
LR
▐ 算法原理
逻辑回归LR(Logistic Regression)模型作为经典的机器学习分类模型,以其可解释性强、实现简单、线上高效等优点在线上应用中被大量使用。逻辑回归模型主要有两部分构成:
- 线性回归
- 逻辑函数
在机器学习中,线性回归模型可记为:
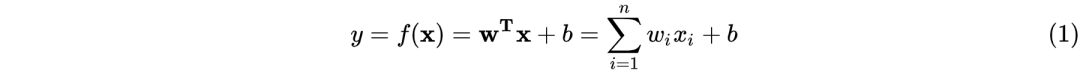
而逻辑函数使用的为sigmoid函数:
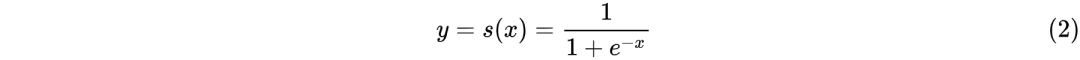
由(1)和(2)可推出LR模型的数学表达式为
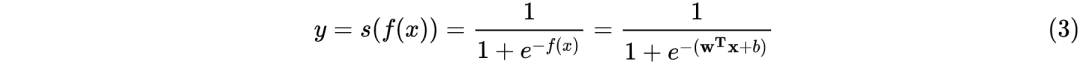
在线性回归模型(1)中,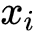 是具体的某一个特征值,
是具体的某一个特征值,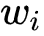 是该特征值的权重,是模型的输出。该公式可以直白的解释为模型的输出结果是由输入进行线性加权求和得到的。而逻辑函数(2)的作用是将线性回归模型的输出映射到[0,1],输出一个概率值。商品推荐的场景中如用户对某个item进行点击记为1,未点击记为0。
是该特征值的权重,是模型的输出。该公式可以直白的解释为模型的输出结果是由输入进行线性加权求和得到的。而逻辑函数(2)的作用是将线性回归模型的输出映射到[0,1],输出一个概率值。商品推荐的场景中如用户对某个item进行点击记为1,未点击记为0。
▐ 解决的问题
LR是一个基本的回归模型,可以对输入进行一些线性运算得到一个预测的输出值。预测值可以是用户点击某个商品的概率,也可以是用户下单的概率,其含义具体业务具体分析。
FM
▐ 算法原理
FM(Factorization Machine)。LR作为一个基础的回归模型,主要原理是通过对各个特征进行线性加权得到预测值,但是其并没有考虑组合特征对模型的影响,比如一名单身女性在晚上观看李佳琦直播概率显然是大于一名妈妈的,这里面包含的组合特征单身女性-晚上在LR中就体现不到。因此相比LR仅对一阶特征进行建模,FM引入了二阶特征,增强了模型的学习能力和表达能力。
FM的数学表达式如下:
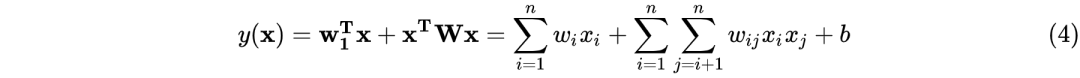
如果FM仅仅是在模型的表达式上加入了二阶特征,它的应用绝不会这么广泛,只从式(4)中就可以看出表达式上其实相对于LR的改进是很简单的:在模型中引入输入特征两两组合进行乘积就行了。但是这样会引入一个很大的问题:参数的数目直接从个爆炸增长为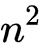 个,这对于特征维度动辄上千上万数量级的推荐系统来说是断然不能接受的。
个,这对于特征维度动辄上千上万数量级的推荐系统来说是断然不能接受的。
面对这么大的参数矩阵很容易想到将其进行矩阵分解,我们首先观察一下参数矩阵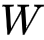
可以看到参数矩阵 是实对称矩阵,可以想到正定矩阵是可以很优雅的进行分解的:
是实对称矩阵,可以想到正定矩阵是可以很优雅的进行分解的:
特别地,在稀疏矩阵中 的情况下,便可满足式(6)的近似相等。
的情况下,便可满足式(6)的近似相等。
设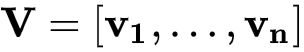 ,则式(4)中的模型参数可表示为
,则式(4)中的模型参数可表示为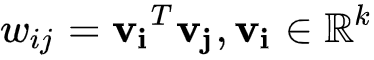 。
。
因此限定参数矩阵为正定矩阵的情况下,FM的二阶特征的表达式可推导如下:
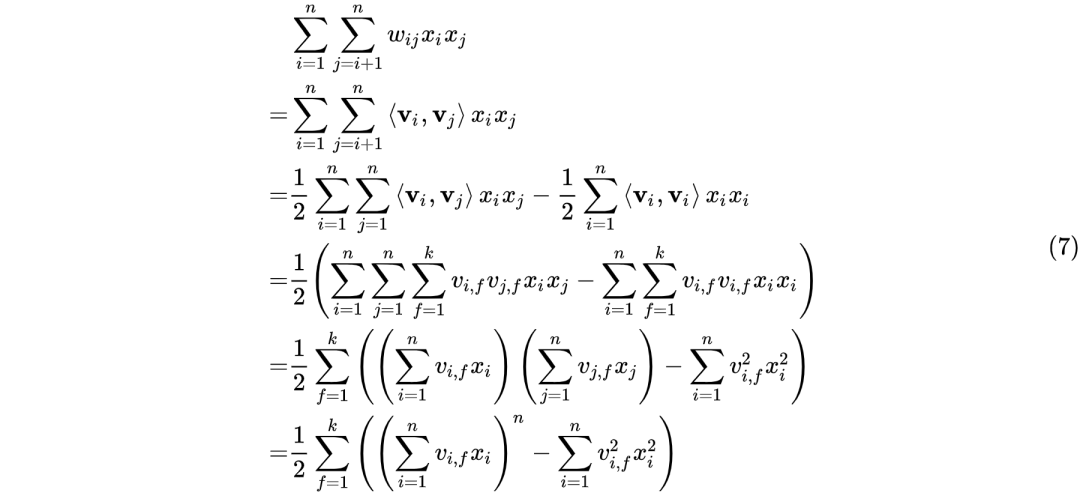
对比式(6)和式(7)可知,FM的计算复杂度由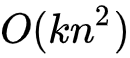 降至
降至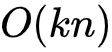 ,而k的值又是一个可根据业务情况硬编码的值,式(7)的推导使得FM的时间复杂度降至线性复杂度,无论是对于模型的离线训练还是在线推理均使得二阶特征组合成为可能。
,而k的值又是一个可根据业务情况硬编码的值,式(7)的推导使得FM的时间复杂度降至线性复杂度,无论是对于模型的离线训练还是在线推理均使得二阶特征组合成为可能。
▐ 解决的问题
FM通过引入二阶特征实现了模型学习能力及表达能力的提升,并且利用正定矩阵和稀疏矩阵的性质将二阶特征的计算降低至线性复杂度,也因此成为工业界常用的特征工程算法。
FFM
▐ 算法原理
FFM(Field-aware Factorization Machine)。从名字上看,相较于FM, FFM多了一个F,在实现上也是如此。
FFM的数学表达式如下:
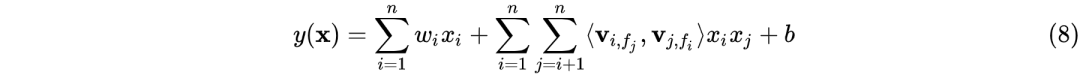
从式(8)可以看出FFM相比于FM的不同点在于二阶特征组合的系数上,FFM的权重矩阵比FM多了一维。其算法思想是这样的:以前言中的商品推荐的训练数据举例,在进行one-hot编码时,我们将不同的字段的特征进行编码然后拉平送进模型进行训来,比如字段天猫会员等级T1和天猫会员等级T3这俩字段被独立为两个独立的特征。然而实际情况却是这俩字段其实是对同一个字段天猫会员等级的不同描述。因此在FFM中引入了field的概念:每一维的特征都有对应的field,在进行二阶特征组合时某一维特征对于不同field的特征其所对应的隐向量是不同的。假设所有特征共包含f个filed,则FFM权重矩阵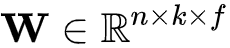 ,相比于FM的权重矩阵
,相比于FM的权重矩阵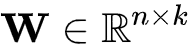 ,多出的
,多出的 维便对应着FFM中引入的field的数目。
维便对应着FFM中引入的field的数目。
需要说明的是,FM可以看做是FFM的特例:所有特征属于同一个field。
▐ 解决的问题
引入field更精准刻画了各维特征之间的关系,通过增大隐向量的数目增强了模型的表达能力。但是由于其隐向量与field有关,其相关计算无法像FM那样化简,在面对特征维度n比较大的情况下,其计算性能容易成为系统瓶颈。
WDL
▐ 算法原理
WDL(Wide & Deep Learning)。其核心思想是结合线性模型(如上文的LR)的记忆能力和DNN模型的泛化能力来提升模型的整体能力。
其网络结构图如下:
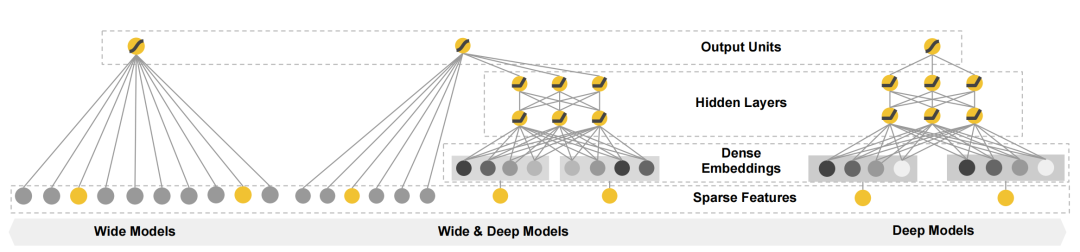
其中包括

- wide部分:wide部分是普通的线性模型,其表达式可参见式(1)
- deep部分:deep部分由一个3层的神经网络组成。其输入是对原始的稀疏特征(如ID类特征)进行一次embedding后的结果。每一层的公式如下:
- 输出:输出部分将线性模型(Wide)和DNN(Deep)模型的输出结果进行加和作为整个模型的loss进行反向传播来完成联合训练。


▐ 解决的问题
结合了线性模型对一阶特征和和深度模型对高阶特征的学习能力来整体提高模型的表达能力。
DeepFM
▐ 算法原理
WDL可以看做是LR+DNN,那么DeepFM就可以看做是FM+DNN。相比于WDL做出的改进,DeepFM主要是将WDL中Wide模块由LR替换为了FM。
其网络结构如图所示:
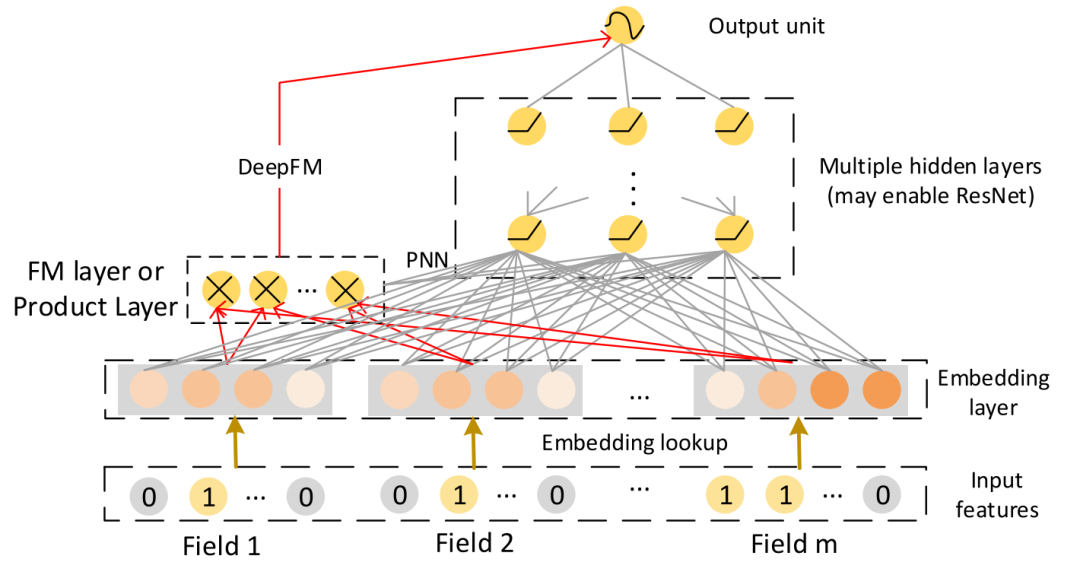
可以看到相对于WDL其做了以下改进:
- 引入FM结构代替LR。完成对一阶二阶特征的学习 避免了WDL中人工特征工程过程。见式(4)。
- FM和DNN共享Embedding层。减少了额外的计算开销。
▐ 解决的问题
在减去人工特征工程的前提下,通过Wide部分和Deep部分共享Embedding,可以提高模型的训练速度和模型的特征学习能力。
DcN
▐ 算法原理
DCN(Deep & Cross Network)如其名字中cross所示,其主要完成了完全去手工特征交叉的工作。
其中代替DeepFM中FM模块的核心Cross Network网络结构如下:
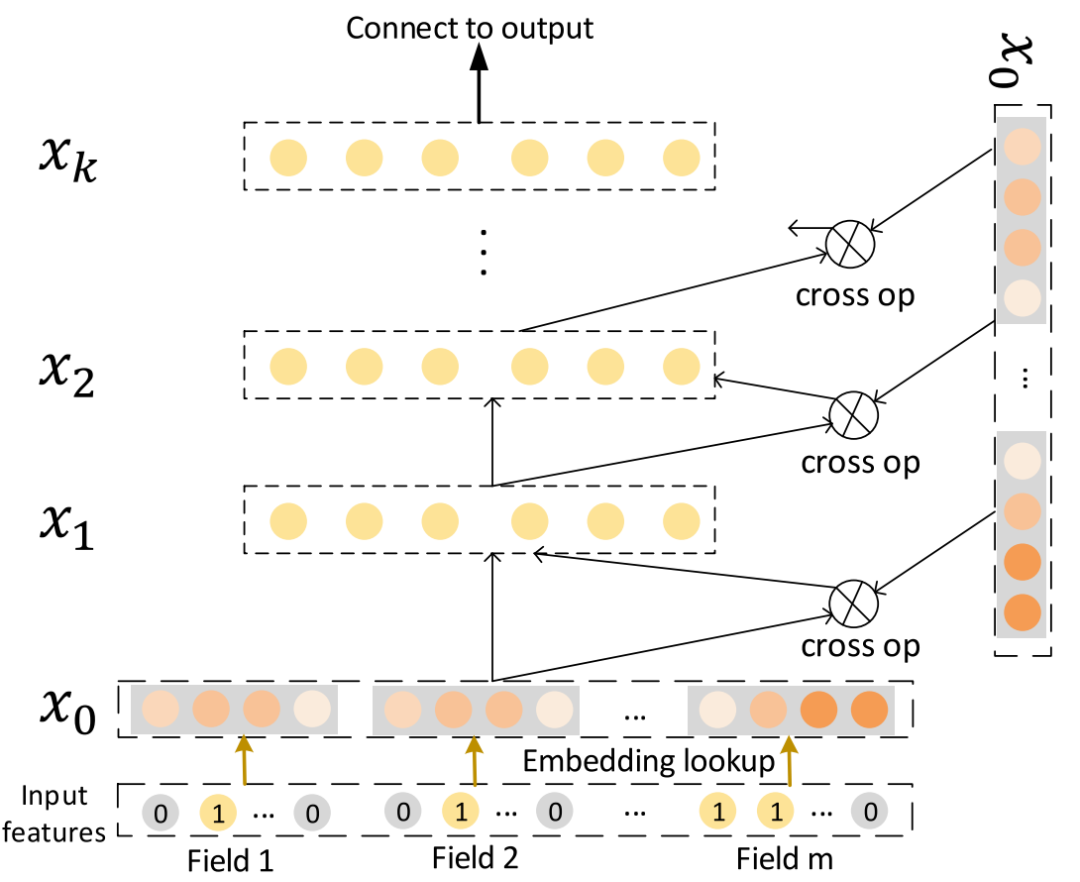
其中:
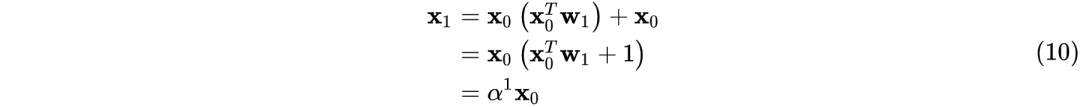
进而可推出
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)

最后
Java架构进阶面试及知识点文档笔记
这份文档共498页,其中包括Java集合,并发编程,JVM,Dubbo,Redis,Spring全家桶,MySQL,Kafka等面试解析及知识点整理

Java分布式高级面试问题解析文档
其中都是包括分布式的面试问题解析,内容有分布式消息队列,Redis缓存,分库分表,微服务架构,分布式高可用,读写分离等等!

互联网Java程序员面试必备问题解析及文档学习笔记

Java架构进阶视频解析合集
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

息队列,Redis缓存,分库分表,微服务架构,分布式高可用,读写分离等等!
[外链图片转存中…(img-4vHlkQpx-99)]
互联网Java程序员面试必备问题解析及文档学习笔记
[外链图片转存中…(img-Y5vHfNXM-99)]
Java架构进阶视频解析合集
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-p2c0hADv-99)]
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/42696.html