
目录:机器学习发展历程简单介绍;简单的概念介绍;统计学习三大要素:模型(主要解决模型是什么的问题),策略(选择模型的准则),算法(概念性的描述)
感觉是所有学科的共性:概论部分一般是全书的概括和后期内容的基础,而往往又由于对该领域不熟悉,所以感觉学习概论部分很枯燥乏味又晦涩难懂,此时需要看一些后面的具体内容,再回过头来看概论。这样前前后后反复几次就可以更深入的了解了~概论部分更多是记录基础知识,所以摘抄性内容比较多~
一.前记(仅作为了解):
机器学习的发展也是经历过一个阶段的,从推理期(让机器具备逻辑推理能力)---》知识期(各种专家系统)---》智能期(可以像人一样去自主学习),其中的研究方法也涉及基于神经网络的“连接主义”(connectionism)学习,基于逻辑表示的“符号主义”(symbolism),还有以决策理论为基础的学习技术以及强化学习技术等也得到发展。目前应用最多的是基于统计学习理论的机器学习和基于神经网络的深度学习。
(1)“统计学习”(statistical learning)的代表性技术是支持向量机(Support Vector Machine)以及更一般的“核方法”(kernel methods)。遵循结构风险最小化原则。
(2)深度学习,在语音,图像等复杂对象应用中,深度学习技术取得优越性能,为机器学习技术走向工程实践带来便利。推动该技术的发展主要有以下三个原因:大数据,计算力(硬件性能提高,集群,云计算,并行计算等),算法。
二.略过的概念:
下面的一些简单概念只是提一下,很好理解,任何一本机器学习的书也都会有介绍。
1.机器学习任务分类:监督学习(有标记信息,也就是知道每个样本对应的真实结果),无监督学习,半监督学习,强化学习
2.输入空间,特征空间(我们通常用一个特征向量表示一个样本,这里涉及一些线性代数的概念),假设空间(模型,带有参数的函数集合)
3.监督学习分为:分类问题(预测值为离散值,比如好瓜还是坏瓜,有没有生病等),回归问题(预测值为连续值,比如房价,股价),标注问题(输入变量与输出变量均为变量序列的预测问题)
4.联合概率分布,条件概率分布,先验概率,后验概率
5.训练集,验证集,测试集
以监督学习为例,看一下简易的示例图:

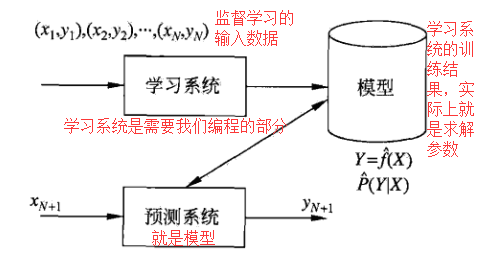
接下来的问题:我们主要以监督学习为主。
三.统计学习三要素
1.模型。目前机器学习主要分为两大类(有可能说的不太准,只是平常的一种感觉):统计机器学习和神经网络深度学习。统计机器学习(statictical machine learning)是计算机基于数据构建概率统计模型,并运用概率统计模型对数据进行预测与分析的学科。
整个过程是数据驱动的,我们把输入的数据X和输出的预测值Y都看作是随机变量,他们遵循一定的概率分布(比如正态分布,二项分布)。
我们所谓的模型要么是非概率模型的决策函数:一个函数,输入X,产生输出Y
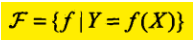
要么是条件概率分布:在输入X的条件下,输出Y的概率。条件概率就相当于后验概率。
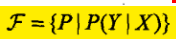
而模型又是带有未知参数的,未知参数可能不止一个,所以我们用参数向量表示:
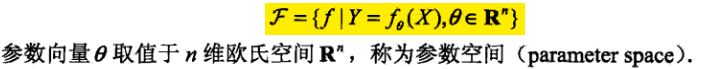
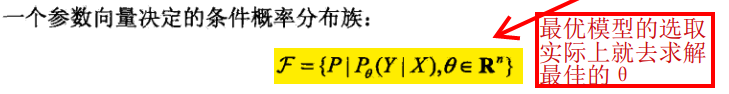
注:
不同数据集适用于不同的模型,比如做金融的很多都不会用到深度学习,基本上简单的linear regression, lasso, svm, gradient boosting machine等就可以了。计算机的优势在于大规模计算,所以适合大数据集。而目前在自然语言处理(NLP)和计算机视觉(CV,以图像和视频为输入数据)领域,深度学习的作用就很大。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/56342.html