
数据挖掘期末复习提纲
什么是数据挖掘
Opinion1:
数据中的知识发现(KDD)
Opinion2:
广义定义:
可以挖掘什么样的数据?
数据库数据、数据仓库数据和事务数据
二元属性的邻近性度量
对于二元属性的列联表:

对称的二元相异性:
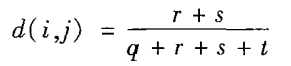
非对称的二元相异性:
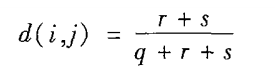
非对称的二元相似性(又称Jaccard系数):
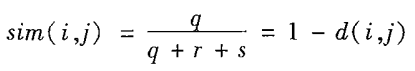
简单匹配系数:
s m ( i , j ) = q + t / q + t + r + s sm(i,j)=q+t/q+t+r+s sm(i,j)=q+t/q+t+r+s
数值属性的相异性
闵可夫斯基距离
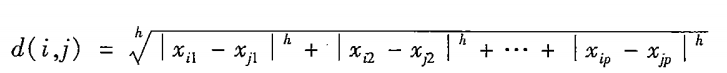
当h=1时,该式为曼哈顿距离
当h=2时,该式为欧几里得距离
当h➡∞时,该式为切比雪夫距离
数据预处理
数据预处理的目的:提高数据质量
(数据质量用准确性、完整性、一致性、时效性、可信性和可解释性定义)
数据预处理主要包括:数据清理、数据集成、数据归约和数据变换
数据清理
通过填写缺失值、光滑噪声数据、识别或删除离群点并解决不一致来清理数据
缺失值的处理
- 忽略元组(缺少类标号时通常这么做)
- 人工填写缺失值(费时费力,且数据集较大时不可行)
- 使用一个全局常量填充缺失值(例如用’Unknown’替换所有缺失值,简单但不可靠)
- 使用属性的中心度量(如均值或中位数)填充缺失值(正常数据可以用均值,倾斜数据中最好使用中位数)
- 使用与给定元组属同一类的所有样本的属性均值或中位数(看不懂来问我)
- 使用最可能的值填充缺失值(回归、贝叶斯形式化方法)
分箱
分箱的目的:对数据进行局部光滑
基于等频划分的两种分箱方法
先排序后等分,保证每个箱中包含的值的数量相等
用箱均值光滑
用箱边界光滑
给定箱中的最大和最小值被视为箱边界,将箱中每一个值都替换为最近的箱边界
等宽划分
每个分箱取值范围一样大
数据集成
将不同来源的数据进行集成处理,要注意采取措施避免集成时的冗余:例如代表同一概念的属性在不同的数据库中可能具有不同的名字,导致不一致和冗余
冗余和相关分析
分为标称数据的冗余和相关分析以及数值数据的冗余和相关分析
标称数据:卡方检验
Pearson卡方值公式:
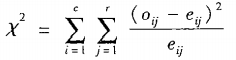
e i e_i ei j _j j是期望频度
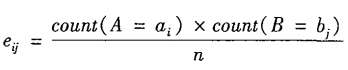
书上方便理解的例子:

数值数据:相关系数
公式以及解释:

相关系数取值在-1到1之间,相关系数大于0,意味着A和B是正相关的,如果该值等于0,则A和B是独立的。
(注意!相关性并不蕴含因果关系!)
数值数据:协方差
协方差的公式:
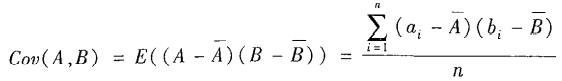
协方差与相关系数的联系:
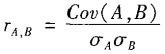
(方差是协方差的特殊情况,即属性与自身的协方差)
数据归约
维规约:减少随机变量或属性的个数
数据压缩技术(小波变换和主成分分析)
属性子集选择(去掉不相关的属性)
属性构造(从原来的属性集导出更有用的小属性集)
数值规约:用替代的/较小的数据替换元数据
数据压缩
使用变换,以便得到原数据的归约或’压缩’表示。如果原数据能从压缩后的数据重构,称该数据归约为有损的,如果只能近似重构原数据,则称该数据归约为’有损的’.
数据变换
目的:将数据变换或统一成适合于挖掘的形式。
数据变换策略:
- 光滑:去掉数据中的噪声,包括分箱、回归和聚类。
- 属性构造:又称特征构造;由给定的属性构造新的属性并添加到属性集中,以帮助数据挖掘过程。
- 聚集:对数据进行汇总或聚集,如分类汇总、构造数据立方体。
- 规范化:详见下文。
- 离散化:将原始值用区间标签(如0-10,11-20,21-30)或概念标签(如youth,adult,senior)替换。
- 由标称数据产生的概念分层:如street,可以泛化到较高的概念层,比如city或country。
三种规范化变换数据
最小-最大规范化
可以将A的值映射到 n e w new new_ m a x A max_A maxA到 n e w new new_ m i n A min_A minA的区间上
特别地,当 n e w new new_ m a x A max_A maxA=1, n e w new new_ m i n A min_A minA=0时,有公式:
z 分数规范化
减去均值除以标准差

小数定标规范化
公式如下:
其中j是使得 m a x ( ∣ v ′ i ∣ ) < 1 max(|v'i|) < 1 max(∣v′i∣)<1的最小整数
注意:上述的分类并不互斥,例如,冗余数据的删除既是一种数据清理,又是一种数据归约。
数据仓库
什么是数据仓库
数据仓库的四个特征

操作数据库系统与数据仓库的区别
二者的主要区别:

二者的其他区别:

多维数据模型
数据立方体
四维数据立方体:

数据立方体的方体格

多维数据模型的模式
星形模式

雪花模式(对星形模式的一些维表进行规范化)

事实星座模式(允许事实表共享维表)

典型的OLAP操作
上卷,下钻,切片和切块,转轴

(记得看课堂作业)
挖掘频繁项集
关联规则的度量
支持度和置信度公式:
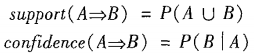
联系:
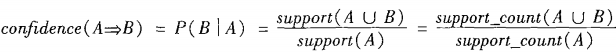
Apriori算法
看课本p162和作业
FP树
看课本p168和作业
相关分析
提升度
公式
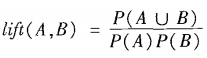
含义
提升度的值小于1,则A的出现和B的出现是负相关的,意味着一个出现可能导致另一个不出现;
提升度的值等于1,意味着A和B是独立的,即它们之间没有相关性;
提升度的值大于1,则A的出现和B的出现是正相关的,意味着一个出现可能蕴含着另一个的出现。
卡方分析
公式
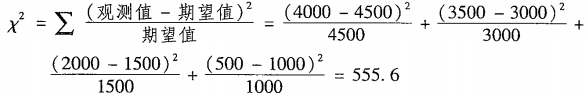
期望值的求法
根据总量的比值分配

全置信度
最大置信度
Kulc度量
余弦度量
决策树归纳
信息增益
熵
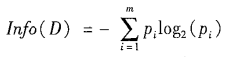
划分之后的分区的熵
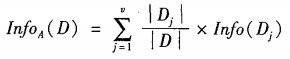
信息增益
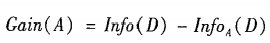
计算信息增益的例子(P218)
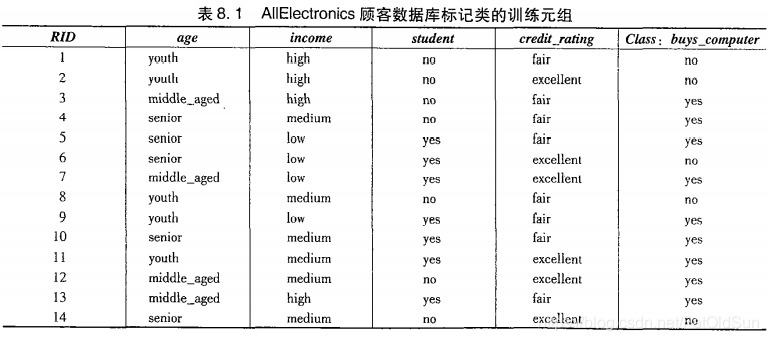
对D中元组分类所需要的期望信息:
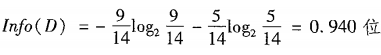
如果元组依据属性age进行划分,则对D中元组分类所需要的期望信息:
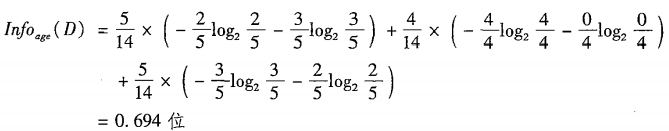
此种划分的信息增益:
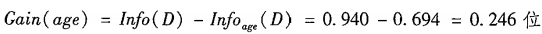
增益率(这个上课讲没讲过我也不知道…应该不考吧…)
分裂信息:
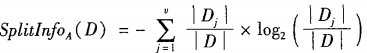
增益率:
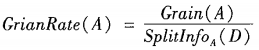
基尼指数
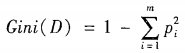
划分之后的分区的基尼指数
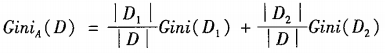
属性A的二元划分导致的不纯度降低
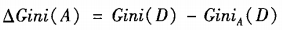
(别忘了看看课堂作业)
树的剪枝
先剪枝
后剪枝
神经网络
看课本p263和课堂作业
聚类算法
什么是聚类分析?
聚类是把一个数据对象(或观测)划分成子集的过程。
对聚类分析的要求













总结:

K-均值、K-中心点聚类
课本p293,作业刚做过
凝聚和分裂
结合PPT
距离度量
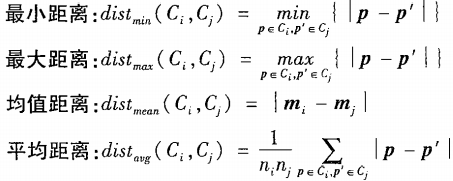
其中,均值距离是先求组内平均,再计算距离;
平均距离是先一一计算距离,再求距离的平均

聚类质量的测定
轮廓系数
轮廓系数是一种内在的聚类质量的测定度量。
轮廓系数的取值范围在-1和1之间。
轮廓系数越大,认为聚类的质量越高。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/118339.html