
<p><img alt="" height="1200" src="https://i-blog.csdnimg.cn/blog_migrate/94fa6bb3cbaa91a67ad05e60b0.png" width="676" /></p> 讯享网
网络中的亮点:
1.超深的网络结构(超过1000层)
2.提出residual(残差)模块
3.使用Batch Normalization加速训练(丢弃dropout)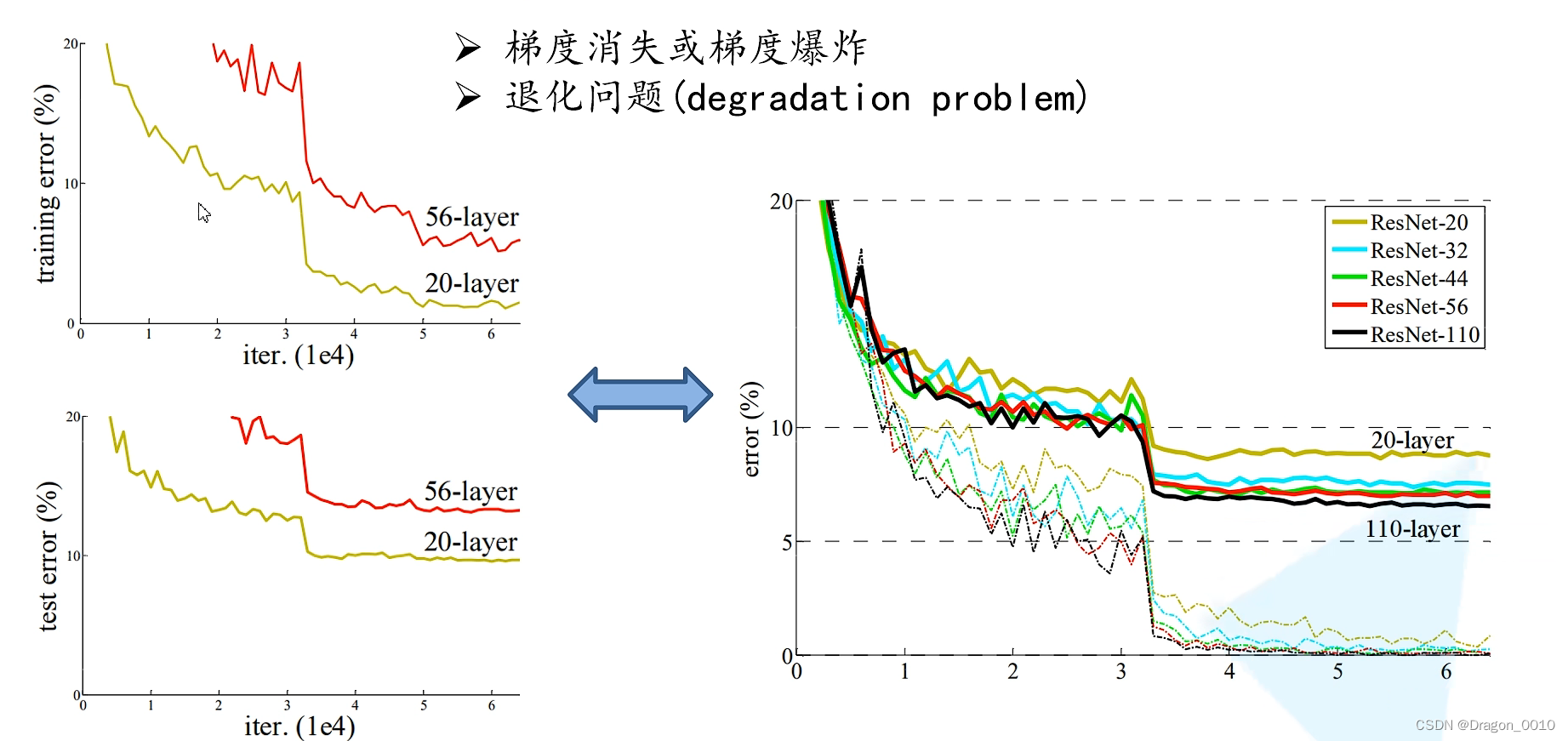
讯享网
左边是将卷积层和池化层进行一个简单的堆叠所搭建的网络结构
20层的训练错误率大概在1%~2%左右
56层的训练错误率大概在7%~8%
所以通过简单的卷积层和池化层的堆叠,并不是层数越深训练效果越好
随着网络层数不断地加深,梯度消失和梯度爆炸这个现象会越来越明显:
假设我们每一层的误差梯度是一个小于1的数,那么在我们的反向传播过程中,
每向前传播一次,都要乘以一个小于1的系数,当我们网络越来越深的时候,结果就越趋近于0
这样梯度就会越来越小
假设误差梯度是一个大于1的数,最后会发生梯度爆炸
通常解决梯度消失和梯度爆炸问题的方法:
标准化处理,权重初始化,BN(Batch Normalization)
退化问题:
在我们解决了梯度消失和梯度爆炸问题后,我们仍然会存在层数深的效果不如层数浅的效果的问题
提出了残差结构:

左边的残差结构主要是针对于网络层数较少的网络所使用的残差结构(ResNet-34)

主线是通过2个3*3的卷积层得到我们的一个结果,右边有一条弧线从输入连接到输出
将卷积之后的特征矩阵与我们输入的特征矩阵进行相加,相加之后再通过Relu激活函数
能相加就要求主分支和侧分支(shortcut)的输出特征矩阵shape必须相同(shape:高,宽,channel)
右边是针对网络层数较多的网络(50/101/152)
主线是先通过一个1*1的卷积层(降维),再通过一个3*3的卷积层,再通过一个1*1的卷积层(升维)
通过两个网络所需参数的对比可以发现,残差结构越多,所节省的参数越多
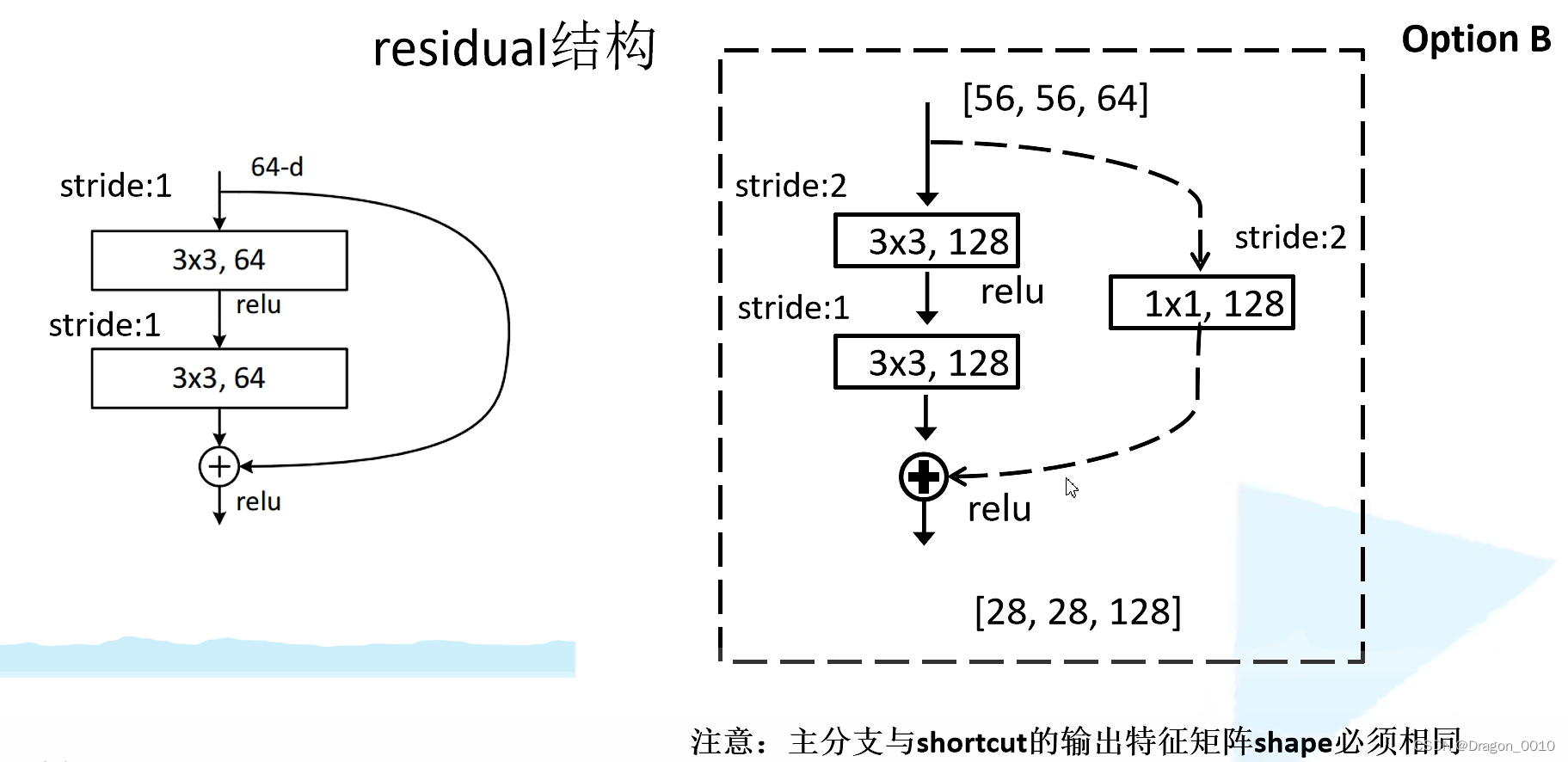
左边的实线部分,输入的特征矩阵与输出的特征矩阵shape相同,所以可以直接相加
右边虚线输入与输出shape不同
Batch Normalization
目的是使我们的一批(Batch)数据所对应的feature map(特征矩阵)每一个维度(channel)满足均值为0,方差为1的分布规律
通过该方法能够加速网络的收敛(训练)并提升准确率
对于一个拥有d维的输入x,我们将对它的每一个维度进行标准化处理
假设我们输入的x是RGB三通道的彩色图像,这里的d就是图像的channels,即d=3

使用BN时,在训练时将trainning参数设置为True,在验证时将trainning设置为False
将BN层放在卷积层和激活层的中间
迁移学习的简介
优势:
1.能够快速的训练出一个理想的结果(训练的epoch较少)
2.当数据集较少时也能训练出理想的结果

注意:使用别人的预训练模型参数时,注意别人的预处理方式
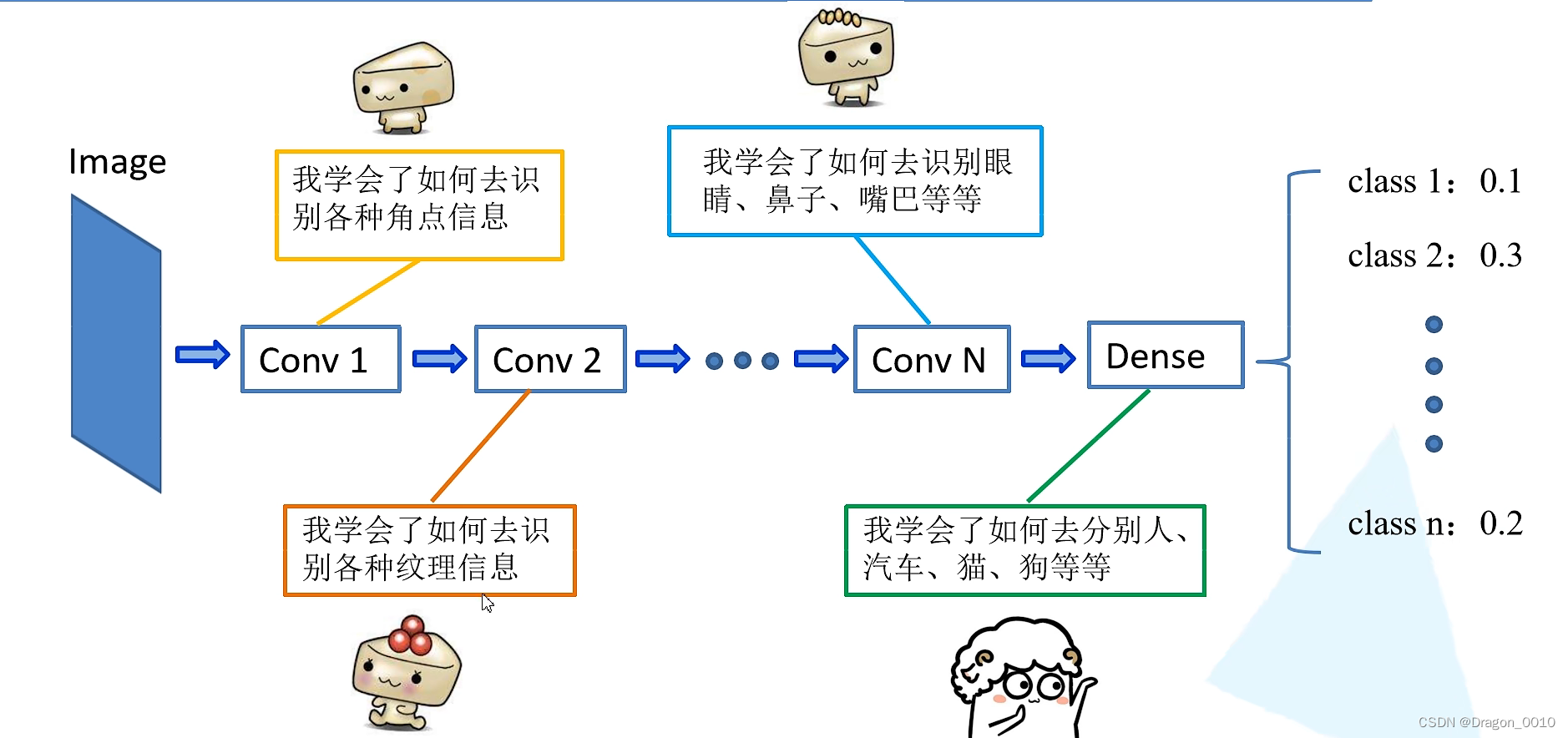
迁移学习就是将学习好的一些浅层网络的参数迁移到我们新的网络当中来
这样我们新的网络也有了识别底层通用特征的能力了
常见的迁移学习方式:
1.载入权重后训练所有参数
2.载入权重后只训练最后几层参数
3.载入权重后再原网络的基础上在添加一层全连接层,仅训练最后一个全连接层
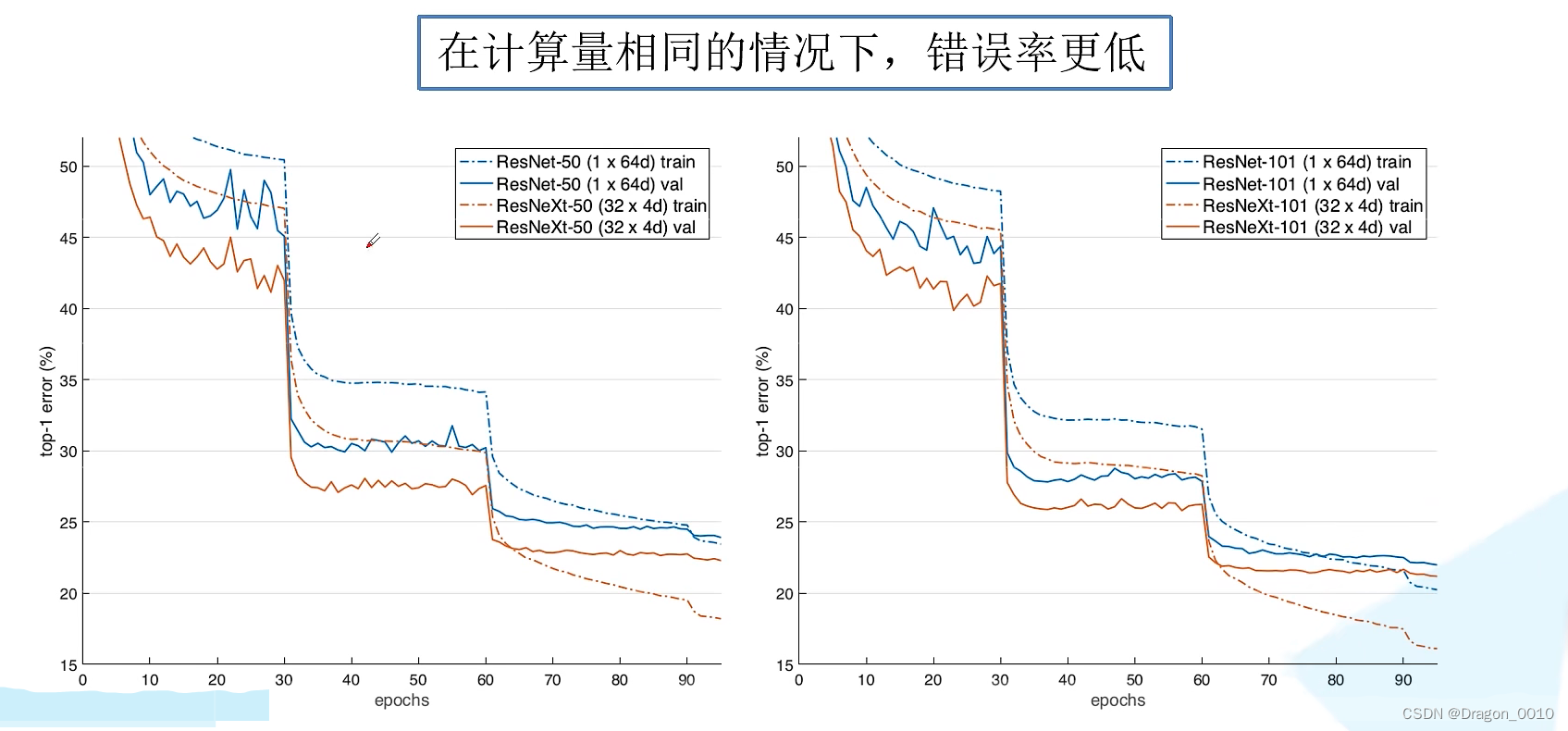
ResNext
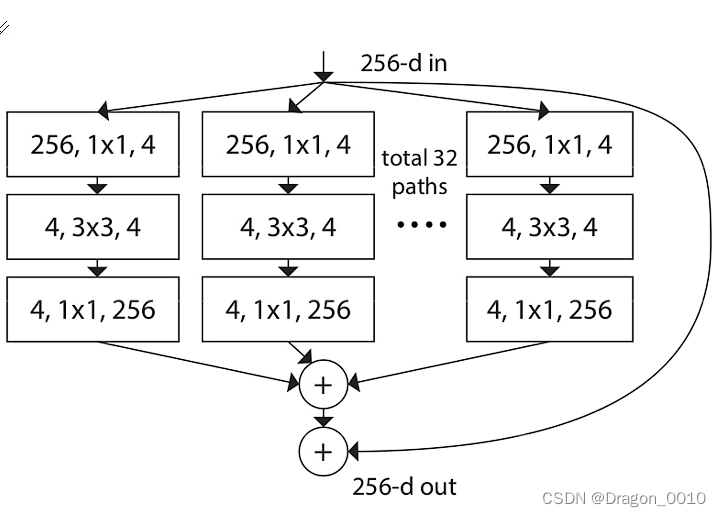
 组卷积
组卷积
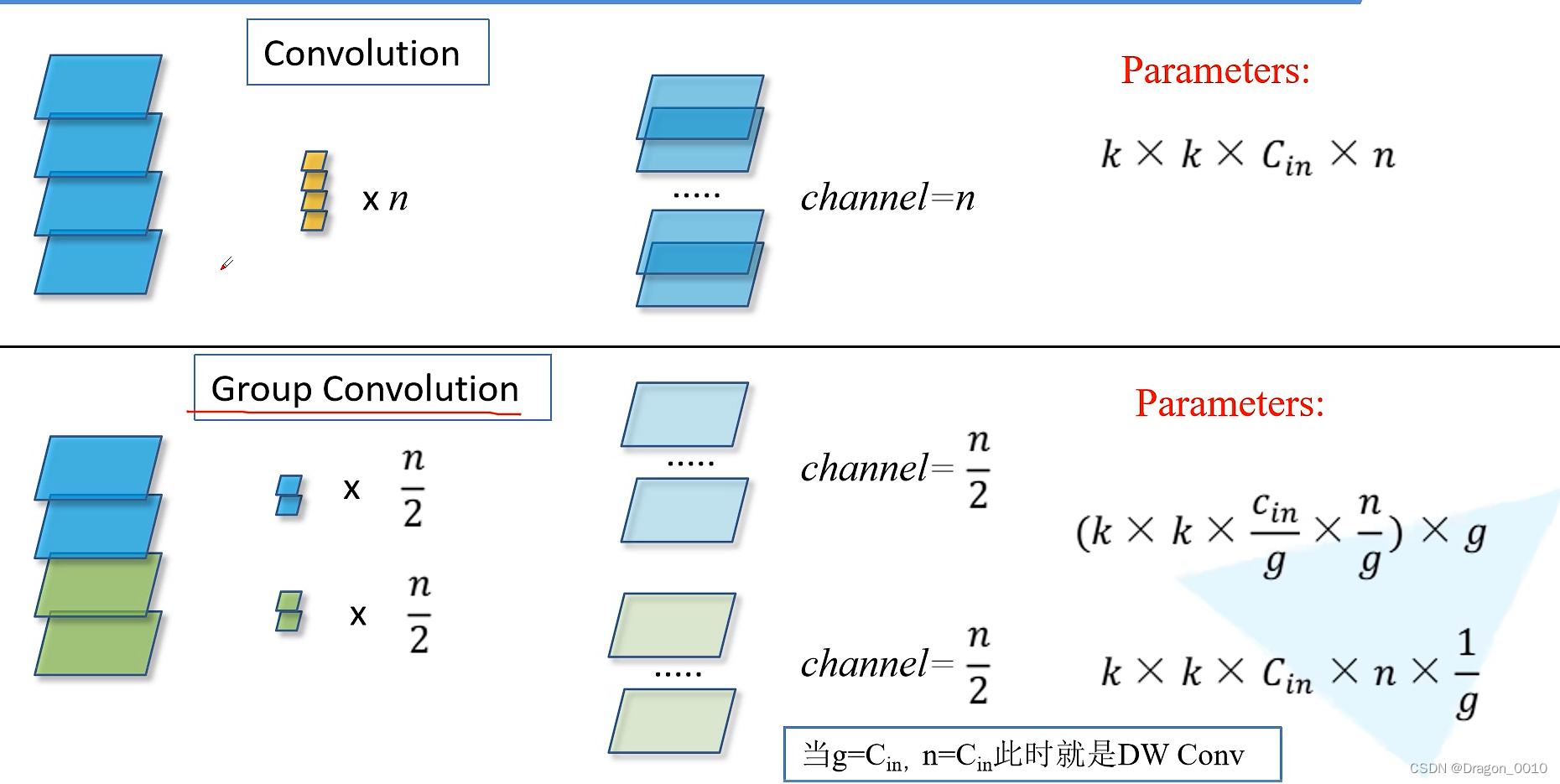
g是组数
代码实现
网络搭建
讯享网
训练模块
训练结果
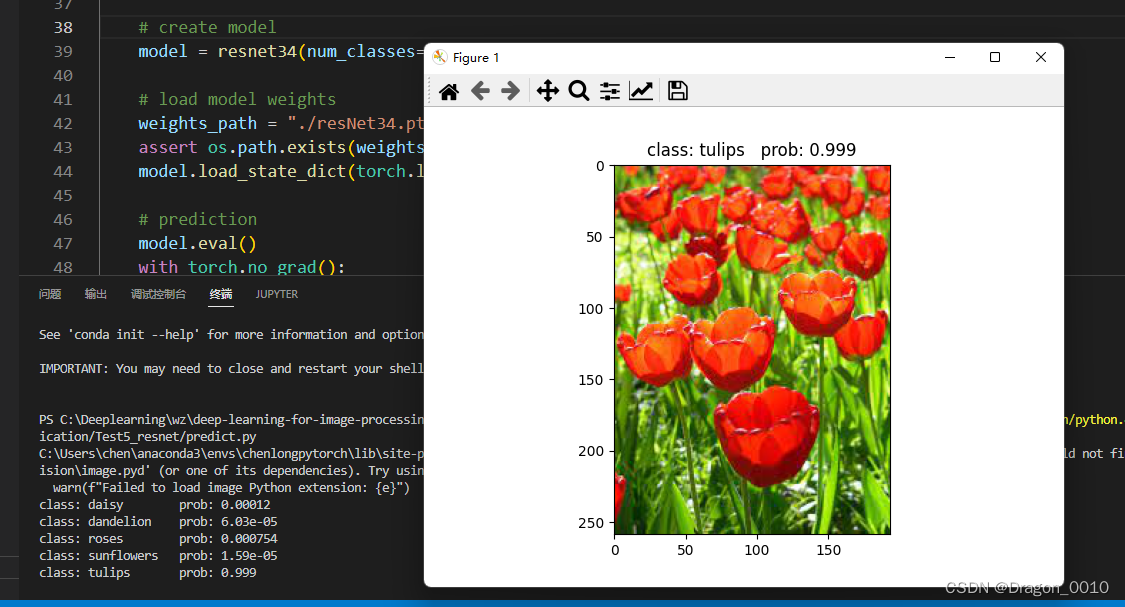
预测模块
讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/197695.html