
一、模拟登陆
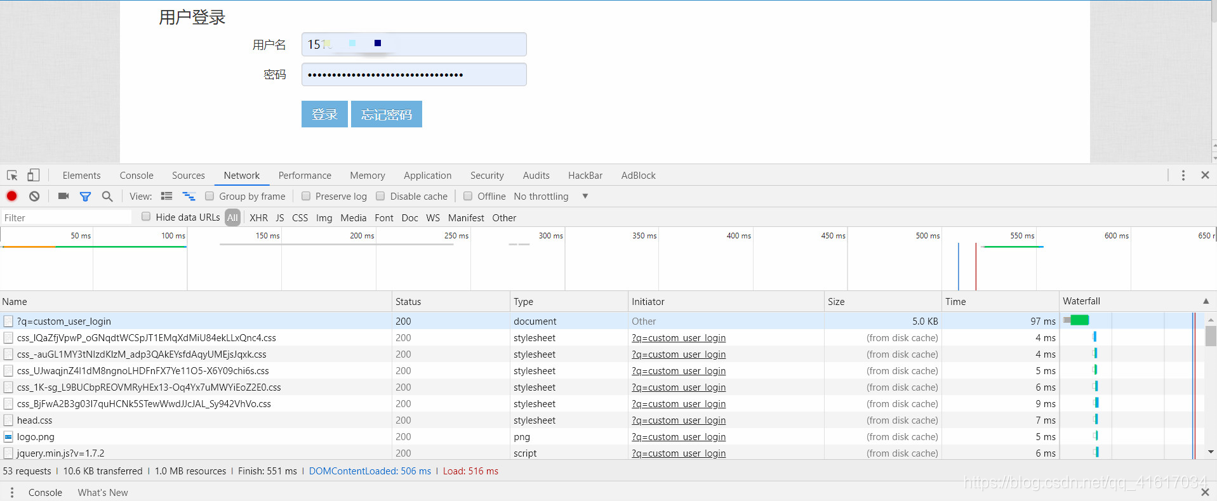
打开登陆界面,F12,打开开发者工具(大部分浏览器都自带),选择Network,如果没有显示,就把该页面刷新一下
我这里登陆的网站是 http://x.x.x.x/?q=custom_user_login
讯享网
输入账号,密码(这里我的密码填写的1,用做测试),原本很短的密码却变得很长,这里我们就有一个猜想,这里的password值在客户端进行了加密,所以我们右键审查该password表单元素
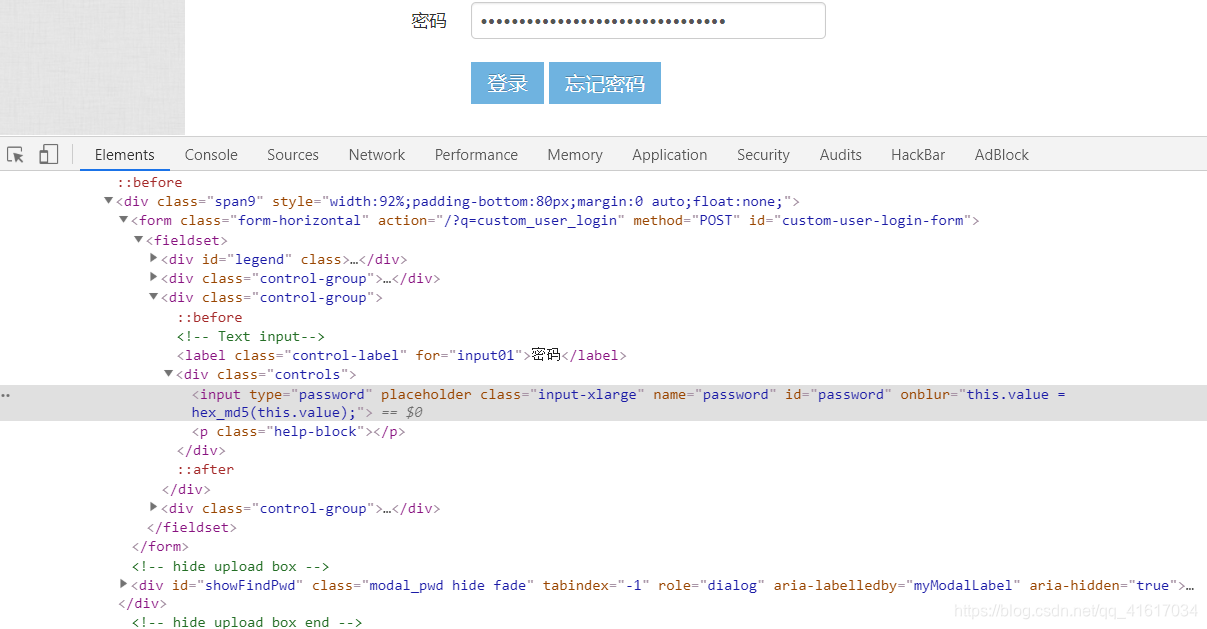
由上图可知这里果然进行了加密,于是我们把下图中type="password"的password删除,查看密码明文,看看他究竟是怎么进行加密的

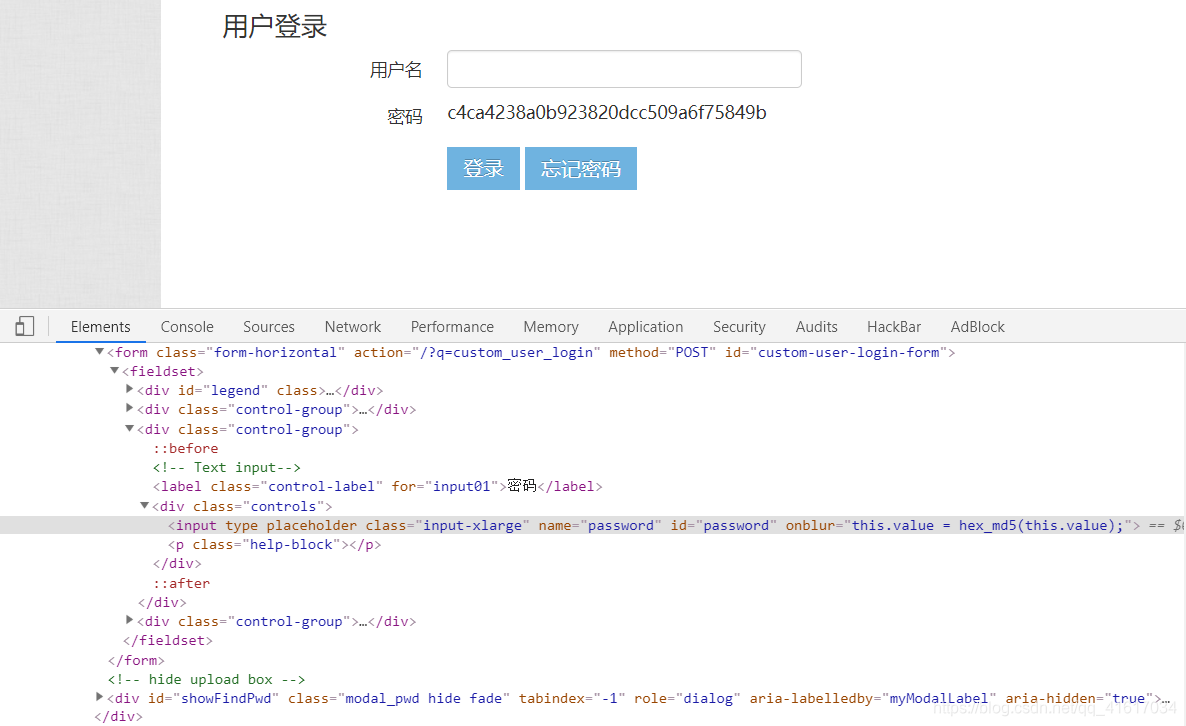
由上图看出1被加密成了32位16进制数,并且根据上图中的hex_md5,于是猜想他是md5加密,以hex(16进制)显示,在 https://www.cmd5.com/ 进行验证
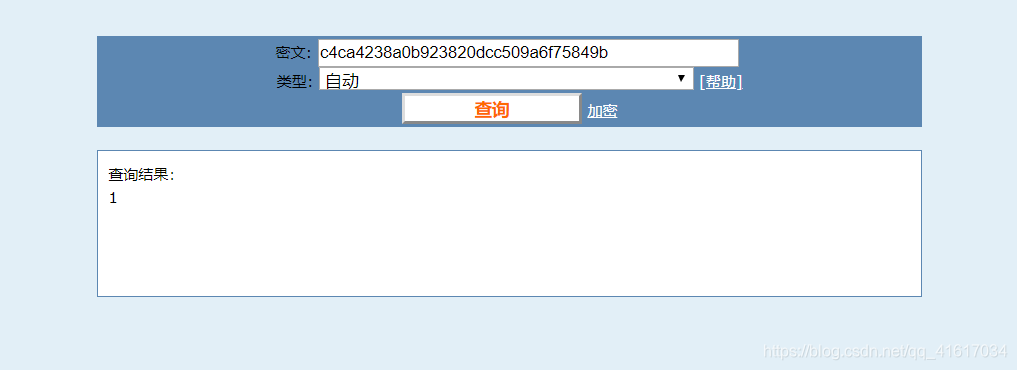
由上图可知,他果然是在前端进行了一次md5加密
随后我们进行一次正确的登陆,获取账号密的变量名,如下图:
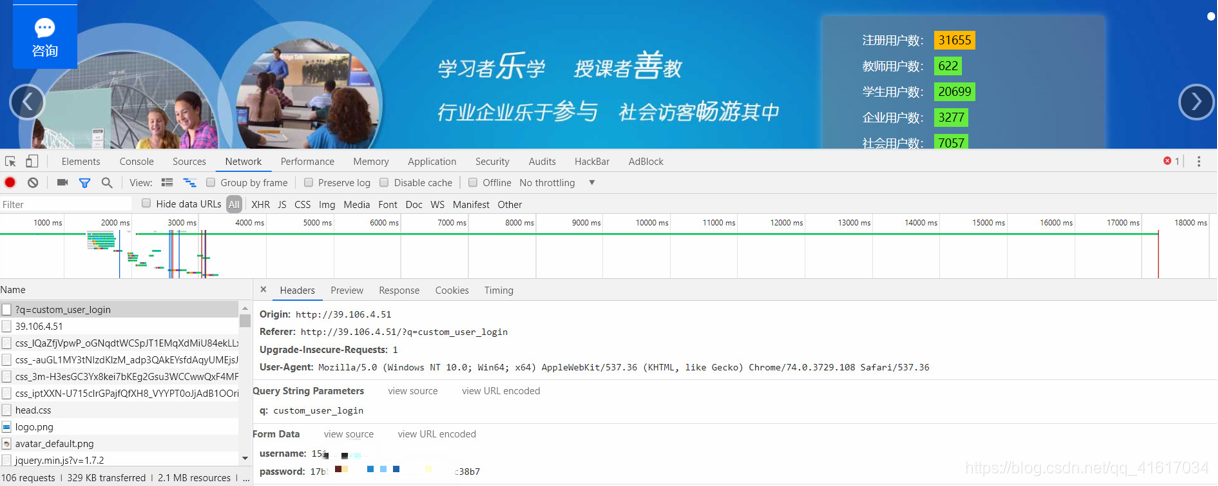
现在开始编写第一段代码,登陆账号:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author:1stPeak import requests import hashlib import re request = requests.Session() #requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies def login(username,password): login_url = "http://x.x.x.x/?q=custom_user_login" md = hashlib.md5() md.update(password.encode('utf-8')) password = md.hexdigest() data = {
"username": username, "password": password} try: req = request.post(login_url,data=data,headers=header) req.encoding = 'utf-8' #print(req.text) #这个用来测试是否登陆成功(查看登陆前与登录后的源代码有何差别) if "请输入注册时填写的手机号" not in req.text: print("登陆成功") else: print("登录失败") except: print("未知错误") if __name__ == '__main__': username="你的用户名" password="你的密码" header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"} login(username,password) 讯享网
二、申请课程
- 打开burpsuite,开始抓包,再点击报名学习

- 抓到下图的POST请求(申请课程请求)
请求url为/?q=node/75827/people/apply
- 输入url后打开
- 再打开 http://x.x.x.x/?q=node/75827, 检验是否申请成功
申请课程代码段:







讯享网apply_url="http://x.x.x.x/?q=node/75926/people/apply" req = request.get(apply_url,headers=header) #print(req.text) try: if "message" in req.text: print("申请成功") else: print("申请失败") except: print("未知错误")
为了可以申请更多的课程,我们修改一下代码:
def apply(): for i in range(75926,75927): apply_url = "http://x.x.x.x/?q=node/"+str(i)+"/people/apply" try: req = request.get(apply_url,headers=header) if "success" in req.text: print(str(i)+"课程申请成功") return i except: print(str(i) + "申请失败") 三、刷课程
讯享网study = "http://x.x.x.x/?q=items/student/study/75926" try: req = request.get(study, headers=header) req.encoding = 'utf-8' G = r'<a score=".*?" uid=".*?" title=".*?" class="itemtitle" nid=".*?" module_id=".*?" item_id=".*?" href="/(.*?)">.*?</a>' study = re.findall(G,req.text) for study_url_last in study: study_url_all = "http://39.106.4.51/" + study_url_last try: request.get(study_url_all,headers=header,timeout=4) print(study_url_all+"刷课成功") except: print(study_url_all+"刷课失败") except: pass
为了可以刷更多的课程,我们来完善一下代码:
def study(): study_url = "http://x.x.x.x/?q=items/student/study/"+str(apply()) try: req = request.get(study_url,headers=header) req.encoding='utf-8' G = r'<a score=".*?" uid=".*?" title=".*?" class="itemtitle" nid=".*?" module_id=".*?" item_id=".*?" href="/(.*?)">.*?</a>' study_url_list = re.findall(G,req.text,re.M|re.S) for study_url_last in study_url_list: study_url_all = "http://39.106.4.51/" + study_url_last try: req = request.get(study_url_all,headers=header,timeout=4) print(study_url_all+"学习完成") except: print(study_url_all+"学习失败") except: pass 四、完整代码:
讯享网#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author:1stPeak import requests import hashlib import re request = requests.Session() #requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies def login(username,password): login_url = "http://x.x.x.x/?q=custom_user_login" md = hashlib.md5() md.update(password.encode('utf-8')) password = md.hexdigest() data = {
"username": username, "password": password} try: req = request.post(login_url,data=data,headers=header) req.encoding = 'utf-8' #print(req.text) #这个用来测试是否登陆成功(查看登陆前与登录后的源代码有何差别) if "请输入注册时填写的手机号" not in req.text: print("登陆成功") else: print("登录失败") except: print("未知错误") def apply(): for i in range(75926,75927): apply_url = "http://x.x.x.x/?q=node/"+str(i)+"/people/apply" try: req = request.get(apply_url,headers=header) if "success" in req.text: print(str(i)+"课程申请成功") return i except: print(str(i) + "申请失败") def study(): study_url = "http://x.x.x.x/?q=items/student/study/"+str(apply()) try: req = request.get(study_url,headers=header) req.encoding = 'utf-8' G = r'<a score=".*?" uid=".*?" title=".*?" class="itemtitle" nid=".*?" module_id=".*?" item_id=".*?" href="/(.*?)">.*?</a>' study_url_list = re.findall(G,req.text,re.M|re.S) for study_url_last in study_url_list: study_url_all = "http://39.106.4.51/" + study_url_last try: request.get(study_url_all, headers=header, timeout=6) print(study_url_all + "学习完成") except: print(study_url_all + "学习失败") except: pass if __name__ == '__main__': username="你的用户名" password="你的密码" header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"} login(username,password) study() #运行study函数的时候会自动运行apply函数,所以不需要再写apply()
注:视频文件无法刷成功,电脑自己看一遍还是不能完成任务点,不知其原因,如有知道或解决办法,请评论留言,Thank you~
更新:此次文章仅供学习参考,不再更新。
其他图片:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/64146.html