
网页分析
目标爬取这两页的图片
讯享网
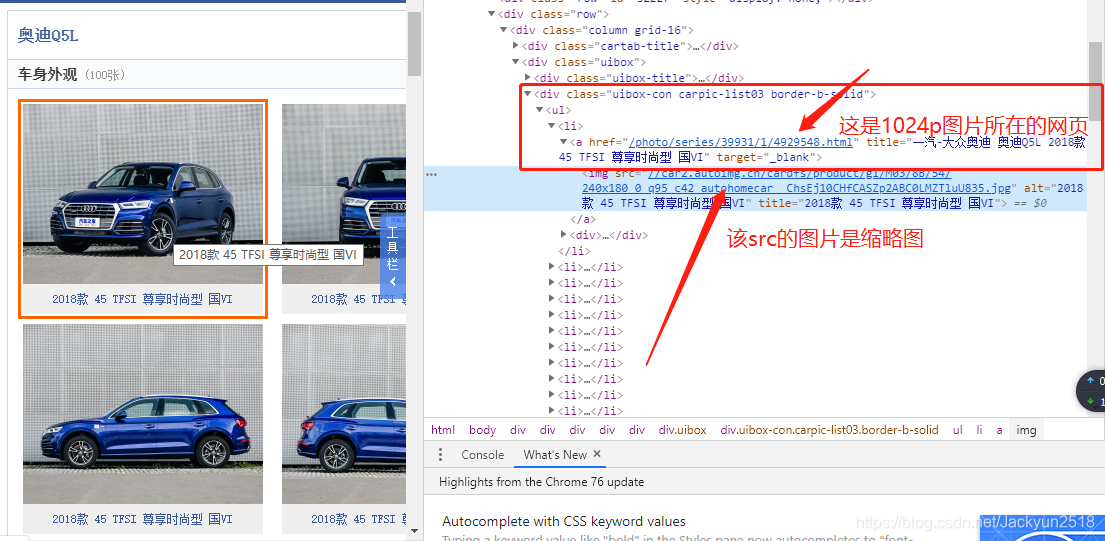

总的抓取思路是:从该网页http://car.autohome.com.cn/pic/series/4851-1.html中找到大图(不是缩略图)所在的位置,得到大图所在的网页:http://car.autohome.com.cn/photo/series/39931/1/4929548.html,接着定位图片所在位置,这是定位目标图片的过程,定位之后下一步解析图片,然后保存图片。

代码实现
imrequests
from lxml import etree
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
urls = ['http://car.autohome.com.cn/pic/series/4851-1-p{}.html'.format(str(i)) for i in range(1,3)]
path = 'F:\\pythonLearning\\patu\\01carcarcar\\'
def get_imges(url):
req = requests.get(url, headers = headers).text
html = etree.HTML(req)
for link in html.xpath('//div[@class="uibox-con carpic-list03 border-b-solid"]/ul/li/a/@href'):
img_url = "http://car.autohome.com.cn"+link
get parse_img_url(img_url)
def parse_img_url (url):
reqs = requests.get(url, headers = headers).text
html2 = etree.HTML(reqs)
for item in html2.xpath('//div[@class="pic"]/img[@class="img"]/@src'):
item_url = "http:"+item
download_imge(item_url)
def download_imge (url):
data = requests.get(url, headers = headers)
try:
with open(path + url[-8:], 'wb') as f:
f.write(data.content)
except Exception as e:
print(e)
time.sleep(1)
if __name__ == " __main__":
for url in urls:
get_imges(url)
讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/70528.html