
这个网站烂的一逼,大家没事可以搞一搞它。今天我们试着爬取一下网站内容,回头交给网监×××姐。
1.首先我们观察大嘴巴巴最大的色请板块“轻松一刻”的URL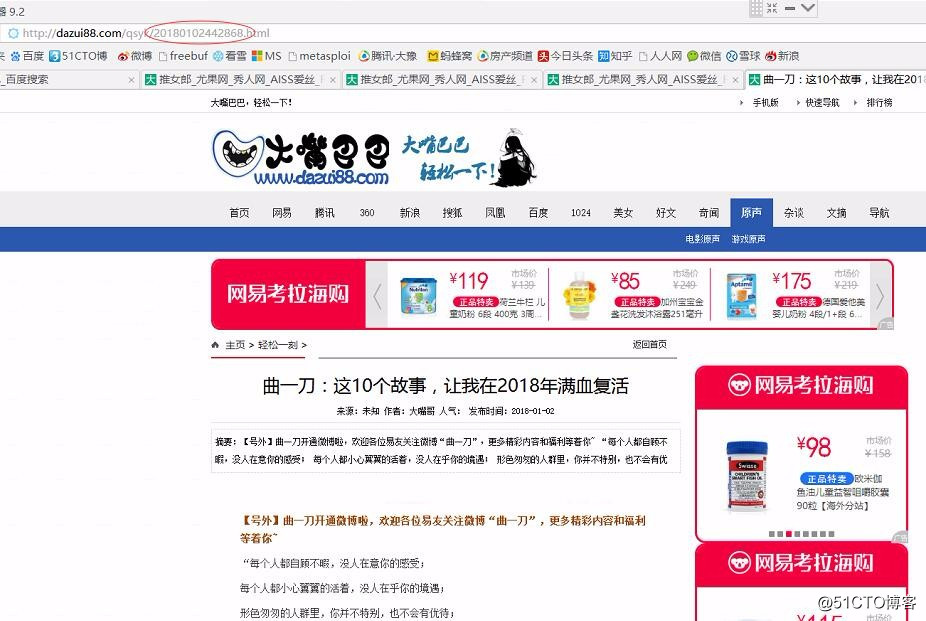
讯享网
2.发现下面规律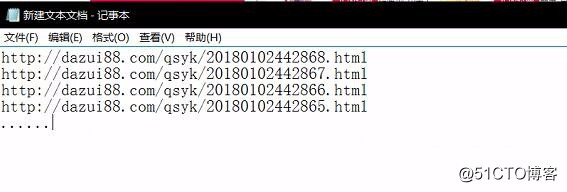
3.然后编辑下面代码
-*- coding:utf-8 -*- import urllib2 def load_page(url): ''' send url return html_page ''' user_agent = "User-Agent:Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0;" headers = {
"User-Agent":user_agent}
req = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(req)
html = response.read()
return html
def write_to_file(file_name,txt): ''' put txt into file_name ''' print "writing file" + file_name f = open(file_name,'w') f.write(txt) f.close def tiaba_spider(url,begin_page,end_page): ''' fuck dazuibaba ''' for i in range(begin_page,end_page + 1): pn = - i ''' http://dazui88.com/qsyk/20180102442869.html http://dazui88.com/qsyk/20180102442868.html http://dazui88.com/qsyk/20180102442867.html ........ i = 1 ,pn = 442870 -1 = 442869 ''' dazui88_url = url + str(pn) + '.html' #print "dazui88'url:" #print dazui88_url
html = load_page(dazui88_url)
#print "================%d==================" %(i) #print html #print "====================================" file_name = str(i) + ".html"
write_to_file(file_name,html)
#main if __name__ == "__main__": url = raw_input("please input dazui88'URL:") #print url begin_page = int(raw_input("please input begin_page:")) end_page = int(raw_input("please input end_page:")) #print begin_page #print end_page tiaba_spider(url,begin_page,end_page)讯享网
4.然后执行python fuck-dazui88.py测试一下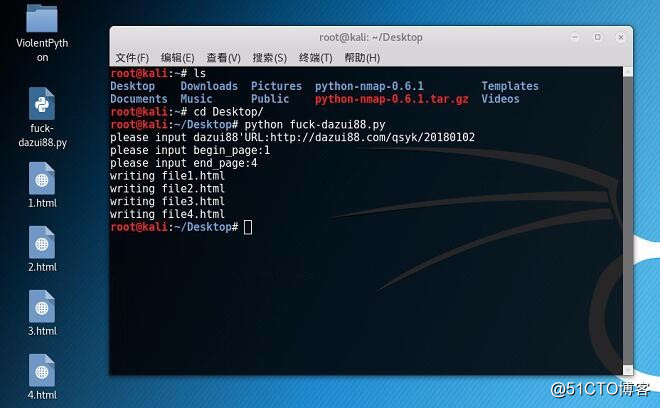

5.成功爆夏主任菊花一次,可以愉快的去找网警×××姐举报他了:)
本文转自文东会博客51CTO博客,原文链接http://blog.51cto.com/hackerwang/如需转载请自行联系原作者
谢文东666
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/21344.html