
此题小结:
用python脚本获取网页内容以及post数据
主要函数:
s= requests.session()
url=’’
return= s.get(url). # 可以获取header等信息
data={}
最后传值:s.post(data=data)
解题流程
打开网页,只看到一句话:我感觉你得快点!!!

讯享网
F12查看源代码
发现了提示:OK ,now you have to post the margin what you find
需要以POST方式传参,先用BrupSuite抓包看一下
1、使用BrupSuite抓包并重新发送


发送后看到flag
2、使用base64解码

跑的还不错,给你flag吧: MTMyOTIx
3、继续进行一次base64解码
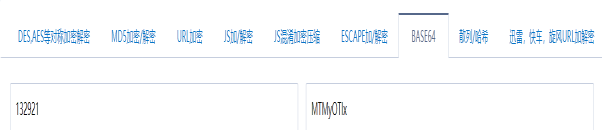
4、通过post方法上传margin=

还要再快点,看来有时间限制,不过已经有了思路,可以编写python脚本了
5、编写python脚本并执行

import requests import base64 url = "http://114.67.246.176:13069" r = requests.session() #建立session header = r.get(url).headers 获得消息头,因为flag在消息头里 mid = base64.b64decode(header['flag']) 解密消息头键名flag的键值,将flag进行base解码 mid = mid.decode() #为了下一步通过split不报错,b64decode后操作的对象为byte类型的字符串,而split数学函数要为str类型的 flag = base64.b64decode(mid.split(':')[1]) #获得flag:后的值 data = {
'margin':flag} print(r.post(url,data).text) #post方法传上去 #方法二: import requests import base64 url= "http://120.24.86.145:8002/web6/" s = requests.Session() headers = s.get(url).headers #获得消息头 str1 = base64.b64decode(headers['flag']) #解密消息头键名flag的键值 str2 = base64.b64decode(repr(str1).split(':')[1]) #解密str1里flag:后的值 key = {
'margin':str2} #创建一个字典类型用于传参 flag = s.post(url,data=key) #post方法传上去 """ 知识补充: python里的字符串有byte型和str型,有时操作数类型和操作类型不匹配就会报错 b64decode()结果是byte型字符串,而split()函数要为str型字符串 repr()函数可以将byte型字符串转换成str型字符串 另外,还有一个简单的方法: 1、byte型转str型 _str=_byte.decode() 2、str型转byte型 _byte=_str.encode() """ """ 知识点 import base64 st = 'hello world!'.encode() #默认以utf8编码 res = base64.b64encode(st) print(res.decode()) #默认以utf8解码 res = base64.b64decode(res) print(res.decode()) #默认以utf8解码 输出 aGVsbG8gd29ybGQh hello world! """ """ split() 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。 实例 以下实例展示了 split() 函数的使用方法: str = "this is string example....wow!!!" print (str.split( )) # 以空格为分隔符 print (str.split('i',1)) # 以 i 为分隔符 print (str.split('w')) # 以 w 为分隔符 以上实例输出结果如下: ['this', 'is', 'string', 'example....wow!!!'] ['th', 's is string example....wow!!!'] ['this is string example....', 'o', '!!!'] 以下实例以 # 号为分隔符,指定第二个参数为 1,返回两个参数列表。 txt = "Google#Runoob#Taobao#Facebook" # 第二个参数为 1,返回两个参数列表 x = txt.split("#", 1) print(x) 以上实例输出结果如下: ['Google', 'Runoob#Taobao#Facebook'] """ 讯享网
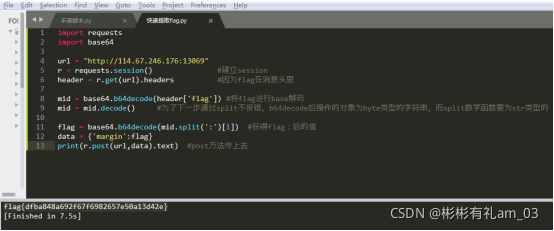
6、得到flag:flag{dfba848a692f67fe50a13d42e}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/55305.html