
1 变量选择过程介绍
对于数据挖掘来说,变量选择是一个很重要的过程,使用维归约来进行变量选择的好处是在能不降低预测能力的前提下,减少侯选变量的个数。本文将讲一下维归约的过程、维归约的方法以及实现这些方法的SAS过程步,主要包括VARCLUS,factor,princomp三个过程步,通过这三个过程步,我们可以将变量进行分组,然后通过选择组里几个重要的变量来代替整个组的变量,从而达到既减少侯选变量,又不降低预测能力的目的。
先讲一下一个完整的变量选择/维归约过程:

对于连续变量,步骤如下:
1 剔除缺失率大于X%的变量
2 剔除与目标变量相关性很小的侯选变量
3 无用OCA来保留那些有最高IV值和最低R2的变量
4 根据目标变量对侯选变量进行分箱操作,然后根据WOE和IV值对变量进行选择
5 根据协方差统计量对变量进行转换
6 对所有保留的有缺失值的变量进行缺失值标记(生成哑变量?)。
离散变量:
1 剔除与目标变量相关性最低的侯选变量
2 基于目标变量,对侯选变量进行分箱操作
3 根据WOE值和IV值选择最终的离散变量。
对于缺失率很高的变量,以及与目标变量相关性低的变量,我们可以用一般的统计方法来完成筛选。WOE和IV值请查阅相关文献,本文不作讲解。对哑变量的生成请查阅相关文献,本文也不作讲解。下面讲解的内容是通过VARCLUS过程步对变量进行分箱操作,然后根据R2(或1-R2)来对变量进行选择,主要是对VARCLUS过程步进行讲解。对于主成份分析primcomp和因子分析factor,网上的讲解已经很多,本文给出一些链接,这里就不作介绍了。
变量选择是一个很复杂的过程,本文只是讲解一些思路,在实际建模过程请灵活运用。
2 变量选择方法:Proc VARCLUS过程步
VARCLUS过程步的主要功能是将一组数值变量归类到不重叠的或重叠的群中,这样可以简化资料文件内的变量,使其不致过于繁复。
举例:
生成数据集:
data phys8(type=corr);
title 'Eight Physical Variables Measured on 305 School Girls';
title2 'See Page 22 of Harman: Modern Factor Analysis, 3rd Ed';
label height='height'
arm_span='arm span'
forearm='length of forearm'
low_leg='length of lower leg'
weight='weight'
bit_diam='bitrochanteric diameter'
girth='chest girth'
width='chest width';
input _name_ $ 1-9
(height arm_span forearm low_leg weight bit_diam girth width)
(8.);
_type_ = 'corr';
cards;
height 1.0 .846 .805 .859 .473 .398 .301 .382
arm_span .846 1.0 .881 .826 .376 .326 .277 .415
forearm .805 .881 1.0 .801 .380 .319 .237 .345
low_leg .859 .826 .801 1.0 .436 .329 .327 .365
weight .473 .376 .380 .436 1.0 .762 .730 .629
bit_diam .398 .326 .319 .329 .762 1.0 .583 .577
girth .301 .277 .237 .327 .730 .583 1.0 .539
width .382 .415 .345 .365 .629 .577 .539 1.0
;
run;
varclus过程步的语法如下:
PROC VARCLUS < options> ;
VAR 参与分析的数值变量名称 ;
SEED 定出各群的起始点(initial=seed;当initial=random,input,group时该指令无效) ;
PARTIAL 净化资料的变量名称 ;
WEIGHT 变量加权值,可为正有理数 ;
FREQ 变量加权值,只能为整数 ;
BY 分类变量,之前需要sort ;
选项说明:
第一类选项:得到资料
Data=输入资料文件名
Outstat=输出均值方差相关性等统计资料文件
Outtree=输出一个文件,供绘制树形图。当使用此选项时,SAS会同时界定hierarchy选项。
第二类选项:控制群的数目
Minclusters(minc)=正整数:指定最少要有几个群。
Maxclusters(maxc)=正整数:指定最多有几个群。
Proportion(percent)=正有理数:群主成份所能解释的变异数百分比。注意,这里proportion=0.75与percent=75是一样的。
Maxeigen=实数:规定每个群内第二特征值的最大可能值。
第三类选项:控制群形成的方法
Covariance(cov):SAS分析一个变异数/共变异数的矩阵,而非相关系数矩阵

Initial=(random,seed,input,group):指定方法展开群分析
Centroid:导出群的重心成份而非主成份,不能与maxeigen选项合用。
Maxiter:分析过程循环的最高次数。
Hierarchy(HI):要求SAS用层次聚类法。
Multiplegroup(MG):选用此项时,输入资料文件必须是type=corr,ucorr,cov,ucov,sscp或factor中的一种。
Random=随机数
Noint:不考虑截距
Vardef=df:界定计算变异数或共变异数时所用的分母。其中DF为自由度,N为总观测数,WGT为加权观测总数,WDF=WGT-1
第四类选项:控制统计值的打印
Simple(s):打印每一变量的平均数与标准差
Corr(c):打印变量间的相关系数矩阵
第五类选项:控制输出资料的打印
Short:不打印群结构、线性组合系数以及群间相关系数
Summary:只打印总结论表
Noprint:结果都不打印
Trace:打印每次循环过程中各变量所属的群。
运行varclus过程步:
proc varclus data=phys8 outtree=tree;
run;
结果及解释:

Varclus过程步已将8个变量划分为两个群,对于每个群的变量,我们可以挑出几个变量即可,这种方式可以减少很多侯选变量。
挑选变量的原则如下:
选择IV值最大的变量
选择1-R平方最小的变量
选择业务解释性好的变量。
本例中,对于群1,我们可以选择变量arm_span,因为其1-R2最小。由于本例的业务解释方面不突出,因此不作业务变量选择。这里我们不对IV值进行说明,大家可以查阅相关文献(关键词information value)
proc tree;
height _propor_;
run;
结果:
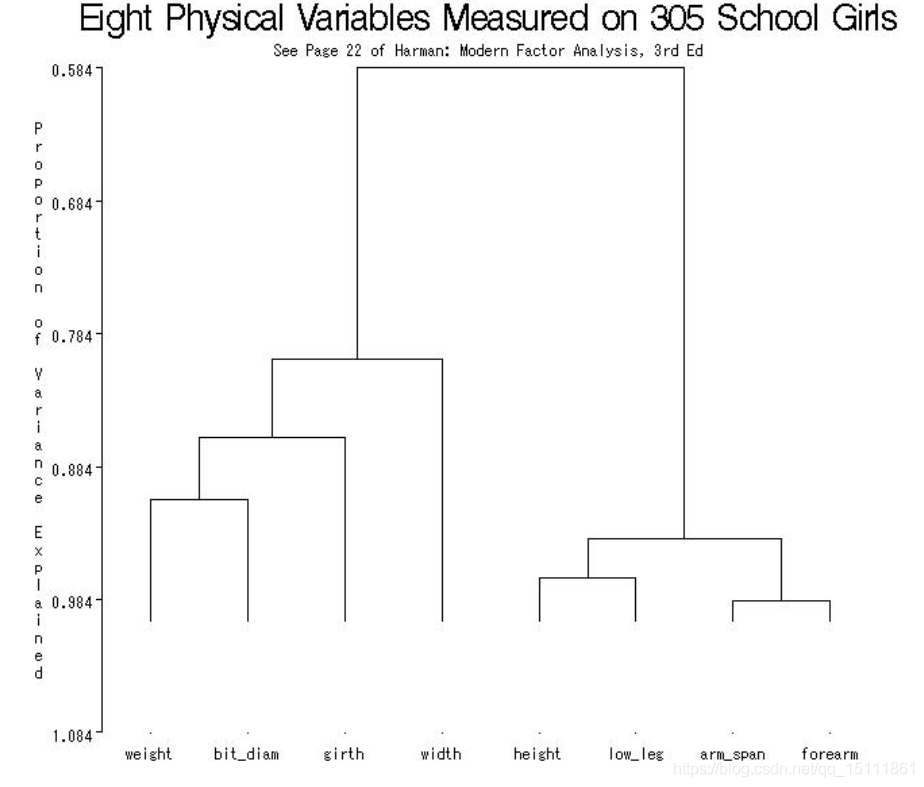
这里我们可以看到,很明显地将八个变量分为两个群,并且还可以更直观地看到各个变量间的相似度。
3 因子分析factor和主成份分析princomp
详见:
实验十 主成份分析——primcomp过程
http://eme.gdcc.edu.cn/sas/item10.htm
实验十一 因子分析——Factor过程
http://eme.gdcc.edu.cn/sas/item11.htm
其它
http://houjianzhong5.spaces.live.com/Blog/cns!ECC9D8258DADF20!155.entry
4 变量选择最终建议Summary, Conclusions and Recommendations
Apply the Unger and Hansch recommendations:
1. Selection of meaningful variables:选择业务解释意义好的变量
2. Elimination of interrelated variables:剔除指标间相关性高的变量
3. Justification of variable choices by statistics:通过统计值对变量进行选择
4. Principle of parsimony (Ockham‘s Razor):吝啬原则:对于一个有效的预测,模型的参数越多,参数估计的有效性就越差。换句话,通常我们选择一个简单模型描述对象。
5. Number of variables to choose from:可选择的变量数
6. Number of variables in the model:进入模型的变量数
7. Qualitative biophysical model:定性生物物理模型(什么意思,不太明白)
Additional recommendations:
8. Beware of Q2 (Alex Tropsha):http://www.ncbi.nlm.nih.gov/pubmed/
9. Search for outliers in the test set:注意异常值
10. Do not expect your model to be predictive:别抱太大希望
参考文献:
VARCLUS DOCUMENTATION EXAMPLE
ftp://ftp.sas.com/techsup/download/sample/samp_lib/statsampVarclus_Documentation_Example.html
Variable Selection in the Credit Card Industry
http://www.nesug.org/proceedings/nesug06/an/da23.pdf
Variable Selection and Model Validation
http://www.kubinyi.de/dd-13.pdf
第九部分 集群分析
http://www.sasfans.com/main/Article/UploadFiles/RaSasIntroduction9.pdf
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/21220.html