
一般来说,验证集越大,我们对模型质量的度量中的随机性(也称为“噪声”)就越小,它就越可靠。但是,通常我们只能通过划分出更多训练数据来获得一个大的验证集,而较小的训练数据集意味着更糟糕的模型!而交叉验证可是用来解决这个问题。
什么是交叉验证?
在交叉验证中,我们将数据集(一般为训练集,不包括验证集)等量划分成几个小的子集,然后对不同的子集运行建模过程,以获得每个子集模型的拟合效果的指标(可用MAE 平均绝对误差表示)。
讯享网
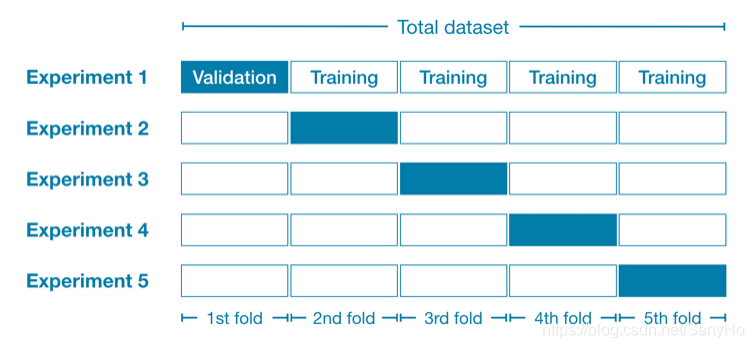
- 我们将所有的数据集分为五部分(5 folds),每部分有20%的数据。
- 在实验1中,我们使用第一个折叠(1st-fold)作为一个验证集,其他所有数据作为训练数据。之后获得第一个训练的模型拟合效果的指标 ( M A E 1 ) (MAE_1) (MAE1)
- 在实验2中,我们使用第二个折叠(2nd-fold)作为一个验证集(并使用除第二个折叠之外的所有内容来训练模型)。之后得到第二个训练的模型拟合效果的指标 ( M A E 2 ) (MAE_2) (MAE2)
- 我们重复这个过程,每次用一个折叠作为验证集。知道所有的折叠都被用作过验证集。
- 比较五个MAE的值,MAE的值最小所对应的实验,获得的模型和参数即为最优模型和最优参数。
什么时候用交叉验证?
- 当数据较少时,用交叉验证cross-validation
- 当数据较大时,用简单验证法,将样本数据随机分为两部分(如80%训练集和20%训练集)。如果用交叉验证,那么耗时会过长。
- 没有简单的阈值来划分大数据集和小数据集。但是,如果模型需要几分钟或更少的时间运行,则可能值得切换到交叉验证。
- 或者,可以运行交叉验证,看看每个实验的分数是否接近。如果每个实验都得到差不多相同的结果,那么一个验证集(简单验证法)可能就足够了。
Example
import pandas as pd from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import cross_val_score data = pd.read_csv('filename.csv') X = data[['column_1','column_2']] Y = data['column_3'] model = RandomForestRegressor(m_estimators=100, random_state=0) # 将得分*(-1),因为scikit learn计算的是负的MAE # cv是代表折叠的次数 scores = -1 * cross_val_score(model, X, y, cv=5, scoring='neg_mean_absolute_error') print("MAE scores:\n", scores) 讯享网
讯享网MAE scores: [. . . . .]
从MAE得分可以看出,实验四的MAE值最小,即该子集模型的拟合效果最好。

Scikit learn有一个约定,其中定义了所有度量,因此较高的数字更好。在这里使用否定词可以使它们与该惯例保持一致,尽管负的MAE在其他地方几乎闻所未闻。本质就是Scikit-Learn 交叉验证功能期望的是效用函数(越大越好)而不是损失函数(越低 越好),因此得分函数实际上与 MSE 相反(即负值)
print("Average MAE score (across experiments):") print(scores.mean()) print("Standard deviation:") print(np.sqrt(scores)) 讯享网Average MAE score (across experiments): . Standard deviation: 23415.3123
此外,我们可以取所有实验(实验1~5)的平均值标准差,来获得该算法的精度。然后可以尝试着用不同算法进行实验,比教它们的精度,看哪个算法更适用于这个数据集。
以分层采样为基础的交叉验证
相较于函数cross_val_score() 或者其他相似函数所提供的功能。这种情况下,你可以实现你自己版本的交叉验证。事实上它相当直接。以下代码粗略地做了和 cross_val_score() 相同的事情,并且输出相同的结果。
from sklearn.model_selection import StratifiedKFold from sklearn.linear_model import SGDClassifier from sklearn.base import clone sgd_clf = SGDClassifier(max_iter=5, tol=-np.infty, random_state=42) # 对其中1折进行预测,对其他折进行训练 skfolds = StratifiedKFold(n_splits=3, random_state=42) for train_index, test_index in skfolds.split(X_train, y_train_5): clone_clf = clone(sgd_clf) X_train_folds = X_train[train_index] y_train_folds = (y_train_5[train_index]) X_test_fold = X_train[test_index] y_test_fold = (y_train_5[test_index]) clone_clf.fit(X_train_folds, y_train_folds) # 预测测试集中数据的分类类别 y_pred = clone_clf.predict(X_test_fold) # 将预测得到的分类信息与测试集中原有的分类信息进行比较,求出相同的数量的和 n_correct = sum(y_pred == y_test_fold) # 将该和除以总共预测的值的数量,计算准确率 print(n_correct / len(y_pred)) StratifiedKFold 类实现了分层采样(详见【纯随机采样(train_test_split)和分层采样(StratifiedShuffleSplit)| sklearn库实现】),生成的折(fold)包含了各 类相应比例。在每一次迭代,上述代码生成分类器的一个克隆版本,在训练折 (training folds)的克隆版本上进行训练,在测试折(test folds)上进行预测。然后它计算出正确预测的数目和预测的值的数量的比例,获得准确率。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/60030.html