
首先来一个全局总览,后面我会分别对每个命令进行说明:

讯享网
如果你的mysql导入环境变量,可以在命令行输入:
mysql -u root -p 讯享网
mysql数据类型
MySQL支持多种数据类型,包括数值类型、日期和时间类型、字符串类型、二进制类型等。下面是MySQL中常用的数据类型:
数值类型:
INT:整数类型,常用于存储整数数据。
FLOAT:单精度浮点数类型,用于存储小数数据。
DOUBLE:双精度浮点数类型,用于存储大数数据。
DECIMAL:定点数类型,用于存储精确的小数数据,通常用于财务计算。
日期和时间类型:
DATE:日期类型,格式为’YYYY-MM-DD’。
TIME:时间类型,格式为’HH:MM:SS’。
DATETIME:日期时间类型,格式为’YYYY-MM-DD HH:MM:SS’。
TIMESTAMP:时间戳类型,表示从1970年1月1日以来的秒数。
字符串类型:
CHAR:固定长度字符串类型,最多255个字符。
VARCHAR:可变长度字符串类型,最多65535个字符。
TEXT:长文本类型,最多65535个字符。
ENUM:枚举类型,允许从预定义的值列表中选择一个值。
SET:集合类型,允许从预定义的值集合中选择一个或多个值。
二进制类型:
BINARY:固定长度的二进制字符串类型。
VARBINARY:可变长度的二进制字符串类型。
BLOB:二进制大对象类型,用于存储大块二进制数据。
其他类型:
BOOL:布尔类型,可以存储True或False。
JSON:JSON数据类型,用于存储JSON格式的数据。
一,基础数据库操作
1.创建数据库
讯享网create database my_database;
2.查询数据库
show databases; 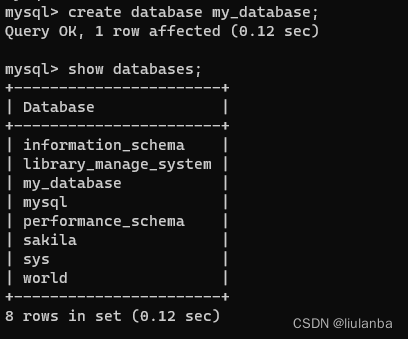
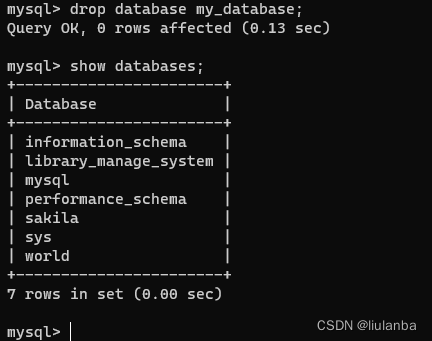
3.删除数据库
讯享网drop database my_databases;
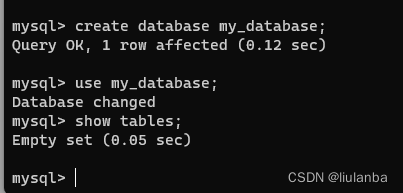
4.选择数据库
use my_database; 5.查询数据表
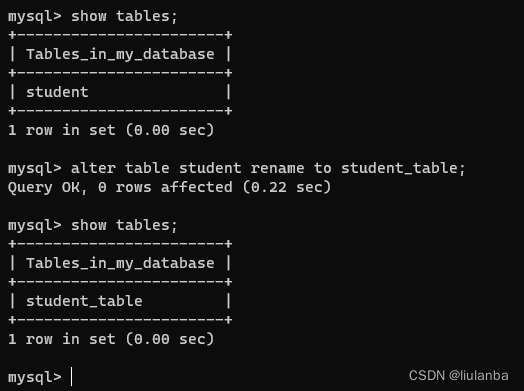
讯享网show tables;
6.创建数据表
create table student(id int,name char(10),age int,sex char(5)); 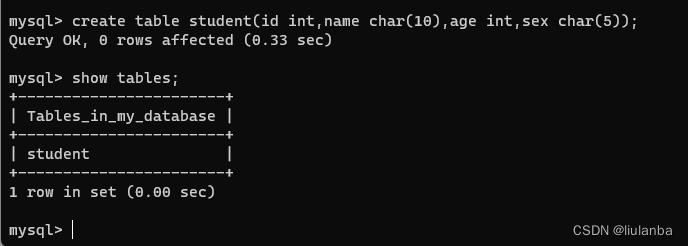
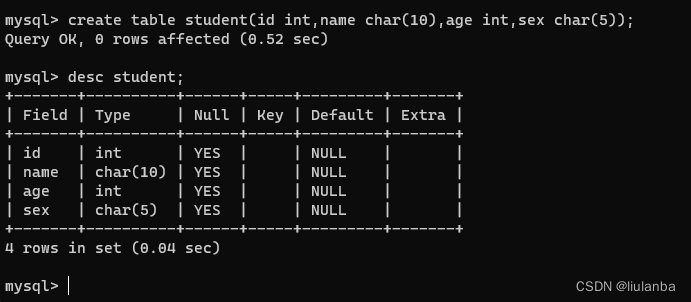
7.查询表结构
讯享网desc student;
8.删除表
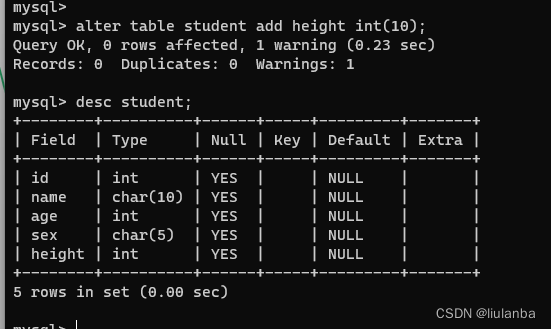
drop table student; 9.数据表添加列
讯享网alter table student add height int(10);
10.数据表删除列
alter table student drop height; 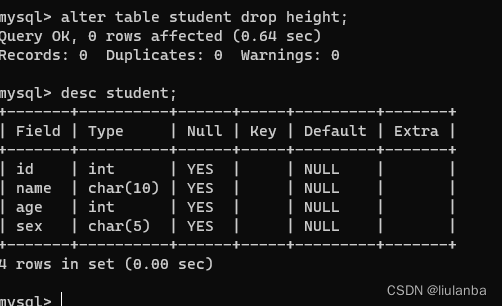
11.数据列改名
讯享网alter table student change column height high int(3);
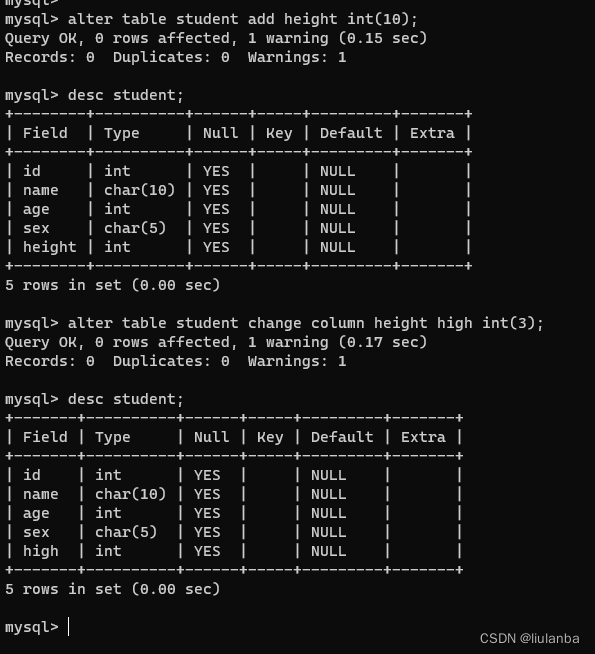
12.数据列修改数据类型
alter table student modify column high char(10); 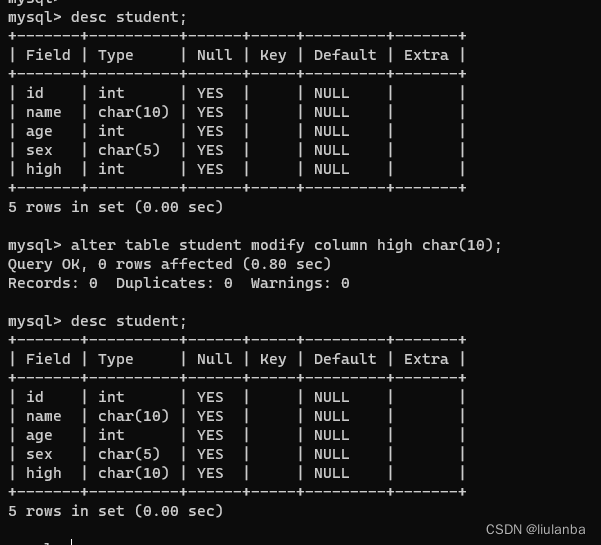
13.修改表名
讯享网alter table student rename to student_table;
14.插入数据项
insert into student(id,name,age,sex,high) value (001,"张三",10,"男",160); 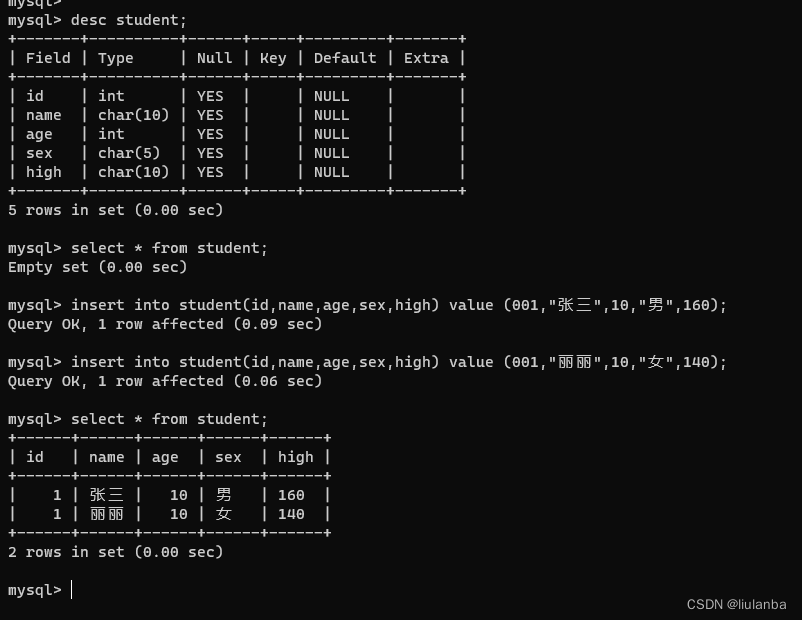
15.删除数据项
讯享网 delete from student where high=140;
16.更新数据项
update student set age=12; 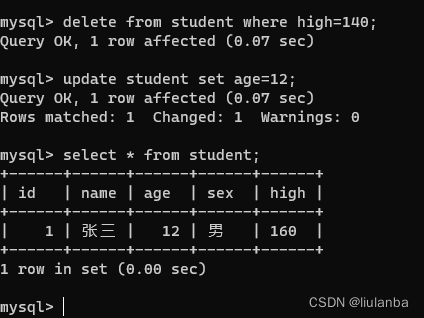
二,逻辑运算符
- between 最小值 and 最大值
语法:select * from 表名 where 列名 between 最小值 and 最大值;
讯享网select * from student where id between 2 and 5;
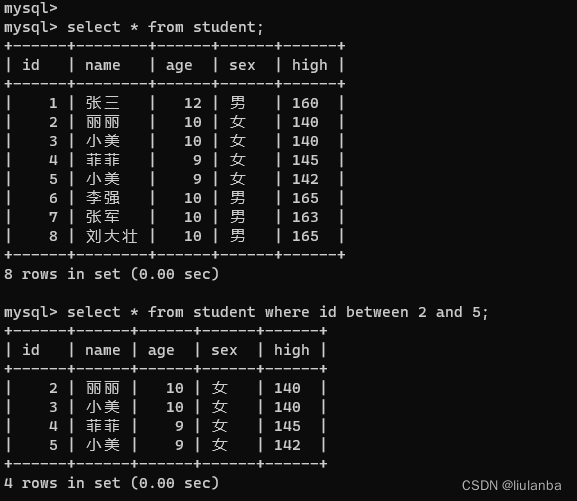
作用和使用><是一样的
select * from student where id>2 and id<5; 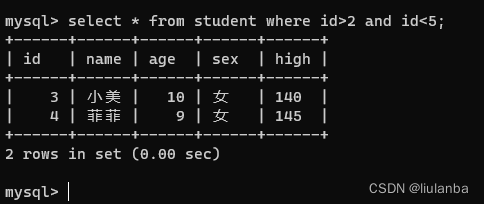
讯享网select * from student where high is null;
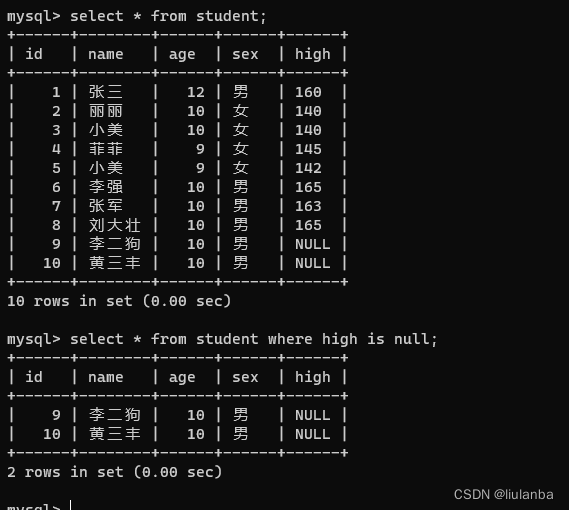
- in (取值范围)
语法:select * from 表名 where 列名 in (值1,值2,…)
select * from student where age in(9,12); 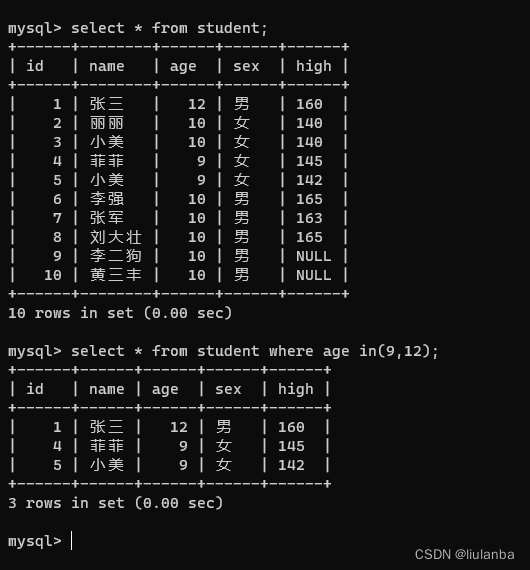
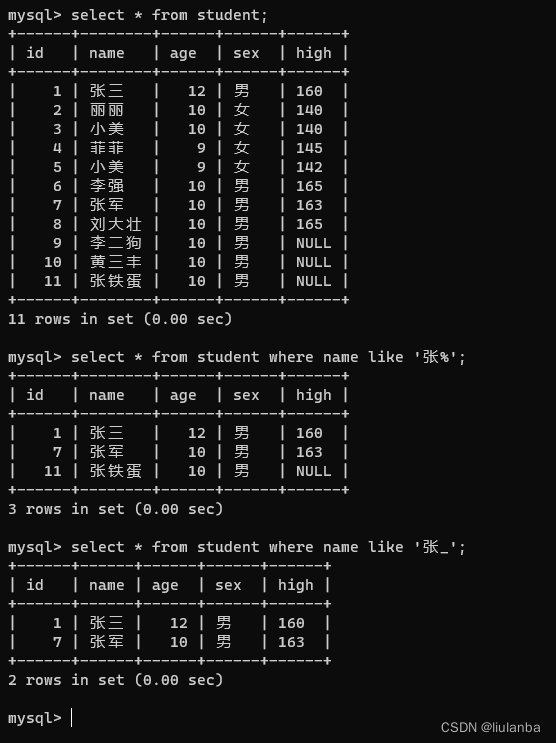
- like 好像
通配符: % 代表任意字符 _ 一个下划线代替一个字符
语法:select * from 表名 where 列名 like ‘通配符 特征 通配符’;
讯享网 select * from student where name like '张_';
select id as student_id from student where name like '张_'; 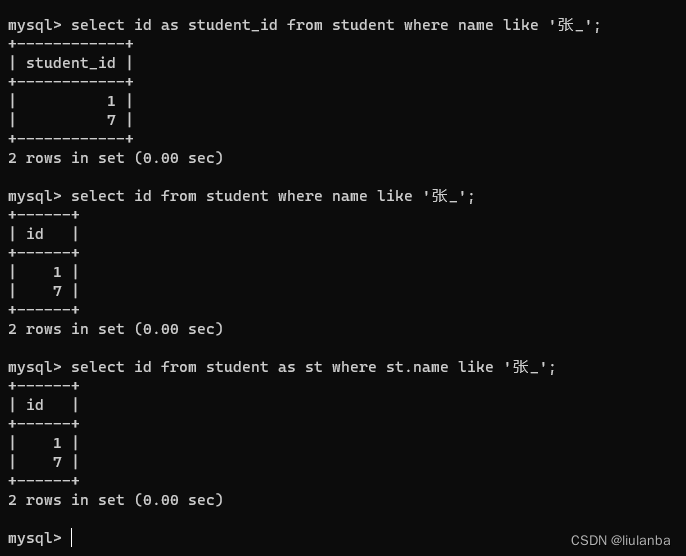
6.union 合并两个或多个select语句结果集
讯享网 select id from student as st where st.name like '张_' union select name from student where age=9;
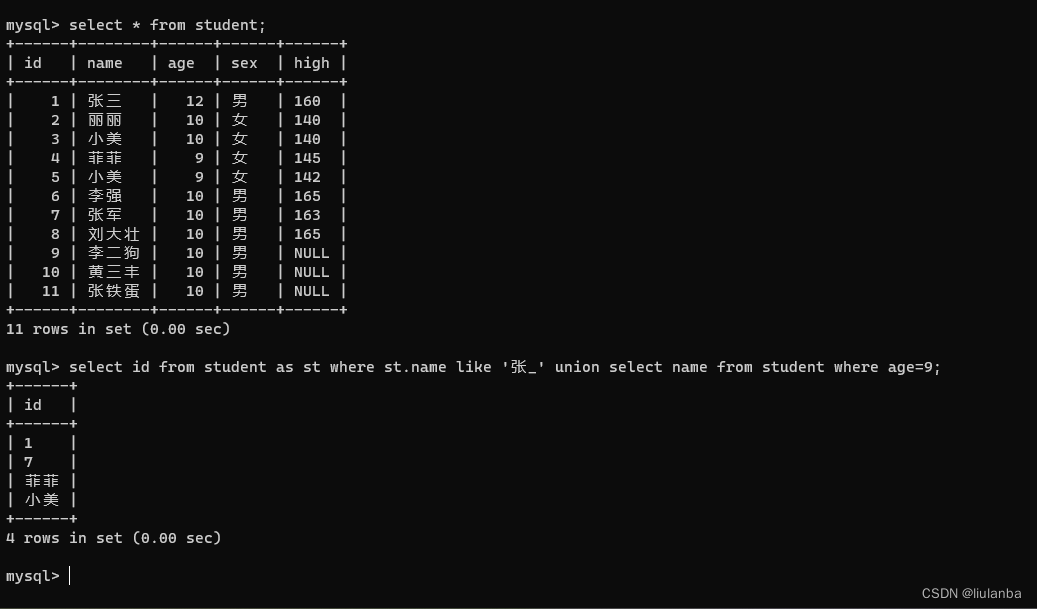
三,排序
关键词 order by
排序规则:升序排序 asc (默认可省略) 降序排序 desc
语法:
单列 select * from 表名 order by 列名 asc或者 desc;
多列 select * from 表名 order by 列名 asc或者 desc,列名2 asc或者desc,…;
select * from student order by age asc,name desc; 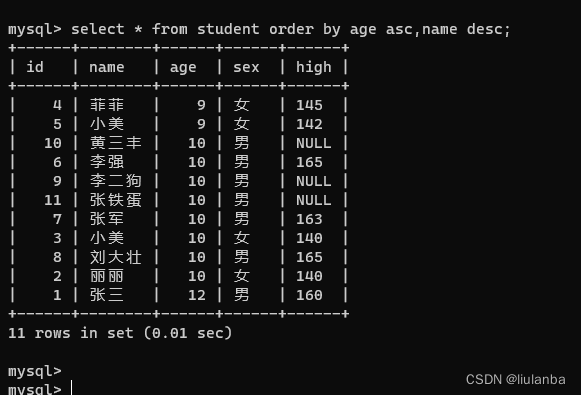
四,去重
讯享网 select distinct age from student;
select age,count(*) from student group by age; 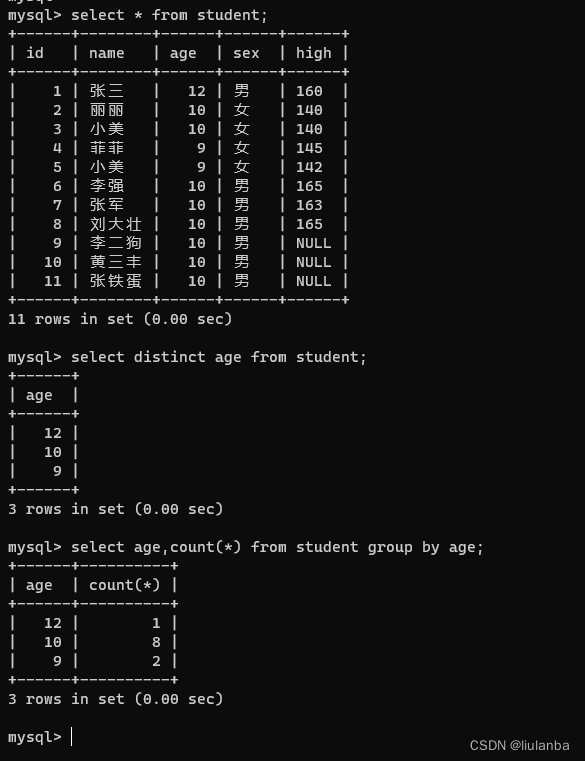
五,统计函数
这些聚合函数可以与其他SQL语句结合使用,如WHERE子句用于筛选特定条件的行,GROUP BY子句用于按列进行分组,并可用于计算每个组的聚合值,ORDER BY子句用于对结果进行排序等。
需要注意的是,聚合函数通常会生成单个结果值,并且如果没有GROUP BY子句,它们将作用于整个结果集。而在有GROUP BY子句的情况下,聚合函数将根据分组进行计算,生成每个组的聚合结果。
讯享网select id,count(*) from student group by id;
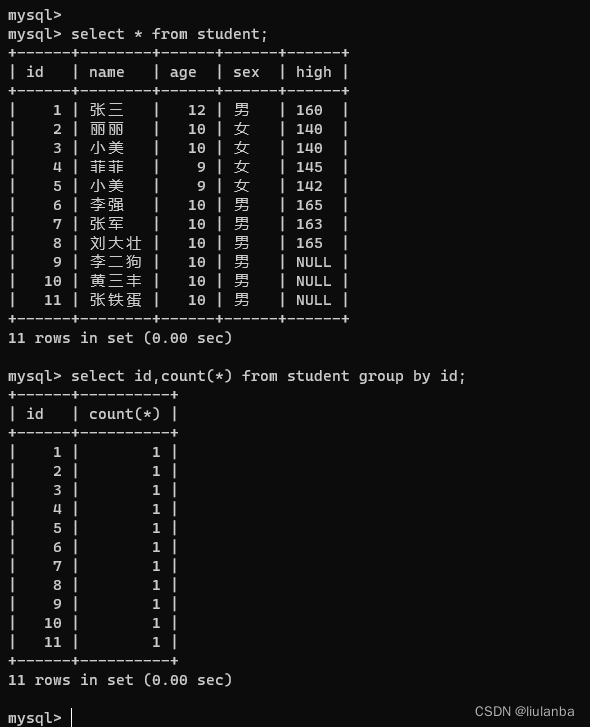
2.sum(列名) 统计这一列的总和
select sum(id) from student; 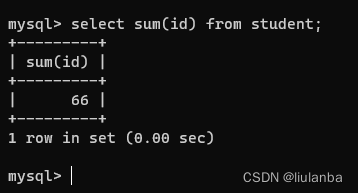
3.avg(列名) 统计这一列的平均值
讯享网 select avg(id) from student;
4.max(列名) 统计这一列的最大值
select max(id) from student; 5.min(列名) 统计这一列的最小值
讯享网 select min(id) from student;
ARRAY_AGG函数在MySQL 8.0版本中引入,对于需要将多个行的值合并为一个数组的情况非常有用。它常用于与GROUP BY子句一起使用,以便在分组的结果中生成聚合数组。
ARRAY_AGG(expression) 其中:
expression:要聚合为数组的表达式或列。
假设有一个名为orders的表,包含以下列:order_id、customer_id和product_name。我们希望按customer_id分组,并将每个客户的所有订单产品名称聚合到一个数组中。
讯享网SELECT customer_id, ARRAY_AGG(product_name) AS ordered_products FROM orders GROUP BY customer_id;
上面的查询将返回每个客户的customer_id和一个包含他们所有订单产品名称的数组。
需要注意的是,ARRAY_AGG函数只在MySQL 8.0及更高版本中可用。如果MySQL版本较旧,可能无法使用该函数。在较旧的版本中,可以考虑使用GROUP_CONCAT函数来实现类似的功能,它将多个值连接为一个字符串。
SELECT customer_id, GROUP_CONCAT(product_name SEPARATOR ',') AS ordered_products FROM orders GROUP BY customer_id; 上述查询将返回类似的结果,但是产品名称将以逗号分隔的字符串形式呈现。
六,多表查询
1. 查询的数据来自于多张表—— 表连接
表连接有三种情况:
内链接: inner join
外链接:
左外链接: left join 获取左表所有记录,即使右表没有对应匹配的记录,则为空
右外链接: right join 获取右表所有记录,即使左表没有对应匹配的记录,则为空
LEFT JOIN(或 LEFT OUTER JOIN):LEFT JOIN 返回左表中所有的行,以及右表中所有匹配的行。如果右表中没有匹配的行,则返回 NULL 值。
RIGHT JOIN(或 RIGHT OUTER JOIN):RIGHT JOIN 返回右表中所有的行,以及左表中所有匹配的行。如果左表中没有匹配的行,则返回 NULL 值。
FULL JOIN(或 FULL OUTER JOIN):FULL JOIN 返回左表和右表中的所有行,并将没有匹配的行设置为 NULL 值。

以下是在 MySQL 中使用 INNER JOIN 和 LEFT JOIN 的示例:
– INNER JOIN 示例
讯享网SELECT orders.order_id, customers.customer_name FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id;
– LEFT JOIN 示例
SELECT customers.customer_name, orders.order_id FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id; 在上面的示例中,第一个查询使用 INNER JOIN 将 orders 表和 customers 表组合在一起,并根据它们的 customer_id 列进行匹配。第二个查询使用 LEFT JOIN 将 customers 表和 orders 表组合在一起,并根据它们的 customer_id 列进行匹配,返回所有的 customers 表中的行和与之匹配的 orders 表中的行。如果没有匹配的行,则返回 NULL 值。
INNER JOIN 多表查询
讯享网SELECT orders.order_id, customers.customer_name, products.product_name FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id INNER JOIN products ON orders.product_id = products.product_id;
在上面的示例中,INNER JOIN 用于连接三个表:orders、customers 和 products。通过连接 customer_id 和 product_id 列,我们可以获取订单、顾客名称和产品名称的数据。
LEFT JOIN 多表查询
SELECT customers.customer_name, COUNT(orders.order_id) FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id GROUP BY customers.customer_name; 在上面的示例中,LEFT JOIN 用于连接 customers 和 orders 表。通过连接 customer_id 列,我们可以获取每个顾客名称以及他们的订单数量。由于使用了 LEFT JOIN,如果某个顾客没有订单,他们的订单数量将显示为零。
子查询多表查询
特征:一对 括号 把 查询语句给包起来了,一个查询语句里面 包含了另外一条或多条查询语句
讯享网SELECT orders.order_id, orders.order_date, customers.customer_name FROM orders INNER JOIN ( SELECT customer_id, MAX(order_date) AS latest_order FROM orders GROUP BY customer_id ) AS latest_orders ON orders.customer_id = latest_orders.customer_id AND orders.order_date = latest_orders.latest_order INNER JOIN customers ON orders.customer_id = customers.customer_id;
在上面的示例中,子查询用于获取每个顾客的最新订单日期。然后,INNER JOIN 用于连接 orders 表和 customers 表,并将订单日期与最新订单日期进行比较,以获取最新订单的订单号、订单日期和顾客名称。
2. 查询的条件来自于同一张表—— 子查询
SELECT子查询:子查询可以作为SELECT语句的一部分,用于在查询结果中生成一个或多个列。例如:
SELECT column1, column2, (SELECT COUNT(*) FROM table2) AS count FROM table1; 在这个例子中,子查询 (SELECT COUNT(*) FROM table2) 返回 table2 表中的行数,并将其作为别名 count 的列添加到外部查询的结果中。
FROM子查询:子查询可以作为FROM子句的一部分,用于在外部查询中引用一个虚拟表。例如:
讯享网SELECT * FROM (SELECT column1, column2 FROM table1) AS subquery;
在这个例子中,子查询 (SELECT column1, column2 FROM table1) 返回一个虚拟表,然后外部查询可以使用这个虚拟表进行进一步的操作。
WHERE子查询:子查询可以作为WHERE子句的一部分,用于根据子查询的结果过滤外部查询的行。例如:
SELECT column1, column2 FROM table1 WHERE column1 IN (SELECT column1 FROM table2); 在这个例子中,子查询 (SELECT column1 FROM table2) 返回一组值,然后外部查询根据这些值过滤出符合条件的行。
子查询使用当前过滤条件:
讯享网SELECT id, COUNT(*) AS xxx, max(SELECT song_title FROM online_song_onlinesongmodel AS o WHERE o.id = main.id) as bbb FROM online_song_onlinesongmodel AS main WHERE id LIKE '%3%' GROUP BY id;
在这个例子中,子查询SELECT song_title FROM online_song_onlinesongmodel AS o WHERE o.id = main.id使用外部变量作为过滤条件,使用 o.id = main.id作为匹配条件。
HAVING子查询:子查询可以作为HAVING子句的一部分,用于根据子查询的结果过滤外部查询的行(通常与GROUP BY一起使用)。例如:
SELECT column1, COUNT(*) FROM table1 GROUP BY column1 HAVING COUNT(*) > (SELECT AVG(count) FROM table2); 在这个例子中,子查询 (SELECT AVG(count) FROM table2) 返回一个平均值,然后外部查询根据这个平均值过滤出满足条件的行。
INSERT子查询:子查询可以作为INSERT语句的一部分,用于将子查询的结果插入到目标表中。例如:
讯享网INSERT INTO table1 (column1, column2) SELECT column1, column2 FROM table2;
在这个例子中,子查询 (SELECT column1, column2 FROM table2) 返回一组值,并将其插入到 table1 表的相应列中。
这些示例仅展示了子查询的一些常见用法。MySQL的子查询非常灵活,可以用于各种复杂的查询和操作。需要注意的是,子查询的性能可能受到影响,特别是在处理大量数据时。因此,在使用子查询时,需要注意优化查询,确保获得良好的性能。
七,索引
八,约束
SQL 约束用于规定表中的数据规则,如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)
CREATE TABLE table_name ( column_name1 data_type(size) constraint_name, column_name2 data_type(size) constraint_name, column_name3 data_type(size) constraint_name, .... ); 在 SQL 中,我们有如下约束:
主键约束(Primary Key Constraint):主键是用于标识表中每行记录的唯一标识符。主键可以是一个或多个列组成,用于唯一标识每一行。主键约束确保主键的值不为空并且唯一。
唯一约束(Unique Constraint):唯一约束确保一个或多个列中的每个值都是唯一的。与主键约束不同,唯一约束可以允许空值。
非空约束(Not Null Constraint):非空约束确保一个或多个列中的值不为空,即不允许 NULL 值。
外键约束(Foreign Key Constraint):外键约束用于定义两个表之间的关系。外键约束可以确保一个表中的数据与另一个表中的数据相匹配,通常用于建立表之间的关联关系。
检查约束(Check Constraint):检查约束用于定义列中允许的值的范围或条件。例如,可以使用检查约束确保一个列中的值不超过一定范围。
创建包含主键约束和外键约束的表的示例:
讯享网CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, FOREIGN KEY (customer_id) REFERENCES customers(customer_id) );
在上面的例子中,orders 表中的 order_id 列被定义为主键,customer_id 列定义为外键,关联到 customers 表中的 customer_id 列。
可以使用ALTER TABLE语句来给MySQL数据表添加约束,以下是一些常用的约束类型及其示例:
ALTER TABLE table_name ADD PRIMARY KEY (column_name); 其中,table_name是数据表名称,column_name是要设置为主键的列名。
讯享网ALTER TABLE table_name ADD UNIQUE (column_name);
其中,table_name是数据表名称,column_name是要设置为唯一的列名。
ALTER TABLE table_name ADD FOREIGN KEY (column_name) REFERENCES other_table_name (other_column_name); 其中,table_name是数据表名称,column_name是要设置为外键的列名,other_table_name是关联的其他表名称,other_column_name是在其他表中要匹配的列名。
索引和约束的区别
MySQL中的索引和约束是两个不同的概念,它们虽然都用于确保数据的完整性和提高查询性能,但是具有不同的作用和实现方式。
索引(Index):
索引是一种数据结构,用于快速查找表中的数据。它可以帮助数据库系统加快数据检索的速度,特别是在大型数据表中。
MySQL支持多种类型的索引,包括普通索引、唯一索引、主键索引、全文索引等。
在表中创建索引可以提高查询效率,但是索引也会占用额外的存储空间,并在数据更新时增加额外的开销。
约束(Constraint):
约束是一种规则,用于限制表中数据的值,以确保数据的完整性和一致性。它可以在插入或更新数据时自动执行检查。
MySQL支持多种类型的约束,包括主键约束、外键约束、唯一约束、默认约束、非空约束等。
约束可以确保表中数据的一致性和正确性,防止插入无效的数据,同时也可以在一定程度上提高数据的查询效率。
虽然索引和约束都可以提高数据库系统的性能和数据完整性,但是它们的作用和实现方式是不同的。索引主要用于加快数据检索的速度,而约束主要用于限制数据的值,确保数据的完整性。在实际应用中,通常会同时使用索引和约束来优化数据库设计和提高系统性能。
九,事务
MySQL 事务是一组操作的集合,这些操作被视为单个不可分割的工作单元,要么全部完成,要么全部不完成。事务通常用于保证数据库操作的一致性和完整性,并且在处理高并发数据操作时非常有用。
在 MySQL 中,事务具有以下四个特性,通常被称为 ACID 特性:
原子性(Atomicity):事务是一个不可分割的工作单元,事务中的所有操作要么全部完成,要么全部不完成。
一致性(Consistency):在事务开始和结束时,数据库必须保持一致状态。这意味着,在事务执行之前和之后,所有相关的数据必须满足所有预定义的规则。
隔离性(Isolation):每个事务必须与其他事务隔离,以避免数据损坏。隔离级别定义了多个事务可以访问数据库的方式。
持久性(Durability):一旦事务完成,它所做的更改必须永久保存在数据库中,并且不应该被回滚。
在 MySQL 中,可以使用 BEGIN、COMMIT 和 ROLLBACK 语句来控制事务。BEGIN 语句用于启动事务,COMMIT 语句用于提交事务,而 ROLLBACK 语句用于撤消事务。例如,以下是在 MySQL 中使用事务的示例:
讯享网BEGIN; -- 开始事务 UPDATE accounts SET balance = balance - 1000 WHERE id = 1; UPDATE accounts SET balance = balance + 1000 WHERE id = 2; COMMIT; -- 提交事务
在上面的示例中,BEGIN 语句用于启动事务,两个 UPDATE 语句用于更新 accounts 表中的记录,COMMIT 语句用于提交事务。如果其中一个 UPDATE 语句失败,可以使用 ROLLBACK 语句来撤消整个事务:
BEGIN; -- 开始事务 UPDATE accounts SET balance = balance - 1000 WHERE id = 1; UPDATE accounts SET balance = balance + 1000 WHERE id = 999; -- 无效的ID ROLLBACK; -- 撤消事务 COMMIT; 在上面的示例中,第二个 UPDATE 语句无效,因为没有 ID 为 999 的记录,所以 ROLLBACK 语句用于撤消整个事务
十,Filter语句
在MySQL中,FILTER子句是一种条件筛选机制,用于在聚合函数中对特定条件的行进行计算。它允许在聚合函数中使用条件表达式,以仅包括符合条件的行进行计算。FILTER子句在MySQL 8.0版本中引入,并且通常与聚合函数(如SUM、COUNT、AVG等)一起使用。
FILTER子句的基本语法:
讯享网SELECT aggregate_function(expression) FILTER (WHERE condition) AS alias FROM table GROUP BY column;
其中:
aggregate_function:聚合函数,如SUM、COUNT、AVG等。
expression:在聚合函数中使用的表达式。
condition:一个条件表达式,用于筛选要包含在聚合计算中的行。
alias:给计算结果指定的别名。
table:数据源表格。
column:用于分组的列。
通过FILTER (WHERE condition)子句,可以将条件应用于聚合函数的计算过程。只有满足条件的行才会被包括在聚合计算中,而不满足条件的行将被忽略。
下面是一个示例,说明如何使用FILTER子句来计算特定条件下的求和:
SELECT category, SUM(price) FILTER (WHERE quantity > 0) AS total_price FROM products GROUP BY category; 在上面的示例中,FILTER (WHERE quantity > 0)子句用于筛选quantity大于0的行,然后计算满足条件的行的price之和,并将结果用total_price别名表示。
请注意,FILTER子句在MySQL中是一种扩展语法,而在标准SQL中并不常见。因此,该语法可能不适用于其他数据库系统。
十一,WHERE 和HAVING
在 MySQL 中,WHERE 和 HAVING 是用于筛选数据的两个关键字。
以下是一个使用 WHERE 关键字的示例:
讯享网SELECT customer_name, city FROM customers WHERE city = 'New York';
在上面的示例中,WHERE 关键字用于筛选出位于纽约市的顾客,并返回其名称和所在城市。
以下是一个使用 HAVING 关键字的示例:
SELECT customer_id, COUNT(order_id) FROM orders GROUP BY customer_id HAVING COUNT(order_id) > 2; 在上面的示例中,GROUP BY 关键字用于按顾客 ID 进行分组,并计算每个顾客的订单数量。然后,HAVING 关键字用于筛选出订单数量大于 2 的顾客。请注意,HAVING 关键字只能用于聚合函数(如 COUNT、SUM、AVG、MIN 和 MAX)所返回的数据。
总之,WHERE 和 HAVING 关键字都是用于筛选数据的关键字,但 WHERE 关键字用于筛选行,而 HAVING 关键字用于筛选分组数据。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/47122.html