
pyppetter的基本操作
准备阶段
先安装 pyppeteer库
导入的名称同库名
查看浏览器版本
pyppeteer.__chromium_revision__ 讯享网
查看浏览器存储路径
讯享网pyppeteer.executablePath()
简单示例
from pyppeteer import launch import asyncio async def main(): browser =await launch(headless=False, args=['--disable-infobars']) page=await browser.newPage() await page.setViewport({
'width': 1200, 'height': 800}) await page.goto("http://www.baidu.com/") asyncio.get_event_loop().run_until_complete(main()) launch的英文释义是发射,这里是 指的启动个浏览器,这个函数是个异步函数,所以必须await ,不然是会报错的
启动一个新的 选项卡页面
讯享网page=await browser.newPage()
启动一个新的页面
调整页面尺寸
await page.setViewport({'width': 1200, 'height': 800}) 使页面的尺寸变为1200*800
前往一个页面
讯享网await page.goto("http://www.baidu.com/")
前往这个页面
第一次启动还会下载浏览器,不是什么问题

获取输入框并加入文字
await page.type('#kw','pyppeteer') type函数,第一个参数以选择器筛选,第二个是输入的文字
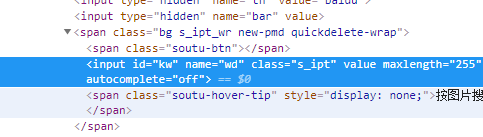
这里选择id为kw的输入框,加入文字pyppeteer
实现点击
讯享网 await page.click('#su')
点击这个选择器,实现点击百度一下

添加浏览器用户代理
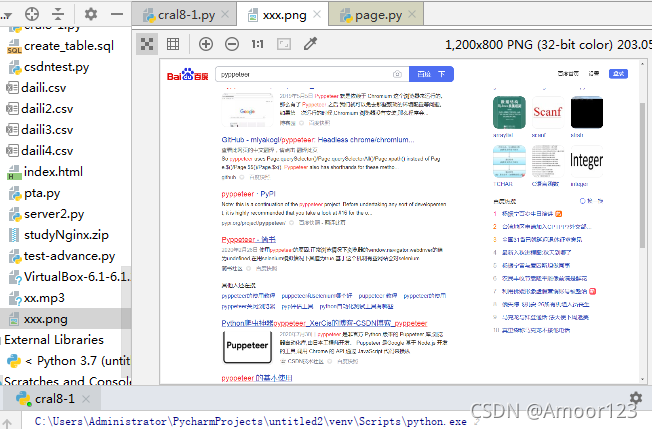
await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML,\ like Gecko) Chrome/19.0.1084.36 Safari/536.5") 给浏览器截图
讯享网 await page.screenshot(path='xxx.png')
截图受到窗口的影响,图像 的尺寸正好是上面设定的窗口大小
关闭浏览器
await browser.close() 关闭浏览器,不关闭运行完自己也会 关闭,这是loop指定的run_until_complete()
运行这个程序
讯享网asyncio.get_event_loop().run_until_complete(main())
因为这个异步必须在函数里,所以将上面的功能封装在一个main函数,再循环,直到任务完成
模拟JS操作
绕过浏览器webdriver检测
实际是设置navigator.webdriver的值为undefined,未定义,或者为false
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,' '{ webdriver:{ get: () => undefined } })}') 返回cookie
写个JS函数返回cookie
讯享网 dimensions = await page.evaluate(''' () => { return { cookie: window.document.cookie, } }''') print(dimensions, type(dimensions))

滚动到页面底部
await page.evaluate('window.scrollBy(0, document.body.scrollHeight)') 解析页面
CSS选择器
用经常访问的网页 做示例
讯享网async def main(): browser =await launch(headless=False, args=['--disable-infobars']) page=await browser.newPage() await page.setViewport({
'width': 1200, 'height': 800}) await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML,\ like Gecko) Chrome/19.0.1084.36 Safari/536.5") await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,' '{ webdriver:{ get: () => undefined } })}') await page.goto('https://pic.netbian.com/4kmeinv/') xx=await page.querySelectorAll('.clearfix li a img') print(xx) for i in xx: print(await (await i.getProperty('src')).jsonValue()) time.sleep(3) input()#等待,避免直接被关闭 await browser.close() asyncio.get_event_loop().run_until_complete(main())
有querySelector和querySelectorAll两个函数
前一个取第一个,后一个取所有
示例取这个网页的所有 class为 clearfix下的 标签li下的标签a 下的img
await (await i.getProperty(‘src’)).jsonValue()是遍历这个集合提取src属性并提取jsonValue
不提取值也是一个对象,提取后是个 链接

xpath提取
其余 代码同上
xx=await page.xpath('//*[@id="main"]/div[3]/ul/li/a/img') print(xx) for i in xx: print(await (await i.getProperty('src')).jsonValue()) 三个函数的缩写名称
querySelector和querySelectorAll两个函数分别为page.J()和 page.JJ(),xpath则是 page.Jx()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/44633.html