
AI 科技评论按,本文作者韦阳,本文首发于知乎专栏自然语言处理与深度学习,AI 科技评论获其授权转载。
韦阳知乎主页:
https://www.zhihu.com/people/godweiyang/posts
知乎专栏地址:
https://zhuanlan.zhihu.com/godweiyang
论文:Unsupervised Recurrent Neural Network Grammars
论文地址:http://arxiv.org/abs/1904.03746
github代码地址:
https://github.com/harvardnlp/urnng
介绍
这篇是新鲜出炉的 NAACL19 的关于无监督循环神经网络文法(URNNG)的论文,在语言模型和无监督成分句法分析上都取得了非常不错的结果,主要采用了变分推理和 RNNG。本文公式量较大,因此我也推了好久,算法也挺多的,首先上一张我推导的公式笔记:

讯享网
我这篇博客就不按照论文的顺序来讲了,就按照我上面这张笔记讲一讲我的理解吧,很多细节可能会忽略,请参见原文吧。
首先对于无监督成分句法分析,常规做法就是学习一个生成模型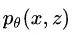 ,就比如 RNNG 就是一个生成模型,但是缺少句法树 z 的监督信号怎么办呢?现在给你的输入只有句子 x,那么只能用语言模型
,就比如 RNNG 就是一个生成模型,但是缺少句法树 z 的监督信号怎么办呢?现在给你的输入只有句子 x,那么只能用语言模型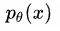 来做监督了。习惯上我们喜欢取对数,也就是:
来做监督了。习惯上我们喜欢取对数,也就是:
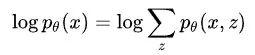
这里就存在几个问题,比如 z 的状态空间太大了,不可能穷举所有的,所以接下来按步骤讲解如何求解。
URNNG模型
先上一张模型图,让大家对整体模型有个大概的认知:
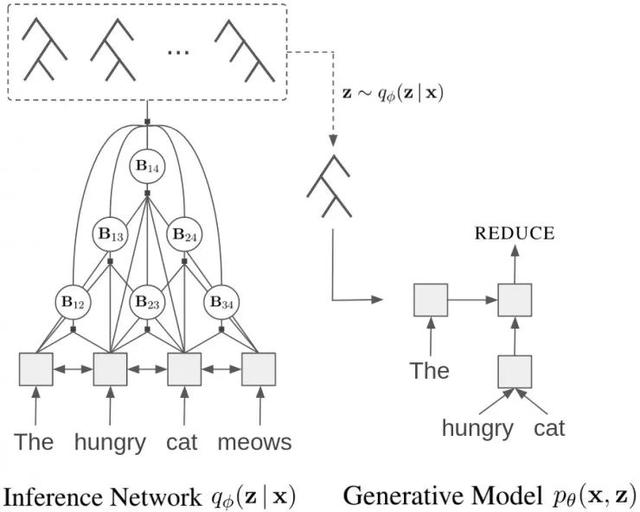
左边是一个推理网络(Inference Network),用来根据输入 x 推理出隐变量也就是句法树 z 的概率分布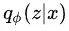 。右边是一个生成模型(Generative Model),用来计算从推理网络中采样出来的句法树 z 的联合概率,最后根据上面语言模型算出句子的概率,最大化这个概率即可。
。右边是一个生成模型(Generative Model),用来计算从推理网络中采样出来的句法树 z 的联合概率,最后根据上面语言模型算出句子的概率,最大化这个概率即可。
接下来分别讲解这两个部分和具体的优化方法。

首先将词向量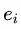 和位置向量
和位置向量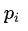 拼接,作为推理网络 LSTM 的输入:
拼接,作为推理网络 LSTM 的输入:
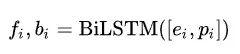
然后算出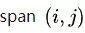 的得分,计算方式和以往一样,用 BiLSTM 前后向输出做差,然后通过一个前馈神经网络得到分数:
的得分,计算方式和以往一样,用 BiLSTM 前后向输出做差,然后通过一个前馈神经网络得到分数:
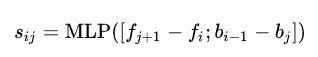
接下来就需要计算句法树的概率分布了,这里不直接计算句法树 z,而是计算它的邻接矩阵 B 的概率分布,这个邻接矩阵意思就是如果存在,那么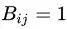 ,否则的话
,否则的话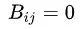 。然后就可以用 CRF 计算出邻接矩阵 B 对应的概率:
。然后就可以用 CRF 计算出邻接矩阵 B 对应的概率:
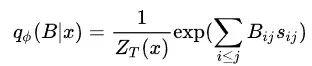
其中
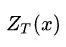
是配分函数,也就是用来将概率归约到 0 到 1 之间的:
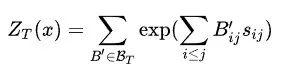
注意这里的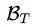 并不是所有的 01 矩阵集合,而是必须满足能产生合法句法树的矩阵,情况也很多,不能穷举求解,在这里采用经典的 inside 算法来求解这个配分函数:
并不是所有的 01 矩阵集合,而是必须满足能产生合法句法树的矩阵,情况也很多,不能穷举求解,在这里采用经典的 inside 算法来求解这个配分函数:

不过我觉得这里是错的!就是这里的两处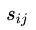 应该改成
应该改成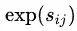 。不过具体代码实现的时候并没有这么做,初始值一样都是
。不过具体代码实现的时候并没有这么做,初始值一样都是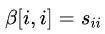 ,但是递推的时候采用了如下式子:
,但是递推的时候采用了如下式子:
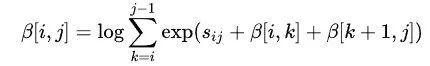
其实就是用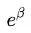 来取代了,化简后就是代码实现这个式子,应该是为了防止数值溢出。
来取代了,化简后就是代码实现这个式子,应该是为了防止数值溢出。
然后就是采样了,推理网络的目的就是计算出句法树的概率分布,然后根据这个分布采样出若干个句法树,那么现在给定一棵句法树可以根据上面的算法计算出它的概率了,那怎么采样呢?其实还是可以通过刚刚计算得出的数组来采样,采样算法如下:

其实就是自顶向下的根据概率分布来采样每个 span 的 split,用一个队列来保存所有还没有采样出 split 的 span,然后把所有采样出的 span 在邻接矩阵中的对应值标为1。
最后推理网络采样出了若干个句法树 z,然后根据 CRF 计算出每个句法树的概率
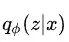
,后面的事情就交给生成网络了。

上面的推理网络采样出了若干个句法树 z,生成网络的目的就是计算它的联合概率
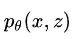
。这个其实不难,在之前的 RNNG 论文笔记中,我已经大致讲过了,可以去复习一下:Recurrent Neural Network Grammars,这里稍稍做了一些改进。
首先需要定义一个栈用来存放转移的历史状态,这里定义栈里放的元素为二元组(h, g),一个是 stack-LSTM 编码的输出,一个是子树的结构表示。首先需要预测下一步的 action 是什么,所以取出栈顶的元素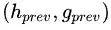 ,预测 action 的时候只要用到隐含层输出:
,预测 action 的时候只要用到隐含层输出:
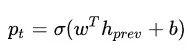
然后根据这个概率预测 action 是 SHIFT 还是 REDUCE,下面分两种情况讨论。
如果是 SHIFT,那么因为是生成模型,所以需要预测下一个移进的单词是什么:
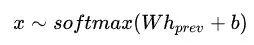
然后将单词 x 的词向量输入到 stack-LSTM 中得到下一个时刻的隐含层输出:

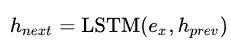
最后将
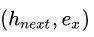
推进栈里。
如果是 REDUCE,那么首先需要取出栈顶的两个元素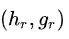 和
和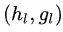 ,然后用 TreeLSTM 计算出两个子结点合并后的子树的表示:
,然后用 TreeLSTM 计算出两个子结点合并后的子树的表示:
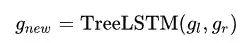
接着还是计算 stack-LSTM 下一个时刻的隐含层输出:
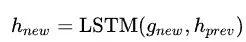
最后将
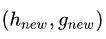
推进栈里。
为了防止数值溢出,常规上我们计算联合概率的对数:
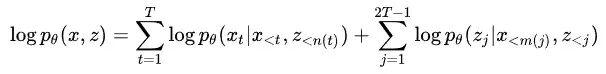
从这个式子可以看出,联合概率定义为所有给定某段单词和 action 预测下一个单词和给定某段单词和 action 预测下一个 action 的概率之积。
如果是监督任务比如 RNNG,那么只需要最大化这个联合概率就足够了,但是现在要做无监督,没有 z,注意别搞混了,推理网络采样出的 z 可不能用来监督哦,因为那本来就不是正确的,所以接下来要采用语言模型来作为最终的目标函数。
Variational Inference
句子 x 的对数概率定义为:
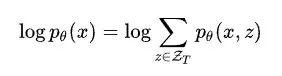
其中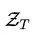 是所有合法句法树的集合,但是这里不可能穷举所有的句法树,所以就要用到变分推理,具体的理论知识不仔细介绍了,可以去查阅变分推理相关知识,下面直接推导。
是所有合法句法树的集合,但是这里不可能穷举所有的句法树,所以就要用到变分推理,具体的理论知识不仔细介绍了,可以去查阅变分推理相关知识,下面直接推导。
其中最后一行叫做先验 的证据下界(ELBO),要想最大化先验,可以最大化这个 ELBO,如果我们对这个 ELBO 变化一下形式可以得到:
的证据下界(ELBO),要想最大化先验,可以最大化这个 ELBO,如果我们对这个 ELBO 变化一下形式可以得到:
所以这个 ELBO 和先验就相差了一个 KL 散度,最大化 ELBO 的话等价于最小化 KL 散度,也就是使推理网络产生句法树的概率分布和生成模型尽量接近。
但是这个 ELBO 还是不好算,尽管它把 移到了求和符号也就是期望里面,所以转换一下形式:
移到了求和符号也就是期望里面,所以转换一下形式:
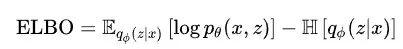
因为模型一共有两组参数,一个是推理网络的参数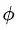 ,一个是生成网络的参数,所以下面分别对两个参数求导。
,一个是生成网络的参数,所以下面分别对两个参数求导。
首先对求偏导,因为只有第一项有这个参数,所以偏导为:
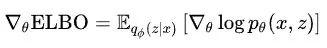
这个偏导可以按照概率
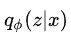
采样得到:
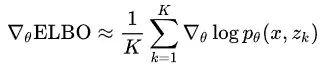
然后对求偏导,因为有两项含有这个参数,分别求偏导。第二项是熵,它的值其实可以用之前的数组算出来,算法如下:

然后偏导可以交给深度学习库的自动微分,就不用你自己求啦。
至于第一项的偏导可以用类似于策略梯度的方法解决:
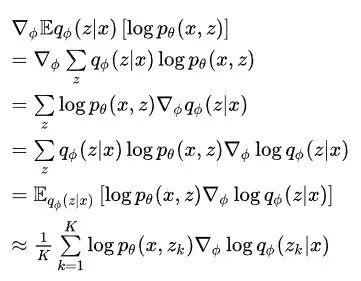
这里最后也是转化为了采样,和策略梯度做法类似,这里加入 baseline 来提升性能:
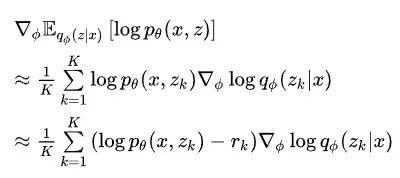
其中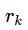 定义为所有其他的对数联合概率的均值:
定义为所有其他的对数联合概率的均值:
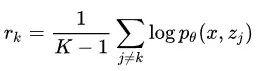
至此所有偏导都已求出来了,两个通过采样得到,一个通过 inside 算法结果自动微分得到,所以去掉导数符号并相加就得到了最终的损失函数:
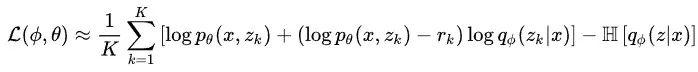
一定要注意,这里的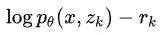 在代码实现的时候不能传入梯度,不然的话对的偏导就会多出这一项的偏导了!
在代码实现的时候不能传入梯度,不然的话对的偏导就会多出这一项的偏导了!
实验
实验结果这里就不多说了,细节具体看论文吧,就贴两个结果,一个是语言模型:
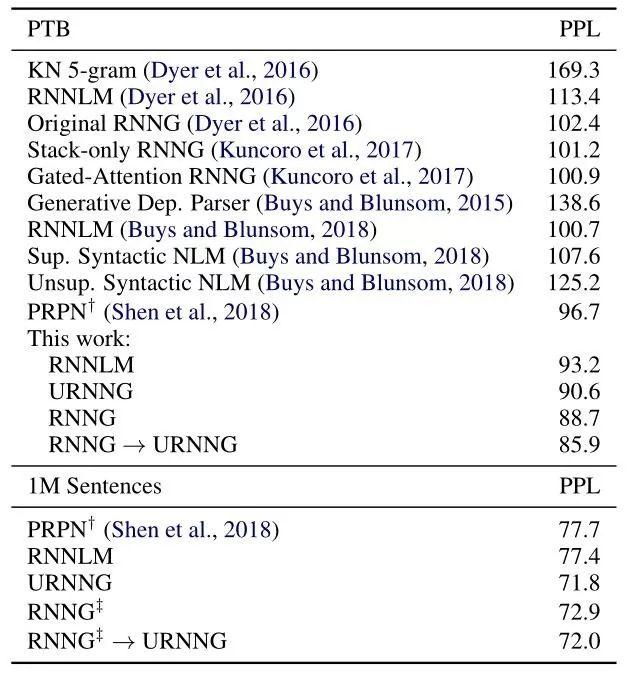
可以看出在标准的 PTB 数据集上,URNNG 效果只比监督学习的 RNNG 和用 URNNG 损失函数微调后的 RNNG 效果略差一点,但是在大数据集上,URNNG 的优势就体现出来了。
另一个是无监督成分句法分析,这里是用的全部长度的测试集:
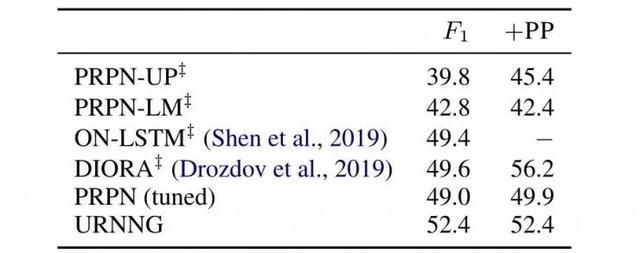
这个任务上 URNNG 效果是最好的。
结论
和之前两篇语言模型做无监督成分句法分析类似,这篇论文用推理网络学习句法树的概率分布并采样句法树,再用生成网络计算这些句法树和句子的联合概率,最后用变分推理最大化句子的概率,也就是学习出一个好的语言模型。
2019 全球人工智能与机器人峰会
由中国计算机学会主办、**网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。
点击阅读原文,加入NLP 论文讨论小组,与同行切磋交流
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/54906.html