
1、矩阵转置
需要将 N * M 的矩阵转置为 M * N 的矩阵
采用统一内存,配置dimgrid和dimblock为
dim3 dimGrid((M + BLOCK_SIZE - 1)/BLOCK_SIZE, (N + BLOCK_SIZE -1)/BLOCK_SIZE); dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);讯享网
1.1 读访存合并
讯享网__global__ void gpu_matrix_transpose(int in[N][M], int out[M][N]) { int tidx = threadIdx.x + blockIdx.x * blockDim.x; int tidy = threadIdx.y + blockIdx.y * blockDim.y; if(tidx < M && tidy < N) { out[tidx][tidy] = in[tidy][tidx]; } }
循环20次时间为7.96 ms
1.2 写访存合并
__global__ void gpu_matrix_transpose(int in[N][M], int out[M][N]) { int tidx = threadIdx.x + blockIdx.y * blockDim.y; int tidy = threadIdx.y + blockIdx.x * blockDim.x; //写访存合并 if(tidy < M && tidx < N) { out[tidy][tidx] = in[tidx][tidy]; } }循环20次时间为8.75 ms,时间比读访存合并要慢,原因是架构不支持__ldg()指令,若支持,程序读取的数据若是只读,会采用只读缓存改善非合并访存。
1.3 引入shared_memory,读写访存合并
讯享网__global__ void gpu_shared_matrix_transpose(int in[N][M], int out[M][N]) { int bidx = blockIdx.x * blockDim.x; int bidy = blockIdx.y * blockDim.y; int tidx = threadIdx.x + bidx; int tidy = threadIdx.y + bidy; __shared__ int smem[BLOCK_SIZE][BLOCK_SIZE]; if(tidx < M && tidy < N) { smem[threadIdx.y][threadIdx.x] = in[tidy][tidx]; } __syncthreads(); tidx = threadIdx.x + bidy; tidy = threadIdx.y + bidx; if(tidx < N && tidy < M) { out[tidy][tidx] = smem[threadIdx.x][threadIdx.y]; } }
循环20次时间为7.15 ms,存在bank冲突,对于开普勒架构来说,每个bank的宽度是8字节,对于非开普勒架构来说,每个bank的宽度是4字节。
对于 bank 宽度为 4 字节的架构,共享内存数组是按如下方式线性地映射到内存 bank 的: 共享内存数组中连续的 128 字节的内容分摊到 32 个 bank 的某一层中,每个 bank 负责 4 字 节的内容。例如,对一个长度为 128 的单精度浮点数变量的共享内存数组来说,第 0-31 个 数组元素依次对应到 32 个 bank 的第一层;第 32-63 个数组元素依次对应到 32 个 bank 的 第二层;第 64-95 个数组元素依次对应到 32 个 bank 的第三层;第 96-127 个数组元素依次 对应到 32 个 bank 的第四层。也就是说,每个 bank 分摊 4 个在地址上相差 128 字节的数据
1.4 解决bank冲突
__global__ void gpu_shared_matrix_transpose(int in[N][M], int out[M][N]) { int bidx = blockIdx.x * blockDim.x; int bidy = blockIdx.y * blockDim.y; int tidx = threadIdx.x + bidx; int tidy = threadIdx.y + bidy; __shared__ int smem[BLOCK_SIZE][BLOCK_SIZE+1]; if(tidx < M && tidy < N) { smem[threadIdx.y][threadIdx.x] = in[tidy][tidx]; } __syncthreads(); tidx = threadIdx.x + bidy; tidy = threadIdx.y + bidx; if(tidx < N && tidy < M) { out[tidy][tidx] = smem[threadIdx.x][threadIdx.y]; } }循环20次时间为4.95 ms
2、reduce操作
对于reduce来说,分为两个阶段,在每个block上reduce完,剩下blockDim个数据,有三种解决办法
1. 再起一个kernel
2. 原子操作(如atomicAdd(&dy, x))
3. 在cpu端计算
2.1 reduce baseline
讯享网__global__ void reduce0(float *d_in,float *d_out){ __shared__ float sdata[THREAD_PER_BLOCK]; // each thread loads one element from global to shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = d_in[i]; __syncthreads(); // do reduction in shared mem for(unsigned int s=1; s < blockDim.x; s *= 2) { if (tid % (2*s) == 0) { sdata[tid] += sdata[tid + s]; } __syncthreads(); } // write result for this block to global mem if (tid == 0) d_out[blockIdx.x] = sdata[0]; }
有warp divergent问题,在同一个warp不能全部执行if-else
58.75 ms
2.2 解决warp divergent
__global__ void reduce0(float *d_in,float *d_out){ __shared__ float sdata[THREAD_PER_BLOCK]; // each thread loads one element from global to shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = d_in[i]; __syncthreads(); // do reduction in shared mem for(unsigned int s=1; s < blockDim.x; s *= 2) { int index = 2 * s * tid; if (index < blockDim.x) { sdata[index] += sdata[index + s]; } __syncthreads(); } // write result for this block to global mem if (tid == 0) d_out[blockIdx.x] = sdata[0]; }有bank冲突问题,0号线程取位置0和位置1,写位置0,十六号线程取位置32和位置33,写位置32,产生2路bank冲突
44.03 ms
2.3 解决bank冲突
for循环逆序
讯享网__global__ void reduce0(float *d_in,float *d_out){ __shared__ float sdata[THREAD_PER_BLOCK]; // each thread loads one element from global to shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = d_in[i]; __syncthreads(); // do reduction in shared mem for(unsigned int s=blockDim.x/2; s > 0; s >>= 1) { if (tid < s) { sdata[tid] += sdata[tid + s]; } __syncthreads(); } // write result for this block to global mem if (tid == 0) d_out[blockIdx.x] = sdata[0]; }
此时线程0取位置0和位置128,对于同一个线程,取的位置是同一个bank,但是取数是按照warp取数的,一行一行取,所以没有冲突。
2.4 使用idle线程
__global__ void reduce3(float *d_in,float *d_out){ __shared__ float sdata[THREAD_PER_BLOCK]; //each thread loads one element from global memory to shared mem unsigned int i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsigned int tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; /// unsigned int i=blockIdx.x * blockDim.x + threadIdx.x; unsigned int tid=threadIdx.x; int stride = blockDim.x; for (int j = i; j < N; j += stride) y += d_in[j]; sdata[tid] = y; /// __syncthreads(); // do reduction in shared mem for(unsigned int s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }2.5 使用shfl指令
讯享网template <unsigned int blockSize> __device__ __forceinline__ float warpReduceSum(float val) { #pragma unroll for(int offset = blockSize/2; offset > 0; offset >>= 1) { val += __shfl_down_sync(0xffffffff, val, offset); } return val; } template <unsigned int blockSize, unsigned int NUM_PER_THREAD> __global__ void reduce7(float *d_in,float *d_out, unsigned int n){ float sum = 0; unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x * NUM_PER_THREAD * blockSize + threadIdx.x; #pragma unroll for(int iter = 0; iter < NUM_PER_THREAD; iter++) { sum += d_in[i+iter*blockSize]; } __shared__ float smem[WARP_SIZE]; const int laneId = threadIdx.x % WARP_SIZE; const int warpId = threadIdx.x / WARP_SIZE; sum = warpReduceSum<WARP_SIZE>(sum); if(laneId == 0) { smem[warpId] = sum; } __syncthreads(); sum = (threadIdx.x < blockDim.x / WARP_SIZE) ? smem[laneId] : 0; //__syncthreads(); if(warpId == 0) sum = warpReduceSum<blockSize / WARP_SIZE>(sum); if(threadIdx.x == 0) { d_out[blockIdx.x] = sum; } }
shfl指令



3、矩阵乘
主要思想是,对于一个算子的开发,首先第一步,去计算一下这个算子是IO瓶颈还是计算瓶颈,接着去优化算子,怎么看,需要计算出其的计算强度,计算强度定义如下:FLOPS / Bytes
即浮点运算次数与所需的数据量大小之比(其含义是在某段计算逻辑下,每搬运单位字节数据,需要进行的计算次数,也即 Flops Per Byte。)
若计算强度 >= 峰值算力 / 访存带宽,就能保证算力发挥出来
对于朴素的矩阵乘
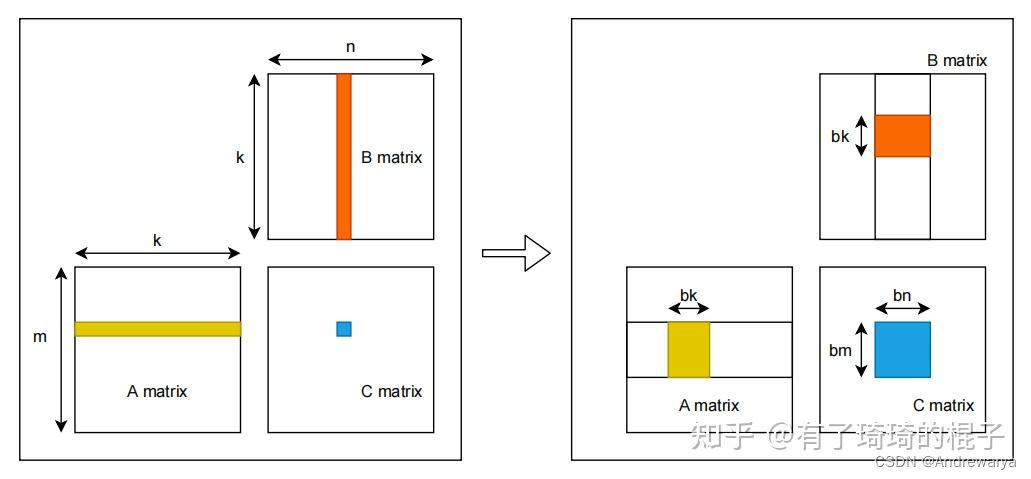 可以简单理解为所需要的访存量是 2*M*K*N,写访存量是M*N
可以简单理解为所需要的访存量是 2*M*K*N,写访存量是M*N
但是对于nv来说,其实会有访存合并的概念,M*N*(K + K/32),虽然一次memory transaction是32B,但是有L1 cache缓存。为了后续计算方便,默认是2*M*K*N的访存量。
从global memory到shared memory
为了提高计算强度,即减少重复的IO量,需要对矩阵分块,分成bm* bk ,bk * bn, bm * bn的小矩阵,此时访存量为:M/bm * B_size + N/bn * A_size = M*K*N/bm + M*K*N/bn
访存量是之前的1/2*(1/bm + 1/bn)倍
从shared memory到register
分析在K的迭代中,若依旧是一个线程负责一个点的计算,则从shared memory到register的访存量为2*bm*bk*bn,对矩阵再分块,rm*rk, rk*rn, rm*rn,则访存量为bm/rm * B_size + bn/rn * A_size = bm*bk*bn / rm + bm*bk*bn / rn
访存量是之前的1/2*(1/rm + 1/rn)倍
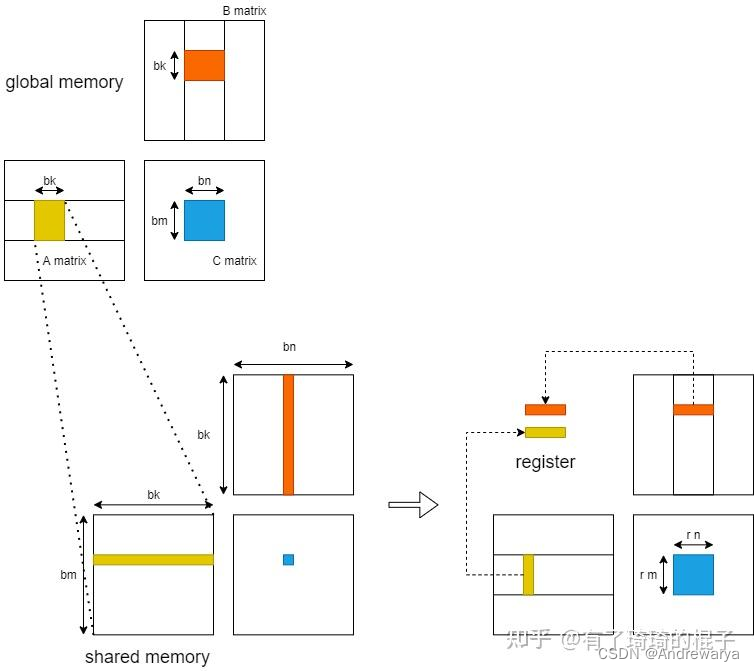
register分块
寄存器的bank conflict。在NV的GPU中,每个SM不仅会产生shared memroy之间的bank 冲突,也会产生寄存器之间的bank冲突。这一点对于计算密集型的算子十分重要。像shared memory一样,寄存器的Register File也会被分为几个bank,如果一条指令的的源寄存器有2个以上来自同一bank,就会产生冲突。指令会重发射,浪费一个cycle。PS:这个地方是从旷视的博客中看的。然后对于maxwell架构的GPU而言,bank数为4,寄存器id%4即所属bank。
FFMA R0, R16, R20, R0 FFMA R1, R16, R21, R1 ……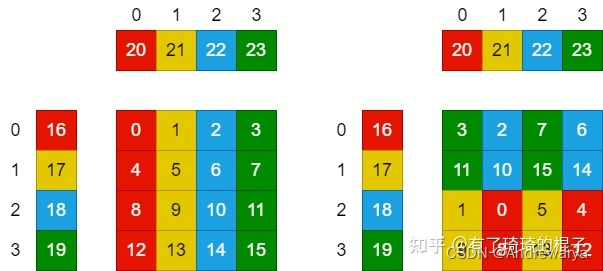
可以从中看出,这会产生大量的register bank冲突,所以需要对参与计算的寄存器重新进行分配和排布,如上图右侧所示。在有些地方,这种方式也可以叫做register分块。
数据prefetch
就是double buffer
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/67843.html