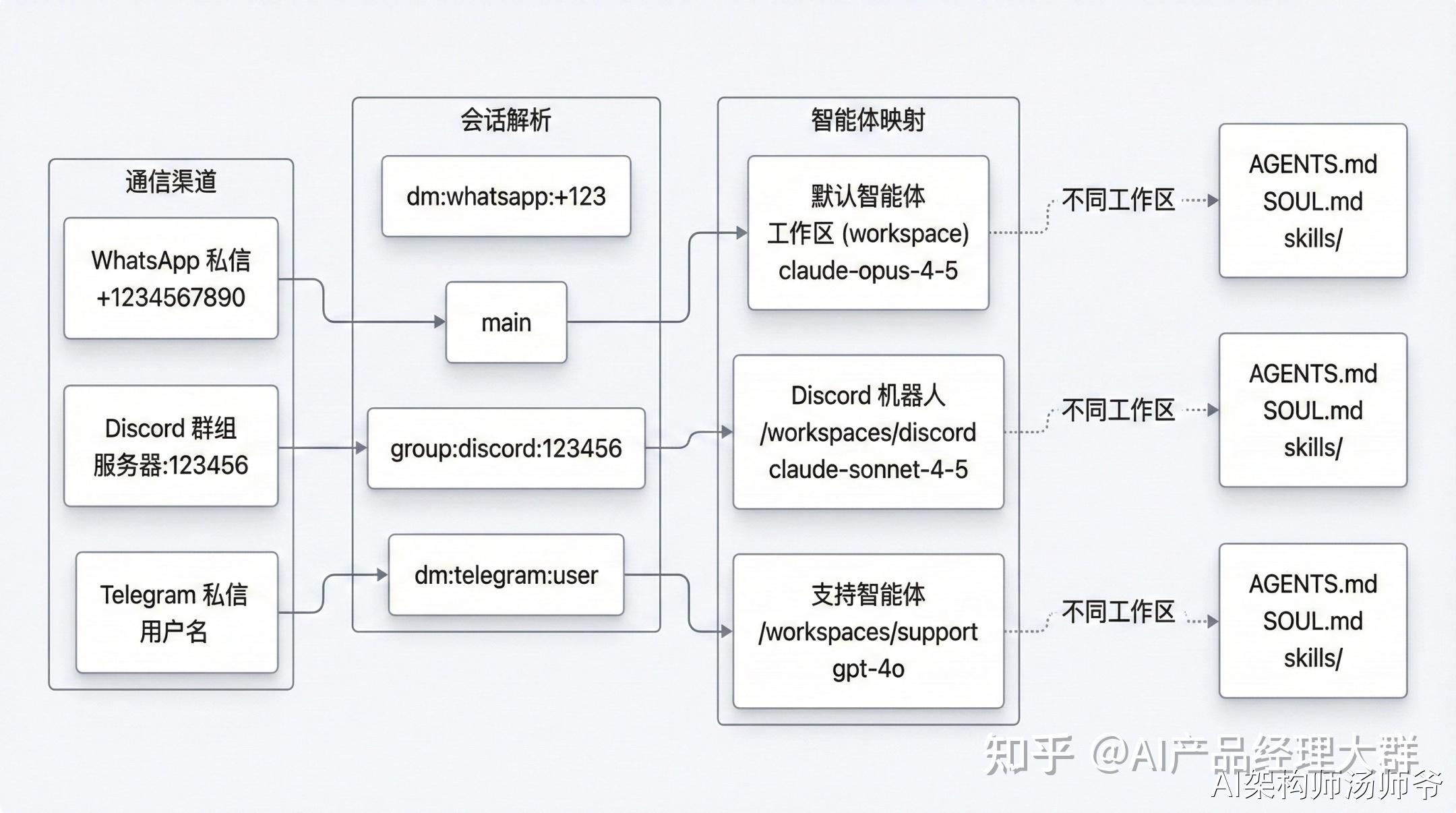
每个 Agent 都在 /.openclaw/agents/ 目录下有自己的独立文件夹。有自己的工作区、会话和记忆。工作 Agent 了解你的技术栈和项目;私人 Agent 了解你的习惯和日程,它们互不干扰。
频道映射在 config.json 中配置。向某个 Telegram 聊天发送消息,它会路由到工作 Agent;向另一个聊天发送,则路由到私人 Agent。同一个 Gateway,通过规则进行路由分发。
dmScope 控制着隔离级别。把它设置为 per-agent,每个 Agent 只能看到属于自己的对话。你可以扩展出一个通过心跳监控服务器的 Agent,一个解析信息源并将摘要存入专属 MEMORY.md 的研究 Agent,一个监控流动性池并随时提醒你机会的交易 Agent。所有的 Agent 都在同一个 Gateway 上运行。
对于Agent 之间怎么互相沟通和协作,OpenClaw 提供了一组会话工具,让不同的 Agent 可以互相传话、协作:
sessions_list:查看有哪些活跃会话sessions_send:给另一个会话发消息sessions_history:查看另一个会话的对话记录sessionsspawn:创建新会话来委派任务
规则:如果有多个人访问同一个 Agent,必须将dmScope设置为per-channel-peer。否则,来自不同用户的会话会被折叠成一个。Agent 会用别人对话里的信息来回复你。这是个默认行为,你需要手动修改。
关于pi智能体框架的详细内容,我将在单独的章节展开介绍。
data-pid=“SdA2D4A”>Pi Agent Core (@mariozechner/pi-agent-core) 是一个面向 Node.js 环境的轻量级Agent运行时库。其核心设计目标是提供一个最小化的、传输层无关(Transport-Agnostic)的执行环境,用于构建有状态的、能够处理复杂工具调用的AI应用。
与LangChain等全栈式框架不同,Pi Agent Core采取“微内核”设计策略,剥离了具体模型集成与向量数据库依赖,专注于Agent的控制流与通信协议抽象。
pi-mono 是一个 monorepo,里面包含多个包(例如 pi-agent-core、pi-coding-agent、pi-ai、pi-tui 等),Pi Agent Core(pi-agent-core) 是 pi-mono 的一个包,提供 agent loop、工具执行与消息类型等核心能力。OpenClaw还使用到了pi-mono中的其他的功能模块。
会话(Session)是常见的Agent系统或者ChatBot类应用中的必备功能。OpenClaw利用了Pi Agnet Core自带的Session管理的能力,并在此基础上做了少量扩展:
- OpenClaw使用Pi Agent Core原生接口,但自定义会话存储位置
- 实现了系统提示动态构建、工具策略过滤、沙盒路径重定向、多认证轮换、提供商标记化
在OpenClaw中,每个Session由唯一的一个Key来标识,每个Key对应独立的对话历史和状态。关于结构和用法前面已经介绍过了。
OpenClaw对于SessionKey的独特设计,使得其能够处理并发冲突:同一Session Key的消息排队处理,不同Session Key的消息可并行处理。
对于排队的情况,支持的模式有:
- sequential:同一会话的消息串行处理,防止并发冲突
- concurrent:允许同一会话的多个Agent并发运行
- collect:防抖并批量处理快速连续的消息
- Steer:将排队消息注入当前运行
- Followup:等待当前回合结束后处理排队消息
Session Store用于维护会话元数据的键值映射,OpenClaw还会在这个文件中维护一个Token计数器。位置默认在/.openclaw/agents/<agentId>/sessions/sessions.json
Transcript用于存储完整的对话历史,采用JSONL格式,默认位置在/.openclaw/agents/<agentId>/sessions/<sessionId>.jsonl,Transcript的存储采用树形结构,每条记录有 id 和 parentId,支持分支对话。
Session Manager负责读写转录文件、重建模型上下文、处理压缩、维护会话树结构
重置策略
OpenClaw有以下几种重置Session的策略:
- 每日重置:默认凌晨4点本地时间重置
- 空闲重置:
idleMinutes滑动窗口,无活动超时后重置 - 手动重置:
/new或/reset命令触发 - 优先级:每日和空闲同时配置时,先到期的先生效
压缩与清理
通大多数压缩策略一样,OpenClaw支持Summary这样的一种压缩策略,即上下文接近限制时触发,总结历史对话。
此外,还有一种“内存刷新”的设计,即在会话接近自动压缩时触发的一个后台内存整理机制,确保重要信息在压缩前被持久化保存。
具体来说,当会话token使用量接近上下文窗口限制时,Gateway会:
- 构建系统提示词
- 运行一个静默的agent回合
- 模型根据提示词判断并写入重要信息,写入
memory/YYYY-MM-DD.md或MEMORY.md - 使用
NO_REPLY标记避免用户看到输出
下面是对于模型要提取的”重要信息“的定义:
讯享网 3.2 What to Preserve Preserve specific details that future-you will need:
Preserve
Example
Specific locations
“src/auth/login.ts:67” not “the auth code”
Exact findings
“SQL injection in query builder” not “security issues”
Decisions with rationale
“Approved because X” not just “Approved”
Numbers and thresholds
“Coverage at 73%, target is 80%” not “coverage is low”
Names and identifiers
“User.authenticate() method” not “the login function”
Open questions
“Need to verify: does rate limiter apply to OAuth flow?”
│ Applications │ │ pi-coding-agent, pi-tui, pi-mom, … │ ├─────────────────────────────────────────┤ │ Core │ │ pi-agent-core │ ├─────────────────────────────────────────┤ │ Foundation │ │ pi-ai │ └─────────────────────────────────────────┘
基础包零内部依赖。核心包仅依赖基础层。应用层在最上方。 这不是愿望——构建系统强制执行。
要理解Pi的设计逻辑,首先要跳出当前Agent开发的固有思维定式,读懂它的反直觉立场。在当前的Agent框架生态中,无论是Claude Code这样的巨头产品,还是各类开源项目,几乎都在沿着“做加法”的路径前进。大家普遍认为,Agent的能力越强,需要的工具就越多,系统提示词就越长,规划链路就越复杂,甚至需要引入多个子Agent协同工作,才能应对各类复杂场景。这种思路看似合理,却忽略了一个核心事实,那就是前沿的LLM模型经过RL训练后,已经具备了足够强的理解能力和执行能力,能够清晰地认知“编码Agent”的核心职责,根本不需要冗长的系统提示词和复杂的辅助模块来“教”它如何工作。
Mario Zechner对此有着明确的观点,他认为前沿模型已经被RL训练得足够理解“编码Agent”是什么,你不需要10000 token的系统提示词。这句话并非空谈,而是有着实打实的实践支撑。Pi在Terminal-Bench 2.0基准测试中,使用Claude Opus 4.5模型,成功跻身排行榜前列,与Codex、Cursor、Windsurf等拥有复杂工具链的Agent展开激烈竞争。而令人震惊的是,Pi的系统提示词加上工具定义的总长度还不到1000 token,不足Claude Code的十分之一,内置工具也只有4个,远远少于同类产品。
为了更清晰地展现Pi与主流Agent的差异,我们可以通过一组关键维度的对比来直观感受它的极简特性。
| 对比维度 | Claude Code | Codex | Pi |
|---|---|---|---|
| 系统提示词 | 约10000+ tokens | 适中 | < 1000 tokens |
| 内置工具数 | 数十个 | 适中 | 4个 (read/write/edit/bash) |
| Plan Mode | 有(黑盒子Agent) | 有 | 无(用文件代替) |
| MCP 支持 | 有 | 有 | 无(用CLI工具代替) |
| Sub-Agent | 有(不可观测) | — | 无(通过bash自我调用) |
从这份对比中我们可以发现,Pi在所有主流Agent都在强化的模块上几乎都做了减法。没有冗长的系统提示词,没有数量众多的内置工具,没有复杂的Plan Mode和MCP支持,更没有不可观测的子Agent。但就是这样一款“极简”的架构,却能在核心性能上与主流产品比肩,这背后恰恰体现了Pi设计思路的先进性——放弃冗余的辅助模块,让LLM回归核心,用最简洁的结构实现最核心的功能。
很多人可能会疑惑,如此极简的设计,真的能应对复杂的编码场景吗?事实上,Pi的极简并不是“简陋”,而是“精准”。它选择的4个内置工具read、write、edit、bash,几乎覆盖了编码Agent的所有核心需求,无论是读取文件、写入内容,还是编辑代码、执行命令,都能通过这4个工具高效完成。而bash工具的引入,更是巧妙地解决了子Agent的需求,通过bash自我调用,Pi可以实现复杂的任务拆分和执行,既保证了功能的完整性,又避免了引入子Agent带来的黑盒问题和观测困难。
与此同时,Pi放弃冗长的系统提示词,也并非降低了对LLM的引导要求,而是充分信任前沿LLM的能力。Mario Zechner认为,与其用大量的token去“教导”LLM如何成为一个Agent,不如用简洁的提示词明确其核心职责,让LLM充分发挥自身的理解和执行能力。这种思路不仅减少了上下文窗口的占用,提升了运行效率,还让Agent的行为更加灵活自主,能够更好地适应不同的场景需求。
深入探索
函数库
程序设计
应用
Pi的极简主义不仅体现在设计理念上,更贯穿于整个架构实现之中。Pi Agent Core的全部源码只有5个文件,总代码量约1500行,却构建起了一个完整、高效、灵活的Agent运行时。这5个文件分别是types.ts、agent-loop.ts、agent.ts、proxy.ts和index.ts,每个文件对应一个核心模块,各司其职、相互配合,构成了Pi的完整架构。接下来,我们将逐层剖析每个核心模块的设计决策和实现细节,读懂这5个文件背后的精妙设计。
types.ts作为Pi的类型定义文件,是整个架构的基础,它的设计核心是“少即是多”,通过简洁而灵活的类型定义,为后续模块的实现提供了坚实的支撑。其中,最精妙的设计莫过于AgentMessage类型的抽象,它实现了应用状态与模型上下文的分离,这也是Pi能够实现“最晚转换”策略的关键。
深入探索
python
开发语言
分布式计算
在types.ts中,首先定义了一个空接口CustomAgentMessages,这个接口默认是空的,应用层可以通过Declaration Merging的方式对其进行扩展,添加自定义的消息类型。随后,AgentMessage类型被定义为Message类型与CustomAgentMessages所有子类型的联合类型,也就是说AgentMessage既可以是LLM能够直接理解的Message类型,也可以是应用层自定义的各类消息类型。
可能有很多开发者会疑惑,为什么不直接使用LLM的Message类型,反而要额外定义一个AgentMessage类型呢?这其实是Mario Zechner基于真实应用场景的精准考量。在实际的Agent应用中,存在大量“非LLM消息”,这些消息并不需要交给LLM处理,如果直接使用Message类型,就无法对这些消息进行有效区分,要么会导致LLM处理无关消息,影响效率,要么会增加额外的过滤逻辑,增加系统复杂度。
我们可以通过一个具体的场景对比来理解这一设计的优势。在一个编码Agent应用中,用户提问属于UserMessage,Agent回复属于AssistantMessage,工具结果属于ToolResultMessage,这些都是需要交给LLM处理的消息。但与此同时,应用中还会存在UI通知、文件变更事件、会话分支标记等消息,这些消息属于应用层的状态通知,并不需要LLM进行处理,如果交给LLM,不仅会浪费上下文窗口,还可能导致LLM做出错误的判断。
AgentMessage类型的设计,恰好解决了这一问题。应用层通过扩展CustomAgentMessages,可以灵活添加各类自定义消息类型,内部所有逻辑,包括上下文压缩、会话分支管理、UI渲染等,都基于AgentMessage类型运转,只有在调用LLM的瞬间,才会通过convertToLlm方法将AgentMessage数组过滤转换为LLM能够理解的Message数组。这种“最晚转换”策略,不仅保证了应用层的灵活性,还最大限度地减少了LLM的无效处理,提升了系统的运行效率。
除了AgentMessage,types.ts中还定义了AgentLoopConfig接口,这个接口的设计同样体现了Pi的极简主义。AgentLoopConfig继承自SimpleStreamOptions,包含了模型实例、消息转换方法、上下文变换方法、引导消息获取方法、后续消息获取方法以及API Key获取方法等核心配置项。值得注意的是,这个接口中并没有包含maxSteps、maxTokens、temperature等常见的配置项,这些配置项虽然继承自SimpleStreamOptions,但循环本身并不关心这些细节,这种设计让循环逻辑更加纯粹,只专注于核心的任务流转,而将细节配置交给上层模块处理,实现了职责的清晰划分。
另外,types.ts中还定义了AgentEvent类型,通过三层嵌套的生命周期事件,实现了Agent运行过程的细粒度可观测。AgentEvent包含了agent_start、agent_end、turn_start、turn_end、message_start、message_update、message_end以及工具执行相关的各类事件,覆盖了Agent从启动到结束的整个生命周期。这种细粒度的事件设计,让开发者能够清晰地观测到Agent的每一步操作,包括LLM调用、工具执行、消息更新等,彻底解决了主流Agent中存在的黑盒问题,为调试和优化提供了极大的便利。
agent-loop.ts是Pi的核心模块,负责实现Agent的核心循环逻辑,也就是Mario Zechner所说的“LLM + tools + a loop”中的loop部分。这个模块的核心设计是双层While循环,外层由FollowUp消息驱动,内层由ToolCall和Steering消息驱动,通过这种精密的循环设计,实现了Agent任务的高效流转和灵活干预,同时保证了系统的简洁性和可维护性。
在深入解析双层循环之前,我们首先要明确Pi的核心循环理念:循环的目的是实现任务的自主执行和灵活调整,不需要复杂的规划模块,只需要通过消息驱动和工具执行,就能完成各类复杂任务。基于这一理念,Pi的核心循环没有设计复杂的规划链路,而是通过简单的循环逻辑,结合消息队列和工具执行,实现了任务的自主推进。
agent-loop.ts中提供了两个核心入口函数,分别是agentLoop和agentLoopContinue,这两个函数的设计体现了Pi对不同场景的精准适配,尤其是实现了优雅的重试与恢复功能。其中,agentLoop函数主要用于用户发送新消息的场景,可以从空上下文开始,启动一轮新的对话和任务执行;而agentLoopContinue函数则主要用于重试或恢复场景,不需要重新构造prompt,直接从当前上下文继续执行任务。
这种入口的区分,看似简单,却解决了Agent开发中的一个常见痛点。在很多主流Agent框架中,当任务执行出错或需要重试时,开发者需要重新构造prompt和上下文,操作繁琐且容易出错。而Pi通过agentLoopContinue函数,让重试变得异常优雅,出错后不需要重新构造任何内容,直接调用该函数,就能从当前上下文继续执行,极大地提升了开发效率和用户体验。
核心循环的核心是双层While结构,这也是Pi能够实现自主任务执行和灵活干预的关键。外层循环由FollowUp消息驱动,主要负责任务的后续推进;内层循环由ToolCall和Steering消息驱动,主要负责工具执行和中途干预,两层循环相互配合,构成了完整的任务流转逻辑。
外层循环的逻辑非常简洁,它是一个无限循环,当内层循环处理完当前的工具调用和消息后,Agent即将停止时,会检查是否有FollowUp消息。如果存在FollowUp消息,就将这些消息设为待处理消息,重启内层循环,继续执行后续任务;如果没有FollowUp消息,就跳出循环,任务正式结束。这种设计的优势在于,能够实现任务的连续推进,用户可以在Agent完成当前任务后,添加后续任务,Agent会自动继续执行,不需要重新启动循环。
内层循环则是任务执行的核心,它同样是一个无限循环,只要存在未处理的工具调用或待处理消息,就会持续执行。内层循环的主要流程包括注入待处理消息、流式调用LLM、执行工具、检查Steering消息等步骤。在这个循环中,Agent会不断地调用LLM生成工具调用指令,执行工具获取结果,再将结果反馈给LLM,生成下一步操作,直到所有工具调用完成,没有待处理消息为止。
值得注意的是,内层循环中加入了Steering中断的实现,这也是Pi实现用户中途干预的关键。当用户在工具执行期间发送Steering消息时,工具执行会立即停止,后续未执行的工具会被标记为“因排队的用户消息而跳过”并返回错误结果,然后跳出内层循环,将Steering消息注入上下文,下一轮LLM调用时,会看到已执行工具的正常结果、被跳过工具的错误结果以及用户的Steering消息,从而理解发生了什么,并做出适当的调整。
这种Steering中断机制,解决了主流Agent中用户无法中途干预的痛点。在很多复杂场景中,用户可能会发现Agent的执行方向出现偏差,此时需要能够及时中断并修正,但大多数主流Agent要么不支持中途干预,要么干预后无法正确处理后续逻辑。而Pi的Steering中断机制,不仅能够实现即时中断,还能通过错误结果标记,让LLM清晰地了解干预情况,做出正确的调整,保证任务能够按照用户的预期推进。
agent-loop.ts中还实现了streamAssistantResponse函数,这个函数是AgentMessage与Message转换的唯一边界,负责实现流式应答处理,同时保证上下文的实时更新。流式应答是提升用户体验的关键,尤其是在处理复杂任务时,用户能够实时看到Agent的响应过程,而不需要等待整个任务完成。
streamAssistantResponse函数的执行流程可以分为五个步骤。第一步是可选的上下文变换,通过config.transformContext方法,可以对上下文消息进行剪枝、注入外部上下文等操作,从而优化上下文质量,减少无效信息的占用。第二步是消息转换,通过config.convertToLlm方法,将AgentMessage数组转换为LLM能够理解的Message数组,这也是“最晚转换”策略的核心实现点,只有在调用LLM的瞬间才进行转换,最大限度地保证了应用层的灵活性。
第三步是动态解析API Key,支持过期OAuth Token的动态更新,通过config.getApiKey方法,能够根据模型提供商的不同,动态获取对应的API Key,避免了API Key硬编码带来的安全隐患和维护问题。第四步是流式调用LLM,通过streamFunction方法,调用模型的流式接口,获取实时的响应事件。第五步是实时转发事件,将LLM返回的每个delta事件实时转发给UI,同时将部分消息就地更新到上下文消息数组中,确保上下文始终是当前最新状态。
这里有一个非常关键的细节,部分消息会被就地更新到context.messages数组中,也就是说,上下文消息数组会随着LLM的流式响应实时更新,而不是等到整个响应完成后再更新。这种设计的优势在于,无论任务执行到哪一步,上下文都能反映当前的最新状态,当出现重试、干预等场景时,LLM能够基于最新的上下**出判断,避免了因上下文滞后导致的错误。
agent.ts模块实现了Agent类,这个类的核心作用是作为状态容器和消息队列,负责管理Agent的运行状态、处理消息队列、实现错误恢复等功能。Agent类的设计同样遵循极简主义理念,没有复杂的逻辑,却能实现灵活高效的任务管理,为上层应用提供了简洁易用的接口。
Agent类引入了两种队列模式,分别是Steering模式和FollowUp模式,每种模式都支持“all”和“one-at-a-time”两种类型。其中,Steering模式用于处理用户中途发送的干预消息,FollowUp模式用于处理用户添加的后续任务消息,两种模式相互独立,确保了消息处理的有序性和灵活性。
“all”模式表示一次性发送所有队列中的消息,适用于消息数量较少、不需要逐一条理的场景;“one-at-a-time”模式表示每次只发送一条消息,处理完成后再发送下一条,适用于消息数量较多、需要逐条处理的场景。为什么需要“one-at-a-time”模式呢?我们可以通过一个具体的场景来理解。假设用户在Agent工作时快速发送了3条修正消息,如果使用“all”模式,Agent会一次性收到这3条消息,很可能只会回应最后一条,导致前两条修正消息被忽略;而使用“one-at-a-time”模式,Agent会逐条处理这3条消息,每条消息都能得到充分的响应,确保用户的所有需求都能被满足。
编程
这种队列模式的设计,充分考虑了真实应用中的场景需求,让Agent能够根据不同的消息类型和数量,灵活选择合适的处理方式,既保证了处理效率,又避免了消息遗漏或处理不充分的问题。
Agent类提供了一系列核心方法,包括prompt、continue、steer、followUp、abort等,每个方法都有明确的调用时机和功能,职责划分清晰,方便上层应用灵活调用。
prompt方法用于Agent空闲时,用户发送新消息的场景,调用该方法会启动一轮新的对话和任务执行,将用户消息添加到待处理队列中,触发核心循环。continue方法用于Agent空闲时,需要重试或恢复任务的场景,调用该方法会从当前上下文继续执行任务,不需要重新构造prompt和上下文。steer方法用于Agent工作时,用户需要中途干预的场景,调用该方法会中断当前的工具链,将干预消息添加到Steering队列中,触发内层循环的重新执行。
followUp方法用于任何时候,用户需要添加后续任务的场景,调用该方法会将后续任务消息添加到FollowUp队列中,当当前任务完成后,Agent会自动执行后续任务。abort方法用于Agent工作时,需要取消当前任务的场景,调用该方法会取消当前的LLM调用,终止任务执行,并标记任务状态为“aborted”。
这些方法的设计,让上层应用能够根据不同的场景需求,灵活调用对应的方法,实现对Agent的精准控制。同时,方法的命名简洁易懂,降低了上层应用的开发难度,提升了开发效率。
错误恢复是Agent开发中的一个重要环节,尤其是在复杂的任务场景中,很容易出现LLM调用失败、工具执行错误等问题,如果不能妥善处理这些错误,很可能导致系统崩溃或任务无法继续执行。Pi的Agent类在错误处理方面做了非常细致的设计,能够优雅地处理各类异常,保证系统的稳定性。
软件
在Agent类的核心逻辑中,所有可能出现错误的地方都添加了try-catch捕获机制,当出现错误时,会在catch块中构造一个完整的AssistantMessage,该消息包含了错误状态、错误信息等内容,其中stopReason被标记为“error”,如果是用户主动取消,则标记为“aborted”。然后,将这个错误消息添加到上下文消息数组中,确保错误状态能够成为上下文历史的一部分。
这种设计的优势在于,当任务执行出现错误时,用户可以通过调用continue方法,从错误处重试,LLM会看到之前的错误信息,并据此调整策略,避免再次出现相同的错误。同时,错误消息被添加到上下文后,也方便开发者调试和分析错误原因,提升系统的可维护性。
proxy.ts模块是Pi为Web应用场景设计的核心模块,主要用于解决Web应用中LLM调用的带宽优化问题。在Web应用场景中,Agent的运行流程通常是浏览器发送请求到代理服务器,代理服务器调用LLM接口,再将响应结果返回给浏览器。如果直接传输完整的响应消息,尤其是流式响应中的部分消息,会占用大量的带宽,影响响应速度,尤其是在网络环境较差的情况下,这种影响会更加明显。
为了解决这一问题,Pi的Proxy Stream模块引入了一种带宽优化策略,服务器不传输完整的部分消息对象,仅传输轻量的delta事件。具体来说,ProxyAssistantMessageEvent比原始的AssistantMessageEvent轻得多,它去掉了完整的部分字段,仅包含contentIndex、delta等最小必要信息。客户端通过processProxyEvent方法,根据这些delta事件,逐步重建完整的响应消息,从而减少了带宽占用,提升了响应速度。
这种设计的核心思路是“按需传输”,只传输客户端重建完整消息所必需的最小信息,避免传输冗余数据。通过这种方式,不仅能够节省带宽,还能提升响应速度,改善用户体验,让Pi能够更好地适配Web应用场景的需求。同时,Proxy Stream模块的设计也保持了极简主义,没有引入复杂的压缩算法,仅通过数据裁剪的方式实现带宽优化,兼顾了效率和简洁性。
操作系统
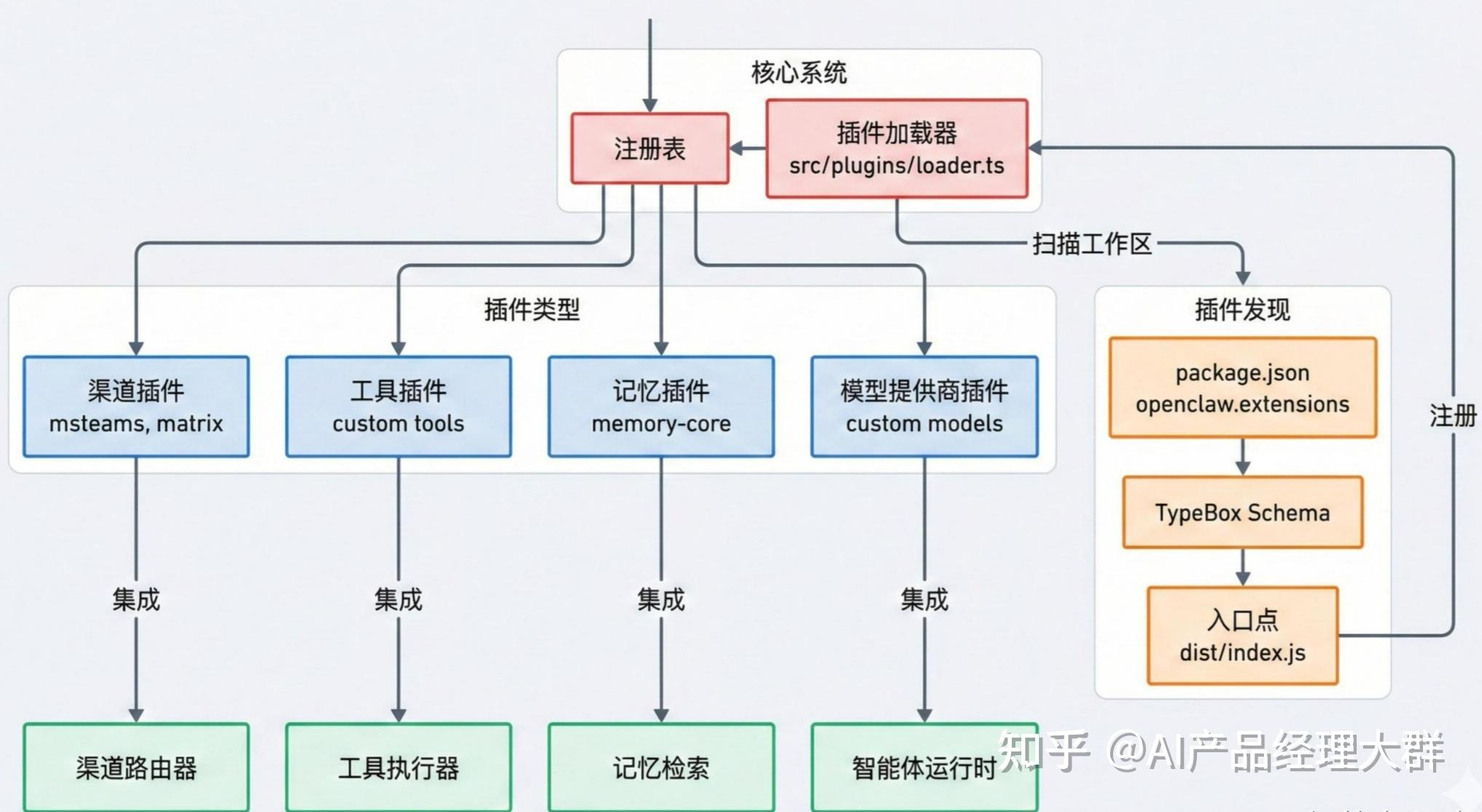
那么OpenClaw 怎么让别人在不改核心代码的情况下,扩展新功能?OpenClaw 的设计哲学是开放扩展,不改核心。
可以通过插件(Plugin)在四个方向上扩展:
- 渠道插件(Channel Plugin):添加新的聊天平台,比如 飞书、钉钉等
- 记忆插件(Memory Plugin):换一种存储后端,比如用向量数据库代替默认的 SQLite
- 工具插件(Tool Plugin):添加自定义能力,比如除了内置的命令行、浏览器、文件操作之外的新工具
- 模型提供商插件(Provider Plugin):接入自定义的 AI 模型或自己部署的模型
插件代码放在 extensions/ 目录下,系统会自动扫描、发现和加载。
OpenClaw可以使用基于Docker的沙箱技术,用于在Agent执行工具时提供运行时隔离与权限约束,以降低对宿主环境的影响范围,并形成可配置的最小权限执行面。其使用场景主要体现在以下功能层面:
- 会话级隔离:在多会话或群聊场景中,非主会话可配置为在隔离环境中执行工具调用,使其与宿主进程、宿主文件系统、主会话的执行上下文分离,减少非主入口对宿主资源的直接访问。
- 文件系统访问控制:沙箱可限制工具读写范围到特定工作区,并支持不同的访问级别(如不挂载宿主工作区、只读挂载或读写挂载)。工具对文件路径的解析与访问会被约束在沙箱根目录内,避免越界读写。
- 命令执行隔离:当启用沙箱模式时,命令执行工具在隔离环境中运行,执行环境的工作目录、环境变量与资源限制由沙箱配置控制,防止命令直接在宿主环境中运行。
- 工具可用性与策略约束:沙箱支持工具级 allow/deny 策略。即使工具在全局可用,进入沙箱后仍会按沙箱策略过滤,确保在隔离会话中只暴露经过许可的工具能力。
- 浏览器执行隔离:沙箱可为浏览器能力提供独立的隔离运行环境,并控制是否允许宿主级浏览器控制或仅允许沙箱内控制,以限制网页自动化对宿主浏览器环境的影响。
- 会话工具可见性限制:当会话处于沙箱模式时,可限制会话管理类工具对其他会话的可见性与操作范围,例如仅允许访问由当前会话派生的子会话,避免跨会话访问与干预。
- 运维与诊断:沙箱提供容器级管理与解释能力,支持查看沙箱容器状态、重建容器以及解释当前会话的生效策略,用于排查策略阻断或运行异常问题。
OpenClaw将自己的仓库直接交给DeepWiki自动生成Doc,并支持通过Devin Agent来询问关于仓库的任何信息。
不过以OpenClaw的Doc的质量来看,很难说这是因为OpenClaw的代码质量不够好,还是DeepWiki的生成质量不好,总之这份Doc相当的糟糕,大量的重复与冗余,不仅没有将代码的工作流程梳理清楚,有些地方似乎还形成误导。而尝试通过Devin来滤清代码的脉络,其效果又远不如Codex。
说回到项目本身,涉及到Agent的部分几乎没有突破式的创新,但是如何将不同IM渠道,不同设备整合在一单一的WebSocket Server之上,还是能学到很多工程方面的知识。
一文读懂:openClaw 分析与教程+免费大模型(Moltbot、Clawdbot) 二更一文揭秘: OpenClaw的底层技术与核心功能Moltbot/Clawdbot/pi-ai 中有最有趣的工程实践。Mario 识别出每个供应商都说四种通信协议之一:
- OpenAI Completions (/v1/chat/completions)
- OpenAI Responses (/v1/responses — 较新的结构化格式)
- Anthropic Messages (/v1/messages)
- Google Generative AI (/v1beta/models/{model}:generateContent)
Pi 围绕这四种协议进行规范化,并维护一个300+ 模型定义的目录,在构建时从 models.dev 和 OpenRouter 元数据自动生成:
interface ModelDefinition { id: string; provider: string; protocol: ‘openai-completions’ | ‘openai-responses’ | ‘anthropic’ | ‘google’; contextWindow: number; maxOutputTokens: number; inputCostPer1M: number; outputCostPer1M: number; capabilities: { 讯享网vision: boolean; toolUse: boolean; streaming: boolean; reasoning: boolean;
}; }抽象层内部处理数十个供应商特定的特性。结果:调用 300+ 模型中的任何一个看起来都一样:
import { getModel, stream, Context } from ‘@mariozechner/pi-ai’; const model = getModel(‘anthropic’, ‘claude-sonnet-4-’); const context: Context = { systemPrompt: ‘You are a helpful assistant.’, messages: [{ role: ‘user’, content: ‘Hello’ }] }; for await (const event of stream(model, context)) { if (event.type === ‘text_delta’) { 讯享网process.stdout.write(event.delta);
} }工具使用 TypeBox schema 和 AJV 验证。当验证失败时,错误作为工具结果返回给模型,让它可以自我纠正:
import { Type } from ‘@mariozechner/pi-ai’; const tools = [{ name: ‘read_file’, description: ‘Read contents of a file’, parameters: Type.Object({ 讯享网path: Type.String({ description: 'Absolute path to file' }), startLine: Type.Optional(Type.Number({ description: 'Start line (1-indexed)' })), endLine: Type.Optional(Type.Number({ description: 'End line (1-indexed)' }))
}) }];这消除了整类运行时故障——模型在同一轮内从错误中学习。
上下文对象完全可序列化,可跨供应商移植:
interface Context { systemPrompt: string; messages: Message[]; tools?: Tool[]; temperature?: number; maxTokens?: number; } interface Message { role: ‘user’ | ‘assistant’; content: string | ContentBlock[]; toolCalls?: ToolCall[]; toolResults?: ToolResult[]; thinking?: string; }pi-agent-core 中的核心循环故意极简:
讯享网async function* agentLoop( model: Model, context: Context, tools: Tool[], options: AgentOptions ): AsyncGenerator<AgentEvent> { while (true) { // 1. 调用 LLM const response = await streamCompletion(model, { ...context, tools }); // 流式发送助手消息 yield { type: 'assistant_message', content: response.content }; // 2. 没有工具调用则完成 if (!response.toolCalls?.length) { break; } // 3. 执行工具调用 const results: ToolResult[] = []; for (const call of response.toolCalls) { yield { type: 'tool_start', name: call.name, input: call.input }; // 执行并捕获结果 const result = await executeToolCall(call, context); results.push(result); yield { type: 'tool_end', name: call.name, result }; } // 4. 将助手消息 + 工具结果添加到上下文 context.messages.push({ role: 'assistant', content: response.content, toolCalls: response.toolCalls }); context.messages.push({ role: 'user', toolResults: results });
} }
就是这样。没有最大步数设置(“循环一直运行直到 Agent 说它完成了”),没有计划模式(“把计划写入文件——完全可观察”),没有内置待办跟踪(“待办列表通常让模型更困惑而不是帮助”)。
每个工具结果都包含 output(给 LLM 的文本)和 details(给 UI 渲染的结构化数据):
讯享网interface ToolResult { toolCallId: string; output: string; // 发送给 LLM 的文本 details?: { // UI 渲染的结构化数据 type: 'file' | 'diff' | 'terminal' | 'error'; data: unknown;
}; } // 示例 { output: “Contents of /src/app.ts:\ntypescript\nexport function main() {...}\n”, details: { 讯享网type: 'file', data: { path: '/src/app.ts', content: 'export function main() {...}', language: 'typescript', lineCount: 42 }
} }
这种分离保持模型上下文干净,同时启用丰富的 UI 渲染。
Pi 只提供四个工具:
const readTool = { name: ‘read’, description: ‘Read file contents or view images’, parameters: Type.Object({ 讯享网paths: Type.Array(Type.String(), { description: 'Absolute paths to files or images' }), startLine: Type.Optional(Type.Number()), endLine: Type.Optional(Type.Number())
}) };const writeTool = { name: ‘write’, description: ‘Create or overwrite a file’, parameters: Type.Object({ 讯享网path: Type.String({ description: 'Absolute path' }), content: Type.String({ description: 'File content' })
}) };const editTool = { name: ‘edit’, description: ‘Replace text in a file using search/replace’, parameters: Type.Object({ 讯享网path: Type.String(), edits: Type.Array(Type.Object({ search: Type.String({ description: 'Exact text to find' }), replace: Type.String({ description: 'Replacement text' }) }))
}) };edit 工具需要精确字符串匹配——没有正则,没有模糊匹配。如果搜索字符串不精确匹配一次,它会失败并给出清晰的错误。这迫使模型先读取文件并使用精确字符串。
const bashTool = { name: ‘bash’, description: ‘Execute a bash command’, parameters: Type.Object({ 讯享网command: Type.String({ description: 'Command to execute' }), timeout: Type.Optional(Type.Number({ default: 30000 }))
}) };没有后台进程——如果需要,使用 tmux。工具同步运行命令并返回完整输出。
Mario 的论点:“所有前沿模型都经过了大量 RL 训练,所以它们天生理解什么是编程 Agent。” 模型知道 bash 是什么。它知道文件如何工作。添加专门的工具(如“在代码库中搜索”工具)只是给系统提示词添加 token 而不增加能力。
如果你需要 ripgrep,通过 bash 运行 rg。如果你需要搜索 GitHub,通过 bash 使用 gh。模型可以阅读文档并弄清楚 CLI 工具。
比较 Claude Code 数千 token 的系统提示词与 Pi 的:
You are Pi, a coding assistant. You help users write, debug, and understand code. You have access to these tools:
- read: Read files and images
- write: Create/overwrite files
- edit: Make surgical edits to files
- bash: Run shell commands
Work directly in the user‘s project. Read files to understand context before making changes. Use bash to run tests, linters, and other tools. Think step by step. If you’re unsure, read more files or ask the user.这大约是整个系统提示词。其他一切——项目上下文、约定、文档——都来自磁盘上的文件。
Pi 从项目根目录和子目录读取 AGENTS.md 文件:
讯享网# AGENTS.md Project Overview
This is a React + TypeScript monorepo using pnpm workspaces. Commands
pnpm dev - Start development serverpnpm test - Run testspnpm lint - Run linting
Conventions
- Use functional components with hooks
- Put tests in
__tests__ folders
- Use kebab-case for file names
Agent 在进入目录时读取这些,仅在相关时获取上下文。
会话持久化为 .jsonl 文件,具有特定结构:
interface SessionEntry { id: string; // 唯一 ID parentId?: string; // 父条目 ID type: ‘message’ | ‘tool_call’ | ‘tool_result’ | ‘meta’; timestamp: number; data: unknown; }格式是仅追加 DAG(有向无环图)。每个条目有一个 ID 和可选的父 ID,形成树结构。分支只是移动“叶指针”而不是创建新文件:
讯享网 ┌── entry1 ── entry2 ── entry3 (main branch) │ └── entry4 (branched) └── entry5 ── entry6 (another branch)
切换分支只是改变你追加到哪个叶子。整个历史都被保留。
会话可以包含来自多个供应商的消息:
{“id”:“1”,“type”:“message”,“data”:{“role”:“user”,“content”:“Explain this code”}} {“id”:“2”,“parentId”:“1”,“type”:“message”,“data”:{“role”:“assistant”,“content”:“…”,“model”:“anthropic/claude-sonnet-4-”}} {“id”:“3”,“parentId”:“2”,“type”:“message”,“data”:{“role”:“user”,“content”:“Now using GPT-4”}} {“id”:“4”,“parentId”:“3”,“type”:“message”,“data”:{“role”:“assistant”,“content”:“…”,“model”:“openai/gpt-4o”}}Thinking 跟踪在跨越供应商时被规范化为文本格式。
技能是带有 YAML 前言的 Markdown 文件:
讯享网— name: react-patterns description: Best practices for React development triggers:
- react
- jsx
- component —
React Patterns
Component Structure
Always use functional components with hooks… State Management
Prefer useState for local state…
关键洞察:只有描述永久存在于上下文中。完整技能内容在触发器匹配时按需加载。
与 MCP(模型上下文协议)相比,像 Playwright 这样的 MCP 服务器在每个会话中转储 21 个工具和 13,700 个 token。那是 7-9% 的上下文窗口在你做任何事之前就被消耗了。
技能仅在需要时加载文档。与 Claude Code 和 Codex 技能目录兼容。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/213687.html