
一、背景
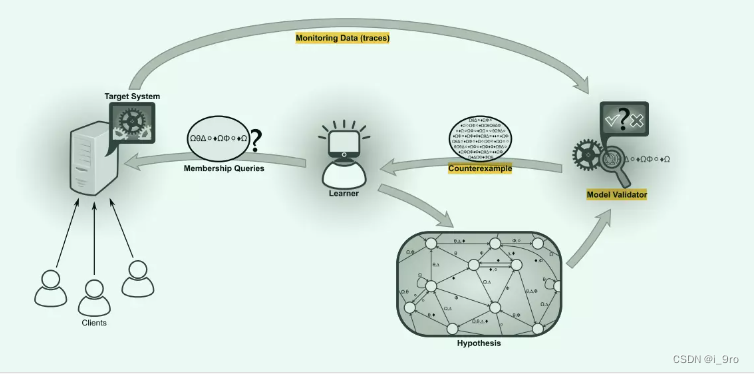
- Minimally Adequate Teacher (MAT)
这个算法假定了一个“teacher”的角色,他是先知,知道这个黑盒SUL的一切。在构造过程中我们可以问老师二种类型的问题。一是称为membership query成员查询, 对于构造Mealy automate来说就是输入某个字串,SUL输出什么?(对于DFA来说,对应于回答这个字串是否被SUL接受,如果接受输出1,否则为0);第二种称为equivalence query(等价查询),即目前构造的DFA或者Mealy自动机和SUL是否等价,如果等价,则Teacher回答yes,否则也返回一个反例字串,来说明他们的不同。如果给出一个反例,learner需要通过询问额外的问题来完善其假设,从而推测一个后续的新假设。这些构建假设/改进和等价性检查的步骤被迭代执行,直到等价性查询yes。 - Active automata learning
主动自动机学习旨在通过执行测试用例并观察结果(无论输入序列是否合理)
依赖的几个假设
可被调用的操作集合必须是先验已知的(例如,来自公开API)
系统对membership query的反应必须是可观察的
系统必须在选定的输出抽象下确定性地运行
需要一种重置系统的方法,即,后续membership query必须是独立的 - Counterexample
Without such counterexamples, the inferred automata usually remain very small.
没有counterexamples作为外部源输入的话,推断的自动机通常很小。
有监督主动学习的过程中,In case of a violation, a trace forming a counterexample is reported to the learner, which then refines its hypothesis.

讯享网
当出现一个counterexample时,学习算法需要将包含的信息合并到其内部数据结构中。 - prefix set,suffix set
举例字符串“ACVSDB”
前缀集为{“A”,“AC”,“ACV”,“ACVS”,“ACVSD”};
后缀集为{“B”,“DB”,“SDB”,“VSDB”,“CVSDB”} - Practical Motivation
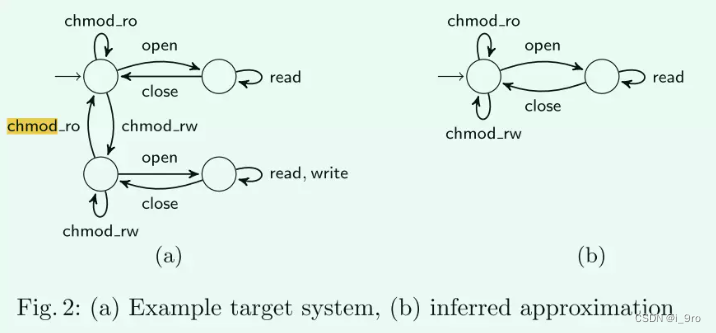
问题描述:可以打开、读取和关闭文件。只有在以前打开过文件的情况下,才可以阅读和关闭该文件。文件只有在关闭时才能打开。此外,还可以写入文件。这需要将此文件的访问模式设置为预先读/写(chmod rw)。无法更改打开文件的访问模式。
难点:chmod rw操作不会立即生效:需要先打开文件,然后写入文件。因此,由学习算法推断的模型可能是不正确的,如图2b所示。如果与阅读相比,写入是一种罕见的操作,那么这种不完整性将在很长一段时间内被忽视。只有当访问模式被设置为读/写并且文件被打开和写入时,假设才不能解释观察到的行为。图二b不支持下面的序列
前人解决方法:将后缀添加到内部数据结构中;将反例的所有后缀添加到它们的数据结构中;使用反例的所有前缀以确保识别新状态;
局限性:此前的算法会导致所存储的信息用于在随后的细化期间的membership query。多余的打开,读,关闭会一遍遍重复执行,即使不能获得有价值的信息。此外,由于这些冗余出现在实际兴趣点(chmod rw)之前和之后,因此无论是完全基于前缀的方法还是完全基于后缀的方法都不能避免这个问题。
目标:消除所有执行反例冗余导致的性能问题

二、方法
假设构建:所选输入符号序列被发送到SUT,观察响应时生成了哪些输出符号序列。输入序列的选择取决于观察到的对先前序列的响应。当满足一定的收敛准则时,学习算法构造一个假设,该假设是与迄今为止记录的观测一致的最小确定性Mealy机。这意味着对于已经发送到SUT的输入序列,该假设产生与从SUT观察到的输出相同的输出。对于其它输入序列,该假设通过从记录的观测值外推来预测输出。
假设验证:为了验证这些预测与SUT的行为一致,学习移动到验证阶段,其中SUT经受一致性测试算法,该一致性测试算法旨在验证SUT的行为与假设一致。如果一致性测试发现了反例,即:如果SUT和假设在输入序列上不一致,则重新进入假设构建阶段,以便构建更精确的假设,该假设也考虑所发现的反例。如果没有找到反例,学习终止并返回当前假设。这不是SUT符合假设的绝对保证,尽管许多一致性测试算法在一些技术假设下提供了这样的保证。如果假设构造和验证的循环没有终止,则这指示SUT的行为不能被有限Mealy机器捕获,该有限Mealy机器的大小和复杂性在所采用的学习算法的范围内。
反例是假设验证的关键
案例:
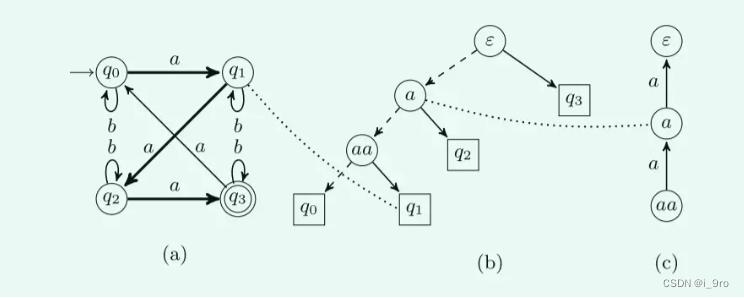
图3 运行实例:(a)目标DFA a和最终假设H2, (b)最终判别树T2,©最终假设的判别器
输入{a,b}
图3 a中的状态转移由前缀闭包Sp维护,Sp={ε, a, aa, aaa}。a中的状态和b中的叶子节点相对应。b中对于每一对不同的状态,可以通过查看对应叶的最低共同祖先的标签来获得一个分隔符。内部节点的标签充当分隔符。当它们形成后缀封闭集时,它们可以紧凑地存储在一个trie中。这三个节点中的每个节点都表示一个单词,这个单词可以通过沿着路径找到根来构造。因此,词根本身对应的是空ε。
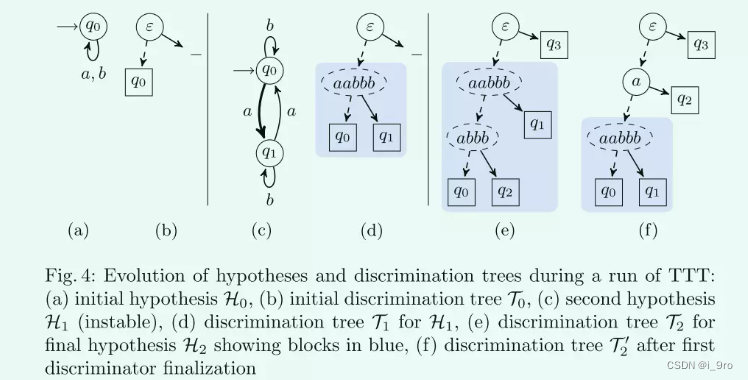
1)假设提出
状态是通过一个前缀闭合的集合来确定的,对应于discrimination tree的叶子节点,图4ab
数学公式: $ q_0 $状态由数学公式: $ \varepsilon $确定
过渡目标是通过筛选来确定的:给定状态q,由前缀u∈Sp识别,a的下一个状态是通过筛选ua到T来确定的。
最终状态对应判别树的右子树
(2)假设完善
模型完善的关键是反例
反例输入到状态机和假设中结果不同就会导致状态分解。
将ε·a和ε·b输入,导致数学公式: $ q_0 $。因此,所有形成自反边。对于图4 a中的状态机,一个可能的反例是w = bbbaaabbb。这个反例包含了很多多余的信息:b符号只在图4a中运行自循环,因此对新状态的发现没有贡献。部分(但不是全部)冗余信息将由第一个反例分析步骤消除,该步骤生成分解<bbbb, a, aabbb>。因此,图4c里增加一个可以接收a的新状态数学公式: $ q_1 $
(3)假设稳定
作为前一步的结果,可能会发生构建的假设与存在于判别树中的信息相矛盾。对于反例的处理流程,首先对其进行分解,然后在判别树中分解相应的叶子,从而在假设中引入一个新的状态。
继续寻找反例,aaabbb
(4)判别器确认
简化,如从图4e到图3b
寻找反例bbbaaabbb,有很多冗余
三个树状数据结构。
spanning tree:定义唯一访问序列的生成树,嵌入到假设的过渡图中
discrimination tree:区分状态
discriminator trie:鉴别树,存储后缀闭式判别器集。每个节点都表示一个单词,这个单词可以通过沿着路径找到根来构造。root对应的是空ε。
所有数据结构所需的组合空间与假设的大小Θ(kn)大致相同
效率
k是字母Σ的大小,目标DFA A有n个状态,等价查询返回的最长反例长度为m。
-查询复杂度,即算法提出的所有成员查询的数量。最坏情况O(n)
-符号复杂度,即所有这些成员关系查询中包含的符号总数。最坏情况O(kn^2+n logm)
-空间复杂度,即算法内部数据结构所占用的空间量。O(kn)

四、总结
资料
模型学习 Angluins L*算法 学习笔记 - 知乎 (zhihu.com)
Learnlib-ttt github
Learnlib Github
模型学习
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/51515.html