
一、数据集相关代码解读
创建dataloader(damo/dataset/build.py)
在damo/apis/detector_trainer.py的158行,及174-203行中,DAMO-YOLO分别对train_dataloader和val_dataloader进行了创建,并进行了iters_per_epoch的计算,用于后续Iters-based的模型训练。
# dataloader self.train_loader, self.val_loader, iters = self.get_data_loader(cfg)讯享网
build_dataset函数创建数据集类,若为训练模式,且mosaic_mixup为True时,则会使用MosaicWrapper对dataset类进行封装。
讯享网 def get_data_loader(self, cfg): train_dataset = build_dataset( cfg, cfg.dataset.train_ann, is_train=True, mosaic_mixup=cfg.train.augment.mosaic_mixup) val_dataset = build_dataset(cfg, cfg.dataset.val_ann, is_train=False) iters_per_epoch = math.ceil( len(train_dataset[0]) / cfg.train.batch_size) # train_dataset is a list, however,
创建完dataset类后,即可创建dataloader对数据集进行读取。在dataloader创建函数中,作者基于config提供的batch_size、augmentations、total_epochs、num_workers进行相关超参设置。
train_loader = build_dataloader(train_dataset, cfg.train.augment, batch_size=cfg.train.batch_size, start_epoch=self.start_epoch, total_epochs=cfg.train.total_epochs, num_workers=cfg.miscs.num_workers, is_train=True, size_div=32) val_loader = build_dataloader(val_dataset, cfg.test.augment, batch_size=cfg.test.batch_size, num_workers=cfg.miscs.num_workers, is_train=False, size_div=32) return train_loader, val_loader, iters_per_epoch创建COCO数据集(damo/dataset/datasets/coco.py)
__init__解读
COCODataset继承于pycocotools库的CocoDetection类。将json标注中的类别id和连续id进行相互映射,保存在json_category_id_to_contiguous_id和contiguous_category_id_to_json_id两个字典里面。
讯享网class COCODataset(CocoDetection): def __init__(self, ann_file, root, transforms=None): super(COCODataset, self).__init__(root, ann_file) # sort indices for reproducible results self.ids = sorted(self.ids) self.json_category_id_to_contiguous_id = { v: i + 1 for i, v in enumerate(self.coco.getCatIds()) } self.contiguous_category_id_to_json_id = { v: k for k, v in self.json_category_id_to_contiguous_id.items() } self.id_to_img_map = {k: v for k, v in enumerate(self.ids)} self._transforms = transforms
__getitem__解读
该函数在damo/apis/detector_trainer.py中的271行enumerate(self.train_loader)中被调用。
def __getitem__(self, inp): if type(inp) is tuple: idx = inp[1] else: idx = inp img, anno = super(COCODataset, self).__getitem__(idx)从json文件中读出标注框、类别、keypoints等信息,对标注框及iscrowd标签的类别进行过滤。
讯享网 # filter crowd annotations # TODO might be better to add an extra field anno = [obj for obj in anno if obj['iscrowd'] == 0] boxes = [obj['bbox'] for obj in anno] boxes = torch.as_tensor(boxes).reshape(-1, 4) # guard against no boxes target = BoxList(boxes, img.size, mode='xywh').convert('xyxy') classes = [obj['category_id'] for obj in anno] classes = [self.json_category_id_to_contiguous_id[c] for c in classes] classes = torch.tensor(classes) target.add_field('labels', classes) if anno and 'keypoints' in anno[0]: keypoints = [obj['keypoints'] for obj in anno] target.add_field('keypoints', keypoints) target = target.clip_to_image(remove_empty=True)
作者将图像从PIL格式转为numpy格式,之后进行通用的数据增强处理,返回图像、标注、图像id。
# PIL to numpy array img = np.asarray(img) # rgb if self._transforms is not None: img, target = self._transforms(img, target) return img, target, idxpull_item解读
pull_item函数主要用于mosaic增强时,读取额外的三张图像。读数据的流程__getitem__基本一致。
讯享网 def pull_item(self, idx): img, anno = super(COCODataset, self).__getitem__(idx) # filter crowd annotations # TODO might be better to add an extra field anno = [obj for obj in anno if obj['iscrowd'] == 0] boxes = [obj['bbox'] for obj in anno] boxes = torch.as_tensor(boxes).reshape(-1, 4) # guard against no boxes target = BoxList(boxes, img.size, mode='xywh').convert('xyxy') target = target.clip_to_image(remove_empty=True) classes = [obj['category_id'] for obj in anno] classes = [self.json_category_id_to_contiguous_id[c] for c in classes]
区别在于pull_item中,若标注中存在segmentation信息,作者将会读出用于进行框的refine.
obj_masks = [] for obj in anno: obj_mask = [] if 'segmentation' in obj: for mask in obj['segmentation']: obj_mask += mask if len(obj_mask) > 0: obj_masks.append(obj_mask) seg_masks = [ np.array(obj_mask, dtype=np.float32).reshape(-1, 2) for obj_mask in obj_masks ] res = np.zeros((len(target.bbox), 5)) for idx in range(len(target.bbox)): res[idx, 0:4] = target.bbox[idx] res[idx, 4] = classes[idx]另外的区别为,作者在Mosaic图进行拼接完成后再去做augmentation,因此,pull_item函数中不包含augmentation操作,将image从PIL转为numpy格式后直接返回。
讯享网 img = np.asarray(img) # rgb return img, res, seg_masks, idx
使用MosaicWrapper对CocoDataset封装,进行Mosaic、Mixup数据增强(damo/dataset/datasets/mosaic_wrapper.py)
__init__解读
在初始化过程中,会传入待封装的dataset类、输入尺度input_dim、数据增强方式transforms及(degree, scale, shear)等各种超参。
class MosaicWrapper(torch.utils.data.dataset.Dataset): """Detection dataset wrapper that performs mixup for normal dataset.""" def __init__(self, dataset, img_size, mosaic_prob=1.0, mixup_prob=1.0, transforms=None, degrees=10.0, translate=0.1, mosaic_scale=(0.1, 2.0), mixup_scale=(0.5, 1.5), shear=2.0, *args): super().__init__() self._dataset = dataset self.input_dim = img_size self._transforms = transforms self.degrees = degrees self.translate = translate self.scale = mosaic_scale self.shear = shear self.mixup_scale = mixup_scale self.mosaic_prob = mosaic_prob self.mixup_prob = mixup_prob self.local_rank = get_rank()__getitem__解读
若训练时mosaic_mixup为True且使用MosaicWrapper封装了dataset,则damo/apis/detector_trainer.py中的271行enumerate(self.train_loader)将调用这个函数。

首先读出第一张图像作为基础图像。
讯享网def __getitem__(self, inp): if type(inp) is tuple: enable_mosaic_mixup = inp[0] idx = inp[1] else: enable_mosaic_mixup = False idx = inp img, labels, segments, img_id = self._dataset.pull_item(idx)
若使用Mosaic数据增强,则基于random.randint随机选出三张其他的图像,将它们拼接为一张大图。四张图分别放在左上、右上、左下、右下四个位置。
if enable_mosaic_mixup: if random.random() < self.mosaic_prob: mosaic_labels = [] mosaic_segments = [] input_h, input_w = self.input_dim[0], self.input_dim[1] yc = int(random.uniform(0.5 * input_h, 1.5 * input_h)) xc = int(random.uniform(0.5 * input_w, 1.5 * input_w)) # 3 additional image indices indices = [idx] + [ random.randint(0, len(self._dataset) - 1) for _ in range(3) ] for i_mosaic, index in enumerate(indices): img, _labels, _segments, img_id = self._dataset.pull_item( index) h0, w0 = img.shape[:2] # orig hw scale = min(1. * input_h / h0, 1. * input_w / w0) img = cv2.resize(img, (int(w0 * scale), int(h0 * scale)), interpolation=cv2.INTER_LINEAR) # generate output mosaic image (h, w, c) = img.shape[:3] if i_mosaic == 0: mosaic_img = np.full((input_h * 2, input_w * 2, c), 114, dtype=np.uint8) # pad 114 (l_x1, l_y1, l_x2, l_y2), (s_x1, s_y1, s_x2, s_y2) = get_mosaic_coordinate( mosaic_img, i_mosaic, xc, yc, w, h, input_h, input_w) mosaic_img[l_y1:l_y2, l_x1:l_x2] = img[s_y1:s_y2, s_x1:s_x2] padw, padh = l_x1 - s_x1, l_y1 - s_y1标签也进行相应的平移及尺度变换,同时若标注时有分割信息,则利用分割的标注信息对框进行再次校正。
讯享网 labels = _labels.copy() # Normalized xywh to pixel xyxy format if _labels.size > 0: labels[:, 0] = scale * _labels[:, 0] + padw labels[:, 1] = scale * _labels[:, 1] + padh labels[:, 2] = scale * _labels[:, 2] + padw labels[:, 3] = scale * _labels[:, 3] + padh segments = [ xyn2xy(x, scale, padw, padh) for x in _segments ] mosaic_segments.extend(segments) mosaic_labels.append(labels) if len(mosaic_labels): mosaic_labels = np.concatenate(mosaic_labels, 0) np.clip(mosaic_labels[:, 0], 0, 2 * input_w, out=mosaic_labels[:, 0]) np.clip(mosaic_labels[:, 1], 0, 2 * input_h, out=mosaic_labels[:, 1]) np.clip(mosaic_labels[:, 2], 0, 2 * input_w, out=mosaic_labels[:, 2]) np.clip(mosaic_labels[:, 3], 0, 2 * input_h, out=mosaic_labels[:, 3]) if len(mosaic_segments): assert input_w == input_h for x in mosaic_segments: np.clip(x, 0, 2 * input_w, out=x) # clip when using random_perspective()
之后对图像及标注框进行平移、缩放等仿射变换变化。
img, labels = random_affine( mosaic_img, mosaic_labels, mosaic_segments, target_size=(input_w, input_h), degrees=self.degrees, translate=self.translate, scales=self.scale, shear=self.shear, )若mixup_prob不为0且random.random()<mixup_prob,则对图像再次进行mixup数据增强。
讯享网 # ----------------------------------------------------------------- # CopyPaste: https://arxiv.org/abs/2012.07177 # ----------------------------------------------------------------- if (not len(labels) == 0 and random.random() < self.mixup_prob): img, labels = self.mixup(img, labels, self.input_dim)
将标注转为BoxList格式后,进行通用数据增强,最后返回图像、标注、图像id。
# transfer labels to BoxList h_tmp, w_tmp = img.shape[:2] boxes = [label[:4] for label in labels] boxes = torch.as_tensor(boxes).reshape(-1, 4) areas = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0]) valid_idx = areas > 4 target = BoxList(boxes[valid_idx], (w_tmp, h_tmp), mode='xyxy') classes = [label[4] for label in labels] classes = torch.tensor(classes)[valid_idx] target.add_field('labels', classes.long()) if self._transforms is not None: img, target = self._transforms(img, target) # ----------------------------------------------------------------- # img_info and img_id are not used for training. # They are also hard to be specified on a mosaic image. # ----------------------------------------------------------------- return img, target, img_id将图像封装为ImageList(damo/structures/image_list.py)
在damo/dataset/collate_batch.py中的第16行以及damo/detectors/detector.py中的第54行,to_image_list(x)会将输入的tensor封装为ImageList,并Padding到size_divisible的整数倍。
讯享网 elif isinstance(tensors, (tuple, list)): if max_size is None: max_size = tuple( max(s) for s in zip(*[img.shape for img in tensors])) if size_divisible > 0: import math stride = size_divisible max_size = list(max_size) max_size[1] = int(math.ceil(max_size[1] / stride) * stride) max_size[2] = int(math.ceil(max_size[2] / stride) * stride) max_size = tuple(max_size) batch_shape = (len(tensors), ) + max_size batched_imgs = tensors[0].new(*batch_shape).zero_() # + 114 for img, pad_img in zip(tensors, batched_imgs): pad_img[:img.shape[0], :img.shape[1], :img.shape[2]].copy_(img) image_sizes = [im.shape[-2:] for im in tensors] pad_sizes = [batched_imgs.shape[-2:] for im in batched_imgs] return ImageList(batched_imgs, image_sizes, pad_sizes) else: raise TypeError('Unsupported type for to_image_list: {}'.format( type(tensors)))
二、模型构建代码解读
detector代码解读(damo/detectors/detector.py)
__init__解读
在damo/apis/detector_trainer.py的115行执行build_local_model(self.cfg, self.device)进行模型构建,detector类作为入口,会在init中会将backbone、neck、head按照config的配置进行结构初始化。
def __init__(self, config): super().__init__() self.backbone = build_backbone(config.model.backbone) self.neck = build_neck(config.model.neck) self.head = build_head(config.model.head) self.config = configforward解读
在damo/apis/detector_trainer.py的第285行和第300行,模型进行前向推理,会调用forward函数。forward函数内包含蒸馏训练和普通训练两个分支。若tea为True,则为老师模型的前向推理,直接返回neck的特征。若stu为true,则开启了蒸馏训练,除了返回Head的输出外,还返回neck的输出用于特征蒸馏。
讯享网 def forward(self, x, targets=None, tea=False, stu=False): images = to_image_list(x) feature_outs = self.backbone(images.tensors) # list of tensor fpn_outs = self.neck(feature_outs) if tea: return fpn_outs else: outputs = self.head( fpn_outs, targets, imgs=images, ) if stu: return outputs, fpn_outs else: return outputs 模型结构代码(damo/base_models/backbones/, necks/, heads/) 模型结构部分直接参考论文的示意图会更加清晰。 MAE-NAS构建部分,直接参考官方给出的NAS教程:https://github.com/alibaba/lightweight-neural-architecture-search/blob/main/scripts/damo-yolo/Tutorial_NAS_for_DAMO-YOLO_cn.md 三、loss计算模块(damo/base_models/losses/) loss在damo/base_models/heads/zero_head.py的111-115行被定义,包括DistributionFocalLoss、QualityFocalLoss以及GIOULoss。 self.loss_dfl = DistributionFocalLoss(loss_weight=0.25) self.loss_cls = QualityFocalLoss(use_sigmoid=False, beta=2.0, loss_weight=1.0) self.loss_bbox = GIoULoss(loss_weight=2.0) 在zero_head.py的375-400行,loss计算被调用。 loss_qfl为魔改版的Focal Loss,从实现上能看到,依然还是保留分类的向量,但是对应类别位置的置信度的物理含义不再是分类的score,而是改为质量预测的score。 loss_dfl以类似交叉熵的形式去优化与标签 y 最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去。 loss_bbox以常用的GIOU进行loss计算。 最后三者loss相加作为总的Loss返回,进行反向传播。 loss_qfl = self.loss_cls(cls_scores, (labels, label_scores), avg_factor=num_total_pos) pos_inds = torch.nonzero((labels >= 0) & (labels < self.num_classes), as_tuple=False).squeeze(1) weight_targets = cls_scores.detach() weight_targets = weight_targets.max(dim=1)[0][pos_inds] norm_factor = max(reduce_mean(weight_targets.sum()).item(), 1.0) if len(pos_inds) > 0: loss_bbox = self.loss_bbox( decoded_bboxes[pos_inds], bbox_targets[pos_inds], weight=weight_targets, avg_factor=1.0 * norm_factor, ) loss_dfl = self.loss_dfl( bbox_before_softmax[pos_inds].reshape(-1, self.reg_max + 1), dfl_targets[pos_inds].reshape(-1), weight=weight_targets[:, None].expand(-1, 4).reshape(-1), avg_factor=4.0 * norm_factor, ) else: loss_bbox = bbox_preds.sum() / norm_factor * 0.0 loss_dfl = bbox_preds.sum() / norm_factor * 0.0 logger.info(f'No Positive Samples on {bbox_preds.device}! May cause performance decrease. loss_bbox:{loss_bbox:.3f}, loss_dfl:{loss_dfl:.3f}, loss_qfl:{loss_qfl:.3f} ') total_loss = loss_qfl + loss_bbox + loss_dfl
四、DAMO-YOLO实操
按照官网给的安装教程在我的Linux环境安装好以后,一条命令就把DAMO-YOLO训练起来啦。
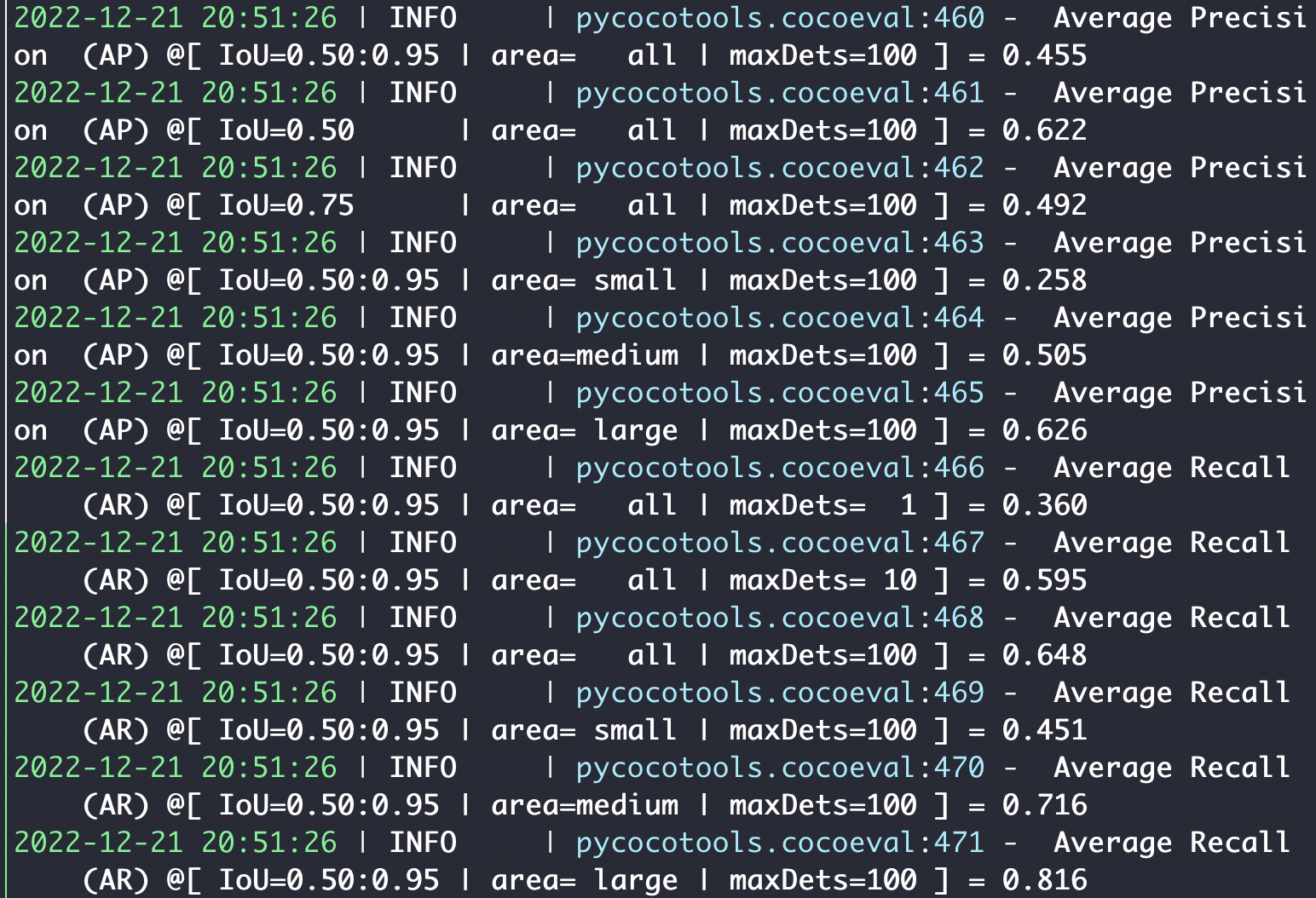
python -m torch.distributed.launch --nproc_per_node=8 tools/train.py -f configs/damoyolo_tinynasL25_S.py我使用的是v100 16G的机器,花了一天半时间完成了S的训练。跑的是非蒸馏的训练版本,精度和文章汇报的差不多。总的来说还是一个非常不错的工作,期待这个工作的持续更新。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/42278.html